
I still remember the first time I seriously looked into OpenLedger.
Not from a viral thread. Not because somebody was shilling the token. And honestly not even because of the funding headlines everyone was posting about.
It happened during one of those late-night research sessions where you open ten tabs thinking you’ll spend fifteen minutes reading, then suddenly realize it’s almost morning.
At that time, every AI project in crypto was starting to sound identical.
“Revolutionary AI.” “Next-generation intelligence.” “Decentralized future.”
Same buzzwords everywhere.
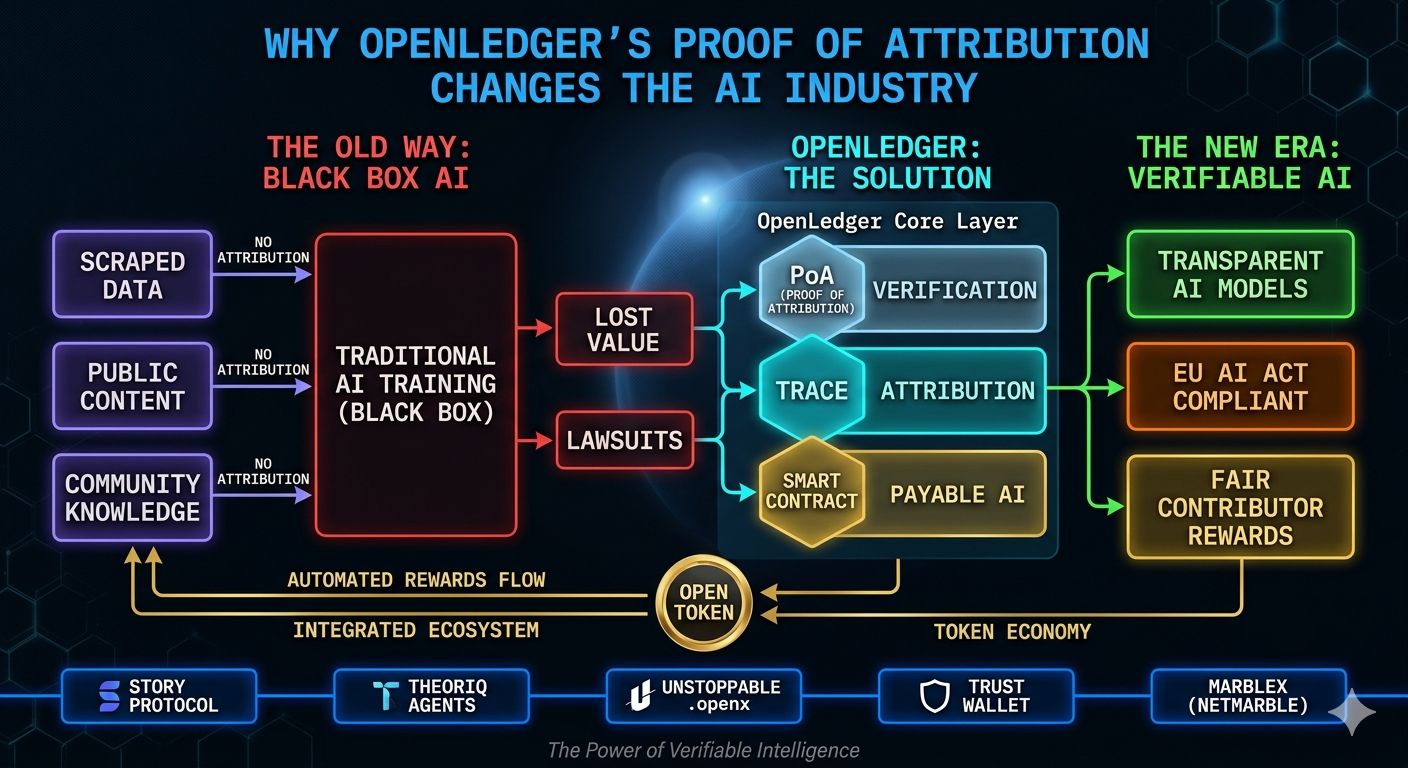
But when I started reading about OpenLedger’s Proof of Attribution model, I paused for a second because the idea behind it was solving a problem most people in AI still avoid talking about directly.
Where exactly is all this AI knowledge coming from?
That question sounds simple, but it’s becoming one of the biggest issues in the entire industry.
Right now, the modern AI economy runs on massive amounts of scraped data, collected information, public content, community-generated material, and training sets pulled from countless sources across the internet.
But almost nobody truly knows how those datasets are being tracked.
No clear transparency. No proper attribution. No public accountability.
People use AI products every day without realizing how little visibility exists behind the training process itself.
Even regulators are struggling to keep up.
You can already see the pressure building globally through copyright lawsuits, publishing disputes, and growing concerns around unauthorized data usage. Governments are starting to realize that AI cannot keep scaling forever inside a system where nobody can verify where the intelligence originally came from.
That is where OpenLedger started feeling different to me.
Instead of treating data like invisible fuel that disappears after training, OpenLedger treats it like an active economic layer.
Every dataset can be registered. Training activity can be logged. Inference usage can be traced back through the system itself.
And honestly, the deeper implication here is massive.
Because for the first time, contributors are no longer invisible.
If someone provides valuable datasets that improve AI performance, OpenLedger’s infrastructure allows attribution to remain connected to usage. Through its Payable AI model, contributors can potentially receive OPEN token rewards automatically whenever their data becomes part of inference activity.
No centralized company manually deciding payouts. No hidden backend calculations. No relying on trust alone.
The infrastructure handles it transparently.
That idea may sound technical on the surface, but economically it changes everything.
Most AI systems today operate like black boxes.
People contribute value. Platforms absorb it. Nobody sees what happens afterward.
OpenLedger flips that structure completely.
It creates an environment where intelligence itself becomes economically traceable.
And personally, I think that becomes extremely important once regulations start tightening globally.
The EU AI Act is already pushing conversations around transparency and accountability. The US continues increasing pressure around AI governance. Asian markets are moving in the same direction as adoption accelerates.
Sooner or later, major AI companies will likely need systems capable of proving where training data originated and how it was used.
When that moment arrives, Proof of Attribution stops looking like an experimental blockchain feature.
It starts looking like required infrastructure.
That is why OpenLedger feels more substantial than most AI crypto narratives floating around right now.
A lot of projects in this sector honestly feel like thin wrappers around existing APIs with tokens attached afterward for market attention.
OpenLedger feels like it is building the foundation layer instead.
And the ecosystem around it keeps reinforcing that direction.
Story Protocol connects copyright infrastructure into AI workflows. Theoriq focuses on verifiable AI agents operating inside DeFi systems. Unstoppable Domains adds identity infrastructure through .openx domains. Trust Wallet integration expands accessibility across users and applications.
Then there is MARBLEX, backed by Netmarble, one of Asia’s largest gaming companies.
That part stood out to me because gaming may eventually become one of the biggest environments for transparent AI systems. When AI-driven economies start interacting with digital assets, marketplaces, NPC systems, and user-generated content, attribution suddenly matters far more than people currently realize.
And OpenLedger already appears positioned for that future.
The more I researched the project, the more I stopped seeing it as just another blockchain protocol.
It started looking more like accountability infrastructure for the next phase of AI growth.
Not flashy. Not built around hype cycles. But quietly solving one of the industry’s biggest long-term problems before most people fully understand how important that problem will become.
Of course, none of this guarantees success.
Crypto remains volatile. AI moves fast. Narratives change constantly.
But if someone asked me the single strongest idea behind OpenLedger, I would not talk about speculation first.
I would talk about Proof of Attribution.
Because the moment AI systems are forced to prove where intelligence came from, OpenLedger may already be standing exactly where the market needs it to be.