#OpenLedger I remember looking at OpenLedger and realizing the part that interested me was not the registry itself. It was the layer beneath the obvious one.Most AI projects I have seen try to improve either the data or the model. Better inputs. Better inference. Better throughput. The middle is usually treated as a corridor, not a destination.OpenLedger does not seem to treat it that way.The system keeps circling back to trading agents. Not as a side feature. As the place where relationships between data, action, and value become visible.That changed the way I read the whole thing. A trading agent is not just another user of the system. It is an active filter. It chooses what to rely on, and by choosing, it reveals what matters in practice.That matters because AI projects usually talk about capability from the outside. They show what the model can do. OpenLedger seems more interested in what the action depends on once the model is already working.That is a very different angle.The useful layer is not the dataset by itself. It is the relationship between the dataset and repeated execution. Once that relationship becomes measurable, the system can start separating what is merely available from what is actually carrying weight.I am not fully convinced yet that most people will notice how important that shift is. It is easy to get distracted by the registry, by the visible stack, by the things that can be named quickly. But the real structure seems to live in the usage pattern that trading agents produce over time.That is the point where OPEN starts to feel structural rather than decorative.It seems attached to the layer that gets built only after the obvious parts are already in place. The token does not just sit beside the system. It seems to help define how repeated dependence gets recognized.That recognition is not simple. A dataset can be used often for reasons that are convenient rather than meaningful. A trading agent can keep returning to the same path because the path is safe, not because it is the best one. So I do not think frequency alone is enough.Still, frequency is not nothing. In a live system, it is often the first sign that something has become indispensable.The closest comparison I can think of is road traffic around a city. The roads themselves matter, but what really tells you where the city has organized itself is where traffic keeps concentrating every day. That flow reveals the hidden map better than the official plan does.OpenLedger seems to be doing something similar with trading agents. It is not only building roads for AI to move on. It is watching where the movement actually settles.That is why the layer feels easy to miss and hard to dismiss.A lot of projects want to declare what should matter. This one seems to wait and see what the agents keep returning to.That approach has consequences. If behavior changes, the map changes. If agents shift their habits, the meaning of the data layer shifts with them. That makes the system responsive, but it also makes it vulnerable to short cycles and self reinforcing paths.I am not sure there is a clean answer to that.What I do know is that OpenLedger feels less like a product that stores data and more like a system that learns where dependence lives.And once that becomes visible, the rest of the stack reads differently to me, even before anything else changes.@OpenLedger $OPEN #openledger
Artikel
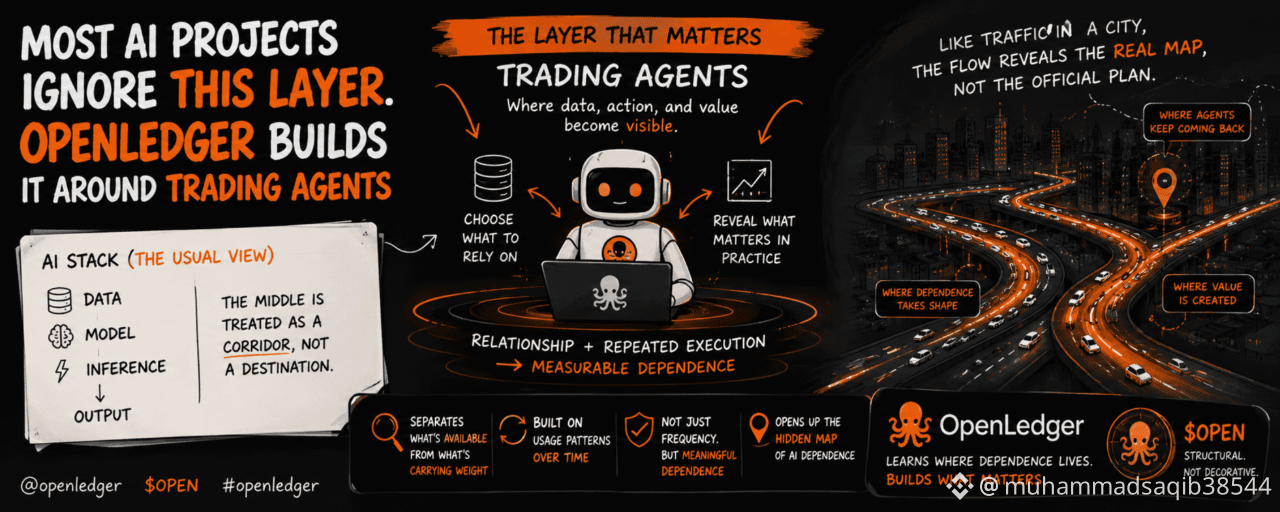
Most AI Projects Ignore This Layer. OpenLedger Builds It Around Trading Agents
Der in diesem Artikel erwähnte Token kann einer hohen Volatilität unterliegen. DYOR.
Haftungsausschluss: Die hier bereitgestellten Informationen enthalten Meinungen Dritter und/oder gesponserte Inhalte und stellen keine Finanzberatung dar. Siehe AGB.