
Càng nhìn vào thị trường AI hiện tại mình càng có cảm giác mọi người đang chú ý quá nhiều vào phần dễ thấy nhất đó là model nào thông minh hơn, agent nào tự động tốt hơn, sản phẩm nào demo đẹp hơn.
Nhưng có một câu hỏi quan trọng hơn lại ít được nhắc đến là những người tạo ra dữ liệu cho AI thì đang ở đâu trong toàn bộ hệ thống này?
AI không tự nhiên xuất hiện. Nó được xây từ dữ liệu, từ kiến thức, từ văn bản, từ nghiên cứu, từ hành vi và từ hàng triệu đóng góp nhỏ của con người trên Internet nhưng khi model bắt đầu tạo ra giá trị, phần lớn lợi ích lại chảy về những bên sở hữu hạ tầng, sở hữu model và kiểm soát sản phẩm cuối cùng.
Người đóng góp ban đầu gần như biến mất.
Đây là lý do mình bắt đầu thấy OpenLedger đáng chú ý hơn những dự án AI crypto thông thường. Ban đầu mình cũng nghĩ đây chỉ là một narrative quen thuộc như AI, agent, token, tương lai phi tập trung nhưng khi nhìn sâu hơn, cách tiếp cận của họ không chỉ xoay quanh việc tạo ra một AI hay hơn mà họ đang cố xây một lớp hạ tầng để AI có thể ghi nhận đóng góp một cách minh bạch hơn.
Ý tưởng cốt lõi khá dễ hiểu là nếu dữ liệu của con người giúp AI trở nên có giá trị thì con người cũng nên có cách tham gia vào giá trị đó.
Nghe đơn giản nhưng thực thi lại cực kỳ khó.
Muốn làm được điều này, hệ thống phải biết dữ liệu đến từ đâu, model nào đã sử dụng dữ liệu đó, output nào được tạo ra từ phần đóng góp nào và phần thưởng nên được phân phối ra sao. Đây không còn là câu chuyện AI trả lời tốt không mà là câu chuyện về quyền sở hữu, truy vết và phân chia giá trị.
Proof of Attribution của OpenLedger vì vậy trở thành điểm mình thấy đáng suy nghĩ nhất. Nếu cơ chế này hoạt động đúng, nó có thể biến dữ liệu từ một thứ bị nuốt vào model rồi biến mất thành một tài sản có dấu vết và có thể được ghi nhận về sau.
Điều này đặc biệt quan trọng khi AI bắt đầu đi vào các lĩnh vực chuyên biệt. Một model cho tài chính không cần cùng loại dữ liệu với một model cho y tế. AI pháp lý, AI giáo dục, AI bảo mật hay AI nghiên cứu đều cần nguồn dữ liệu khác nhau, chuyên môn khác nhau và tiêu chuẩn đánh giá khác nhau.
Đó là lý do khái niệm Datanets của OpenLedger khá thú vị. Thay vì gom tất cả vào một model khổng lồ, họ hướng tới các mạng dữ liệu theo từng lĩnh vực, nơi dữ liệu chất lượng cao có thể được đóng góp, xác minh và sử dụng cho những model cụ thể hơn.
Mình nghĩ xu hướng này sẽ ngày càng quan trọng. AI tổng quát có thể trả lời nhiều thứ nhưng những ứng dụng nghiêm túc trong doanh nghiệp, tài chính hay nghiên cứu sẽ cần độ tin cậy cao hơn rất nhiều. Không chỉ cần câu trả lời tốt mà còn cần biết câu trả lời đó dựa trên đâu.
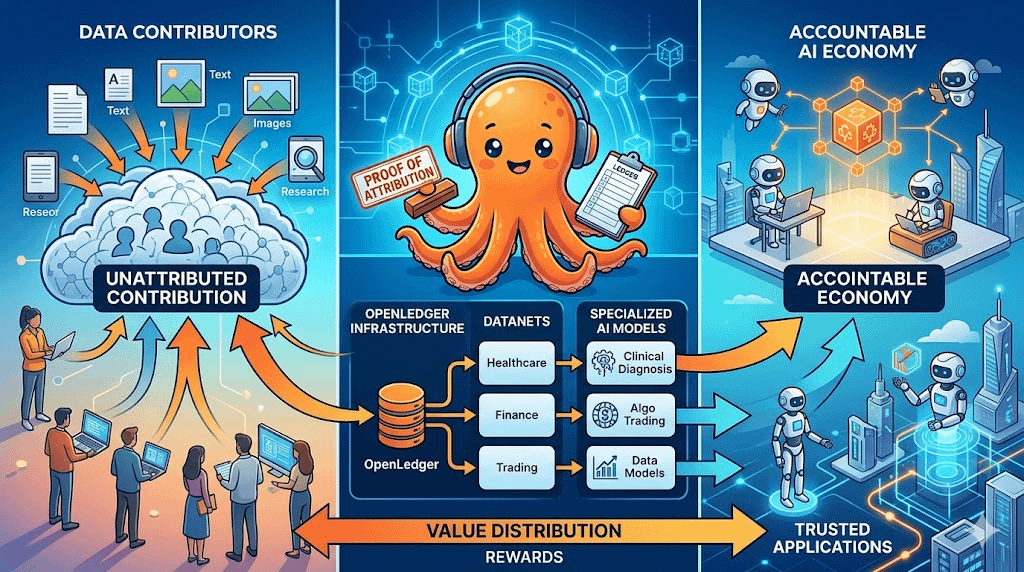
Tất nhiên mình không nghĩ OpenLedger đã giải xong bài toán này. Hạ tầng AI rất đắt, scale rất khó và enterprise adoption không đơn giản như crypto Twitter hay tưởng tượng. Một demo tốt chưa đủ. Doanh nghiệp cần uptime, bảo mật, latency, compliance và khả năng hoạt động ổn định trong môi trường thật.
Ngoài ra nếu reward gắn với dữ liệu, chắc chắn sẽ có người cố spam dữ liệu kém chất lượng hoặc tìm cách thao túng hệ thống attribution. Đây là rủi ro thực tế không thể bỏ qua nhưng ít nhất OpenLedger đang đặt câu hỏi đúng.
Thị trường AI hiện tại không chỉ cần agent thông minh hơn. Nó cần một hệ thống rõ ràng hơn để trả lời những câu hỏi như ai sở hữu dữ liệu, ai được trả công, ai chịu trách nhiệm và giá trị được phân phối như thế nào khi AI tạo ra kết quả.
Đó là lý do mình không nhìn OpenLedger như một “AI coin” thông thường.
Nó giống một nỗ lực xây lớp hạ tầng còn thiếu cho nền kinh tế AI trong tương lai. Có thể còn sớm, có thể còn nhiều thứ phải chứng minh nhưng hướng đi này không phải chỉ là chạy theo hype.
Và trong một thị trường nơi rất nhiều dự án chỉ copy narrative đã có sẵn, việc một dự án đặt cược vào bài toán ownership và attribution của AI khiến mình muốn tiếp tục theo dõi.