A few months ago, I still couldn’t tell whether OpenLedger was actually building infrastructure or just fitting perfectly into the AI + crypto cycle everyone wanted exposure to. The story sounded strong — AI agents, monetized data, attribution, decentralized intelligence — but a lot of it still felt theoretical. Easy to describe. Hard to test.
What changed my perspective wasn’t price action or exchange hype.
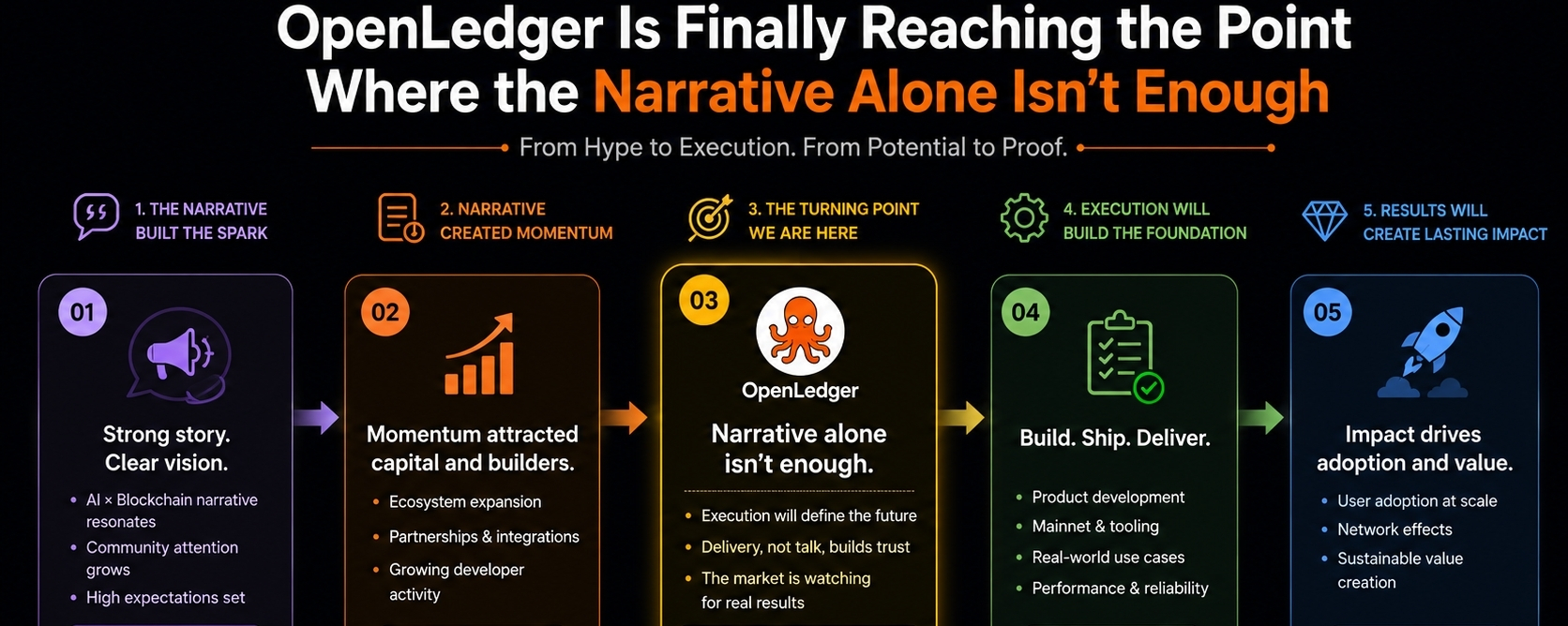
It was watching the project slowly move into areas where systems stop surviving on narrative alone and start dealing with real operational pressure.
The mainnet launch was the first moment where OpenLedger started feeling different to me. Before that, most of the conversation lived in concepts: payable AI, data ownership, attribution economies. Interesting ideas, but still mostly abstract. Once Proof of Attribution became part of a live environment, the discussion changed from “this sounds innovative” to “can this actually function under real usage?”
That’s a much harder question.
A lot of projects talk about rewarding contributors. Very few try to build an actual economic layer where data, models, usage, and payouts are all connected in a measurable way. OpenLedger at least seems to be attempting that directly instead of hiding behind vague governance language.
What I find important isn’t just the attribution system itself. It’s the shift in responsibility that comes with it.
Once attribution becomes infrastructure, builders can’t treat data provenance like optional metadata anymore. Suddenly the quality of inputs matters economically. Traceability matters economically. If the system works properly, spam datasets, recycled outputs, and low-quality contributions eventually become liabilities instead of invisible fuel.
In theory, that creates healthier incentives over time.
But I still think the difficult part hasn’t started yet.
Attribution systems sound clean when activity is small. They become messy once scale introduces real friction: – overlapping datasets
– reused model outputs
– recursive training loops
– payout disputes
– malicious contributors
– micro-settlement overhead
That’s where my attention is now. Not whether the mechanism exists, but whether it stays efficient once the environment becomes chaotic.
The integration work around rights-cleared AI training also stood out to me more than I expected. The Story Protocol connection feels meaningful because it touches a problem the broader AI industry still hasn’t solved properly: traceability after training.
Right now, most AI systems absorb data into models in ways that become almost impossible to audit later. OpenLedger trying to combine licensing, attribution, and automated payouts into one structure feels less like a marketing feature and more like an attempt to prepare for the direction regulation and enterprise AI are probably heading anyway.
That doesn’t mean the solution is complete. It definitely isn’t.
But it does mean the project is starting to think about infrastructure constraints that actually matter outside crypto-native speculation.
Where I’m still unconvinced is the agent economy narrative.
The x402 launch is interesting conceptually because it pushes OpenLedger closer to machine-native transactions instead of purely human-facing applications. APIs, datasets, inference layers, and autonomous services generating revenue independently is a logical vision if AI agents eventually become persistent actors online.
The problem is that a lot of the industry still talks about agent economies as if demand already exists.
Right now, most assumptions still depend on future behavior: – agents reliably managing wallets
– autonomous negotiation between systems
– machine-to-machine payments becoming common
– persistent agent identity layers actually mattering
Maybe that future comes eventually. Maybe it doesn’t.
At the moment, a lot of this still feels earlier than the narrative suggests.
But I’ll give OpenLedger credit for one thing: they’re building mechanisms first instead of endlessly talking about possibilities. That alone separates it from a large percentage of AI-crypto projects that never move beyond ecosystem storytelling.
Another thing that changed my view recently is realizing OpenLedger no longer looks like a single-purpose protocol. It’s slowly becoming a coordination layer attempting to connect attribution, payments, licensing, identity, data monetization, and agent execution into one system.
That makes it more ambitious.
It also makes execution much harder.
Because once a protocol tries to sit underneath multiple economic relationships at the same time, the standards become stricter very quickly. Reliability matters more. Governance matters more. Incentive design matters more. Attribution mistakes become expensive. Downtime becomes dangerous.
Ironically, that growing pressure is probably the most encouraging sign so far.
OpenLedger finally feels exposed to real infrastructure risk instead of protected by abstraction.
And that’s important because real systems eventually get stress-tested in ways narratives never do.
I still don’t care much about most OPEN market metrics. Trading spikes, social hype, and exchange attention don’t tell me whether the system becomes durable.
The things I care about now are simpler: – Are builders still integrating once incentives cool down?
– Do attribution rails still work under heavier usage?
– Can disputes be handled without central intervention?
– Does payout logic remain efficient at scale?
– Would enterprises actually trust this infrastructure in regulated environments?
Those questions matter more than roadmap graphics or partnership threads.
Right now, my view has shifted from “probably narrative-driven” to “possibly early infrastructure.”
That’s a meaningful change.
But I still think the hardest proof point is ahead.
OpenLedger has shown that the architecture can exist. What it hasn’t proven yet is whether the architecture can remain economically stable once scale, abuse, regulation, and real dependency enter the picture simultaneously.
The update that would genuinely change my opinion from here isn’t another integration announcement.
It would be seeing real applications continuously rely on these systems in ways that create actual operational dependency — not experiments, not incentive farming, not temporary ecosystem activity.
Because that’s the moment infrastructure stops being interesting and starts becoming difficult to replace.
And maybe that’s the strange part about watching OpenLedger right now.
For the first time, it doesn’t feel protected by hype anymore.
It feels exposed. Tested. Forced to prove itself in public.
That’s where real infrastructure either hardens into something valuable… or quietly breaks under the weight of its own ambition.
I’m still waiting to see which direction this goes.
But I can’t deny the difference anymore — this no longer feels like a project trying to sound important.
It finally feels like a system risking failure in order to become real.
