
A few years ago, “infrastructure” meant the unglamorous foundation underneath everything else. Roads. Ports. Cloud servers. The layer nobody bragged about, but everyone depended on.
AI changed that conversation. Infrastructure suddenly became the story. GPUs, clusters, inference layers, compute capacity — all of it started to sound like the frontier. The market began to treat raw horsepower as the main bottleneck in AI.
That made sense at first.
But the more AI systems move from demos to actual use, the less the problem looks like intelligence and the more it looks like accountability.
A model writing poetry badly is harmless enough. A model supporting credit decisions, compliance checks, legal drafting, identity screening, or capital allocation is something else entirely. Once AI touches real decisions, the central question stops being how fast it runs.
It becomes: who is responsible when it fails?
That question is often underweighted in crypto AI narratives.
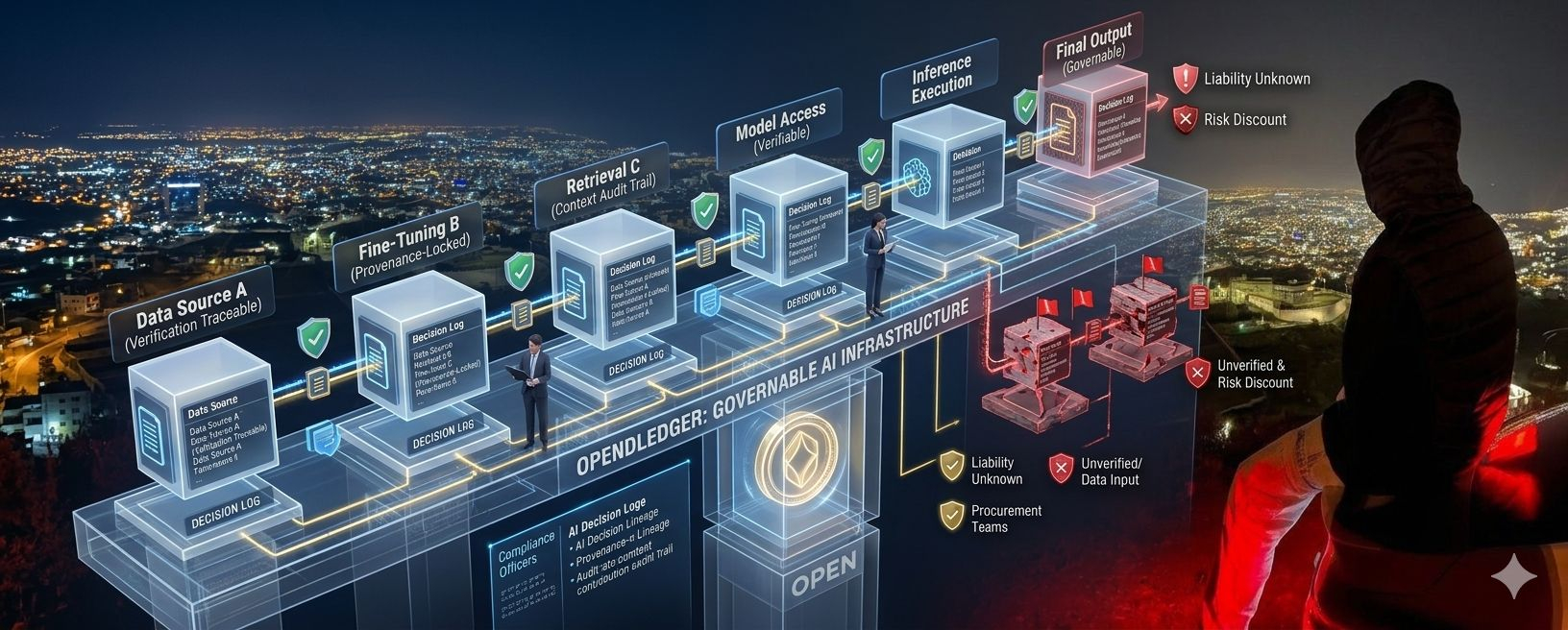
@OpenLedger is usually framed as AI infrastructure, and that is not wrong. But that framing may miss the more important angle. A lot of people talk about attribution as if it were mainly a rewards system — a way to compensate contributors fairly. That is useful, but incomplete.
In serious systems, attribution is not just about incentives.
It is about liability mapping.
And that changes the conversation.
I keep thinking about the early wave of autonomous agent enthusiasm. People were talking about agents making payments, negotiating services, managing workflows, and coordinating tasks across systems. Technically impressive, sure. But a deeper issue was being glossed over: if an agent produces a bad outcome because its data, logic, retrieval path, or upstream source was compromised, where does responsibility actually sit?
That answer is not clean.
Traditional software was simpler in one important way. A company shipped code. If something broke, accountability was usually traceable back to the vendor, the operator, or the implementation. Not simple, exactly, but legible.
AI systems are more fragmented.
One party supplies data. Another fine-tunes the model. Another hosts inference. Another adds orchestration. Another injects retrieval context. Another wraps the workflow in business logic. By the time an output reaches the end user, responsibility has been distributed across a chain of actors.
That kind of diffusion makes risk harder to define.
And if risk is harder to define, it is harder to price.
Markets dislike that.
Institutions dislike it even more.
Retail users may tolerate uncertainty if the product feels magical. Enterprises usually do not. Banks certainly do not. Regulated environments absolutely do not.
Nobody walks into a compliance review and says the model “felt trustworthy.”
They ask for provenance. Audit trails. Source lineage. Escalation procedures. Documentation. Decision logs. Something they can defend later if a regulator, client, or internal review asks uncomfortable questions.
That is where #OpenLedger starts to look more interesting.
If it is actually building infrastructure around verifiable attribution, then the more important value may not be that it helps AI scale faster.
It may be that it helps AI become governable.
That is a less exciting pitch, but often a more durable one.
Governability does not sound as sexy as compute. It will not dominate headlines the way raw model benchmarks or hardware narratives do. But boring infrastructure has a habit of mattering longer than flashy infrastructure.
Financial markets offer a useful comparison. At first, speed mattered. Then auditability mattered. Then compliance mattered. Over time, the control layers became just as valuable as the execution layers.
AI may follow a similar path.
Not perfectly. No analogy does. But the pattern rhymes.
There is also a practical truth that gets overlooked: institutions are not anti-innovation. They are anti-uncertainty they cannot operationalize.
That distinction matters.
A procurement team evaluating AI does not care about crypto-native storytelling. It cares whether the system can explain itself when legal, risk, or regulators start asking questions later.
And they always ask questions later.
Take a simple example. Imagine an AI tool used to support insurance underwriting. Not full automation. Just decision support.
Now imagine the model produces biased recommendations because a part of the underlying data pipeline was flawed, manipulated, or poorly sourced. A customer disputes the decision. The matter escalates. Internal governance wants to trace the chain of influence.
If nobody can map that chain in a meaningful way, the organization is left improvising.
In regulated environments, improvisation is expensive.
That is the point where attribution stops being a philosophical feature and starts becoming operational infrastructure.
This is why the phrase “pricing model liability” does not feel exaggerated to me.
Not literal legal liability, at least not yet.
Economic liability first.
Trust premiums. Risk discounts. Counterparty confidence. Integration willingness. Procurement friction.
Those factors often get priced long before formal legal frameworks catch up.
If two AI ecosystems produce similar outputs, but one offers a stronger provenance layer around how those outputs were shaped, institutions may prefer the more auditable environment even if it is not the most performant one on paper.
That happens in other industries all the time.
Auditable financial rails beat opaque alternatives.
Trusted supply chains beat uncertain ones.
Reliable controls quietly win budgets.
Still, skepticism is warranted.
Attribution in AI is genuinely hard. Training influence is diffuse. Signal blending is messy. Contribution weights can become approximate at best and fiction at worst if the system is poorly designed.
That matters, because fake accountability can be worse than obvious opacity.
Then crypto adds its own set of complications.
The moment attribution becomes economically valuable, the system invites gaming.
Spam datasets. fabricated contribution claims. sybil behavior. reputation farming. incentive distortion.
Anyone who has spent time around crypto incentives knows how quickly a good mechanism can become an attack surface.
So the real challenge is not just building attribution. It is building attribution that remains useful under adversarial conditions.
There is also a strategic question worth asking.
Do enterprises actually want decentralized accountability?
Conceptually, it sounds elegant. In practice, some organizations may prefer a centralized vendor precisely because responsibility feels easier to manage that way. One provider. One contract. One escalation path.
Distributed accountability can become bureaucratic chaos if the design is weak.
So OpenLedger’s challenge is not only technical. It is product-level, too.
It has to make distributed attribution feel operationally useful, not just intellectually appealing.
That is a much harder standard than many token narratives account for.
Still, I cannot shake the sense that the AI infrastructure conversation is stuck in an earlier phase.
People are still focused on building intelligence faster.
But maybe the next bottleneck is not intelligence.
Maybe it is consequence management.
Because intelligence without accountable lineage is fine for entertainment.
It is much less fine for money.
And far less fine for regulated systems.
If that shift really happens, then $OPEN may not be competing in the category most people assume.
Not compute. Not model access.
Something quieter.
A market for reducing uncertainty around machine decisions.
That is a less glamorous thesis.
Which is exactly why it may matter.