

Pichle dino jab main college se highway pakad kar ghar wapas aa raha tha, to mere or bade bhai ke beech blockchain ke current state ko lekar lambi behes chal rahi thi. Hum market mein flood hone wale artificial intelligence tokens ko dissect kar rahe the. Mera stance straightforward aur skeptical tha. Maine usko bola, bhai ek cheez clear karo, main jab bhi naye crypto crossover project ko dekhta hoon, to end mein wo empty wrapper hi nikalta hai. Ye sirf flashy buzzwords use karte hain, machine learning ke claims karte hain, par peeche koi real smart contract infrastructure nahi hota. Frustrating lagta hai jab aap ghanto kisi whitepaper ko padhte ho or realize hota hai ki inke paas koi verifiable product hai hi nahi. Big tech companies ka jo data monopoly hai, usko ye projects touch nahi karte. Ye decentralized data ki baatein karte hain, par andar inke systems abhi bhi centralized servers par chal rahe hote hain, us fundamental problem ko ignore karte hue ki AI models black box mein train ho rahe hain.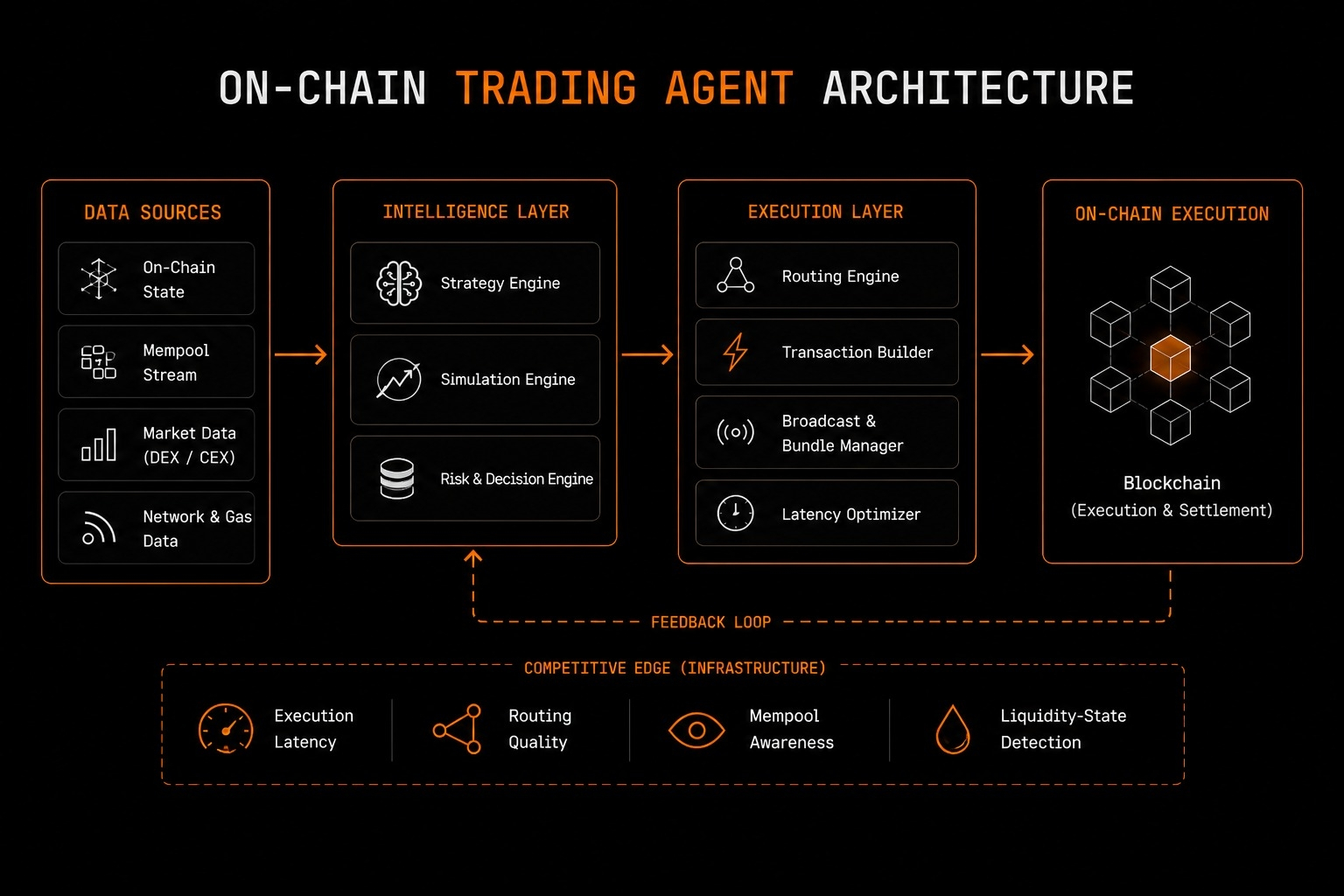
Yahi doubt main reason tha jiski wajah se maine shuru mein @OpenLedger ko ignore kar diya tha. Mujhe laga ye bhi bas ek speculative play hai. Par jab maine research ke liye inke documentation ko deep dive karna shuru kiya taaki ek true valuable review likh saku, to mera perspective shift hone laga. Jis cheez ne mera attention catch kiya, wo inki marketing nahi thi, balki actual verifiable data pipeline build karne par practical focus tha. Ye log us core data monopoly problem ko sach mein solve karna chahte hain jahan badi corporations internet scrape karti hain, humare output par models train karti he or saara profit khud rakhti hain. #OpenLedger ek actual decentralized AI data economy introduce kar raha hai jo collaborative AI principles par based hai, on-chain mechanics ke sath jisko aap transparently trace kar sakte ho.
Jab hum $OPEN token problem or solution ki baat karte hain, to inka approach is baat par rooted hai ki token network mein real utility ki tarah kaise function karta hai. Ek speculative asset hone ke bajaye, $OPEN token proof of contribution system ka economic engine ban jata hai. Jab bhi users high-quality datasets provide karte hain, unki contributions on-chain record hoti hain. Agar aage chalkar koi AI model kisi output ke liye us specific data ko utilize karta hai, toh decentralized node validation system us usage ko original source tak trace kar leta hai or creator ko reward karta hai. Ab aap mega-corporations ko free mein feed nahi kar rahe. Ye network information ki puri lineage track karta hai, ensure karta hai ki data upload hone se output ko influence karne tak transparent information flow maintain rahe.
Ecosystem ko analyze karte time, maine Octoclaw ki details par dhyaan diya, ye samajhne ke liye ki usko kab se add kiya gaya aur ek regular user uska use kaise kare. Octoclaw recently launch hua as an intelligent agent jo real-time workflow automation ke liye design kiya gaya hai, aur ye normal conversational interfaces se alag hai. Basic sawalon ke jawab dene ke bajaye, Octoclaw deep data research conduct kar sakta hai, execution strategies generate kar sakta hai, aur decentralized ecosystems mein smart contracts ke sath interact karke tasks execute kar sakta hai. Agar aapko koi on-chain signal milta hai, toh aap Octoclaw ko configure kar sakte ho. Ye effectively us gap ko bridge karta hai jahan aapko pata hota hai ki on-chain kya karna hai par execute karne ka friction usko hard banata hai, proving ki infrastructure ek clear open token usecase support karta hai.
AI training ki is value ko centralized mega-corporations se redirect karke actual data creators ki pockets mein dalna economic sense banata hai. Hum log daily basis par technical research aur analysis ke through valuable insight generate karte hain. OpenLedger is value flow ko jo reverse kar raha hai, wo fundamental shift hai jo genuinely matter karta hai. Small creators ke paas ab finally rasta hai jahan wo specific knowledge securely monetize kar sakte hain. Ye transparent information model ensure karta hai ki reward unke actual utility ke basis par mile.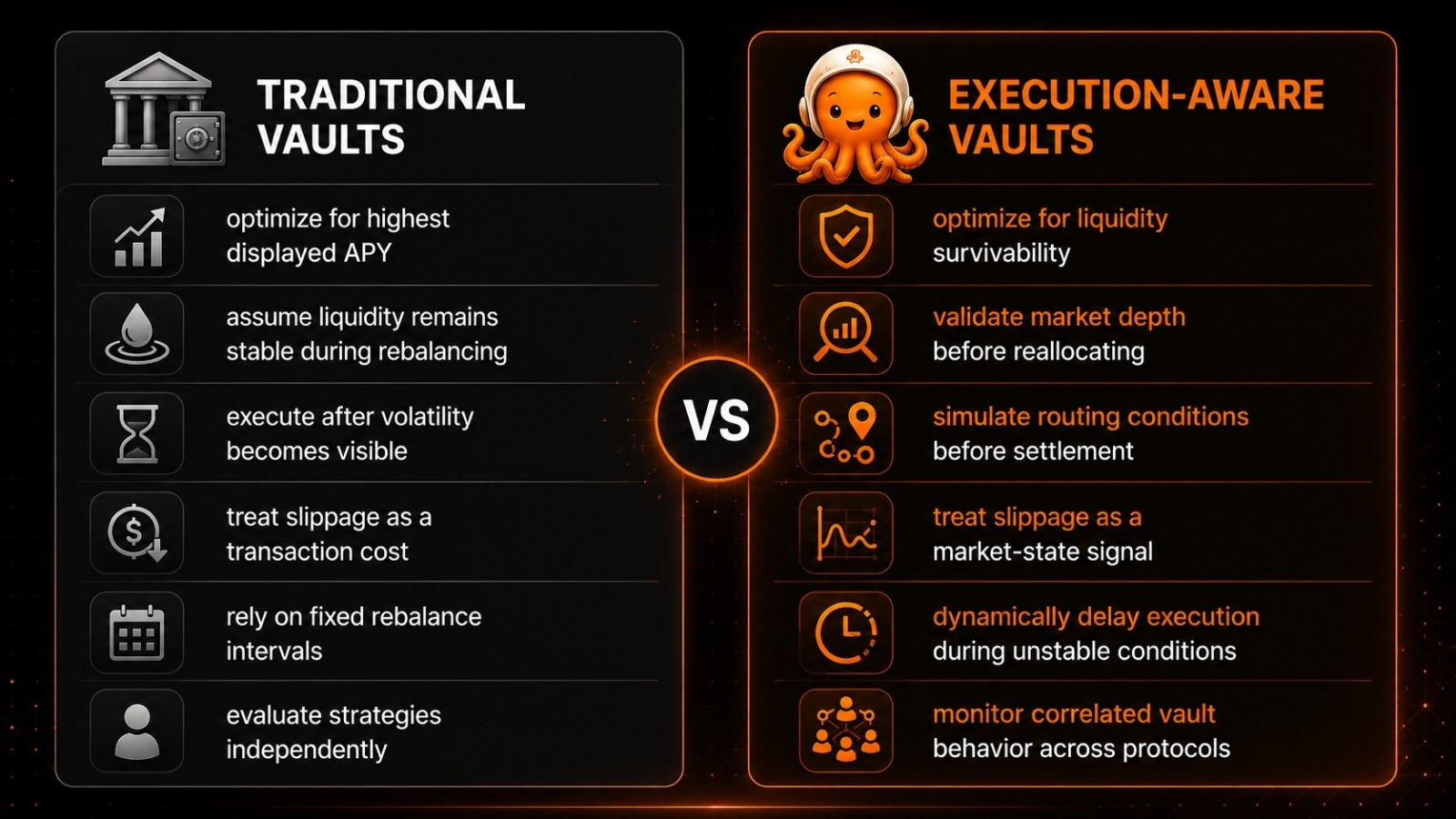
Par mujhe iske risks aur rewards ke baare mein honest rehna padega kyunki ye koi jadoo nahi hai. Decentralized level par data quality balance karna notoriously hard kaam raha hai, aur yahi inke vision ka sabse bada bottleneck ban sakta hai. Yahan risk bad actors ka hai jo system ko game karne ki koshish karenge. Wo log deliberately network ko garbage data se spam karenge sirf token rewards ki mining full details nikalne ke liye. Agar inka decentralized node validation process is low-quality input ko filter out karne mein fail hota hai, toh pura dataset poison ho jayega. Koi enterprise AI company pollute kiye gaye data ke liye pay nahi karegi, aur project ki scalability aur utility severely compromise ho jayegi.
Aane wale mahino mein, mera practical approach sirf ye observe karne ka hoga ki baahar ke developers is B2B cross-ecosystem data marketplace ke sath kaise interact karte hain. Is infrastructure ka long-term survival directly enterprise AI demand par depend karta hai, na ki retail speculation par. Sabse clear signal mere liye ye hoga ki kya external AI studios inke decentralized infrastructure ko models improve karne ke liye sustained period tak adopt kar rahe hain. Asali test yahi hai ki kya OpenLedger continuously clean, verifiable data provenance deliver kar sakta hai aur truly decentralized tareeke se network ke noise ko filter out kar sakta hai. Main aisi cheezon ko deck par nahi actual production mein bante hue dekhna prefer karta hoon.