
$OPEN Ich habe die letzten zwei Tage OpenLedger's autonome Agentenarchitektur durchforstet und ehrlich gesagt? Das, was mich ständig aufhält, ist nicht irgendeine einzelne Fähigkeit 😂
Es ist die Kombination.
Forschungstools existieren. Ausführungsschichten existieren. Generierungssysteme existieren. Automatisierungspipelines existieren. Was OpenLedger's On-Chain-Agentenwirtschaft strukturell anders macht, ist, dass das Pitch nicht lautet, wir haben ein besseres Forschungstool oder eine intelligentere Ausführungsschicht gebaut. Das Pitch ist, dass all diese vier Fähigkeiten innerhalb eines Agenten-Kontexts leben, der on-chain läuft, wobei jede Aktion durch Proof of Attribution zugeordnet wird.
das verändert etwas Fundamentales.
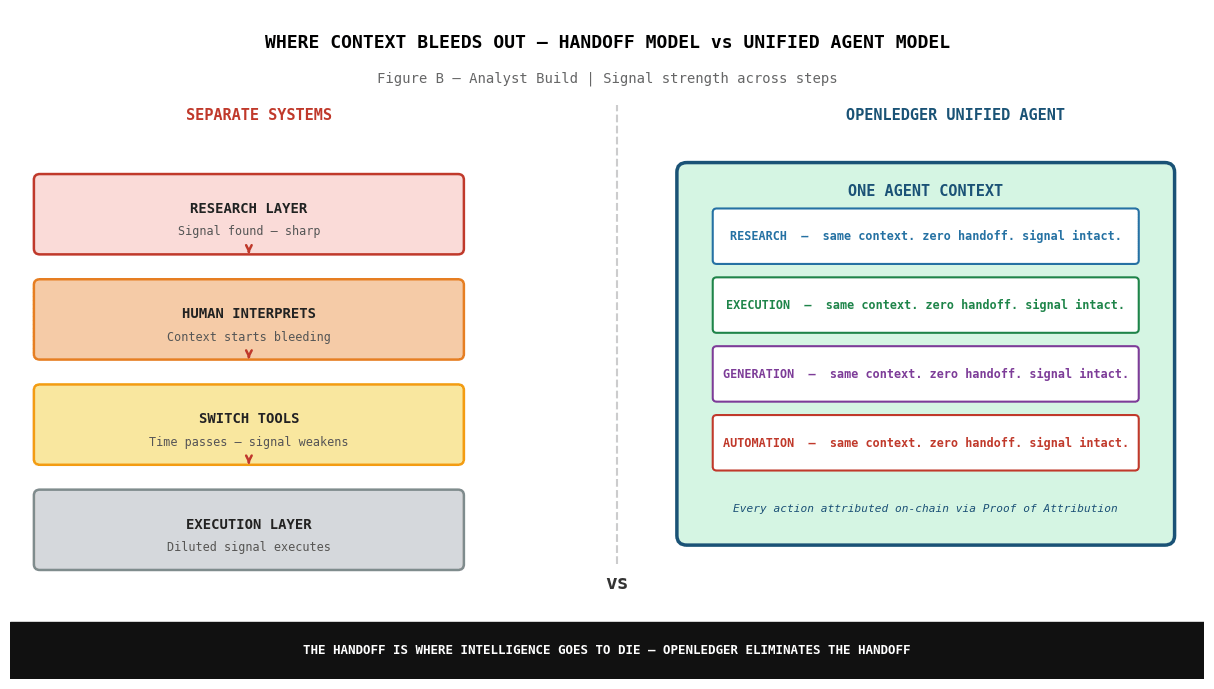
Wenn Forschung und Ausführung separate Systeme sind, verwaltest du immer einen Übergang. Die Forschungsebene findet etwas. Du interpretierst es. Du entscheidest zu handeln. Du wechselst die Werkzeuge. Du konfigurierst die Aktion. Dann läuft es. Jeder einzelne dieser Schritte ist ein Ort, an dem der Kontext verloren geht. Das Signal, das in der Forschungsebene scharf war, kommt in der Ausführungsebene leicht verdünnt an. Zeit ist vergangen. Die Bedingungen haben sich geändert. Die ursprüngliche Einsicht ist schwächer.
Die Überbrückung dieser Lücke bedeutet, dass das Signal, das die Entscheidung ausgelöst hat, dasselbe Signal ist, das sie ausführt. Kein Übergang. Kein Übersetzungsverlust. Kein Mensch, der zwei Systeme manuell verbindet.
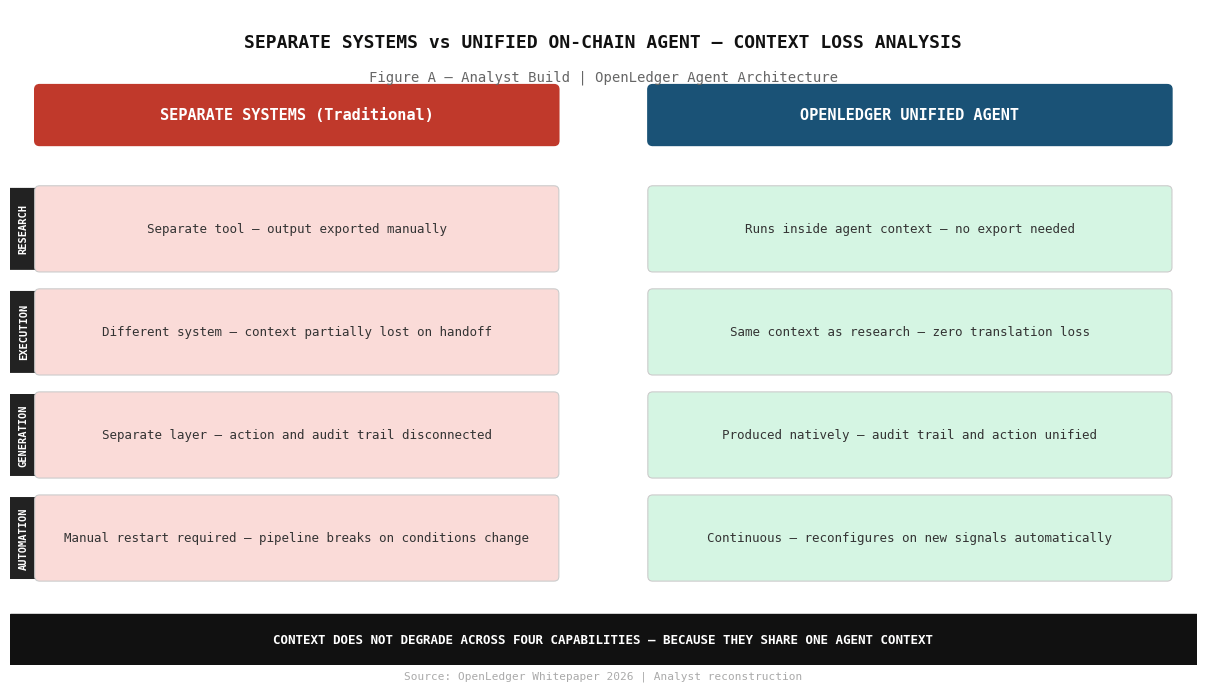
Die Generierung, die darauf sitzt, ist der Teil, den ich immer wieder lese. Die meisten Agenten handeln oder erklären. Sie führen aus oder fassen zusammen. Wenn die Generierung im selben Agenten-Kontext enthalten ist, bedeutet das, dass die Prüfspur und die Aktion vom selben System erzeugt werden. Nicht in eine separate Schicht exportiert, um dokumentiert zu werden. Nativ produziert. On-Chain. attribuiert.
Automatisierung ist das vierte Element und ehrlich gesagt das wichtigste für den realen Einsatz. Ein Agent, der all drei tun kann, wenn du ihn darum bittest, ist immer noch ein Werkzeug. Ein Agent, der kontinuierlich läuft, neue Signale aufnimmt, sich basierend auf sich ändernden Bedingungen neu konfiguriert und ohne manuelle Neustarts weiterarbeitet, ist Infrastruktur. Die On-Chain-Agentenwirtschaft von OpenLedger ist für die zweite Definition gebaut.
was ich wirklich nicht lösen kann, ist die Komplexitätskosten dieser Vereinheitlichung. Jedes System, das vier Fähigkeiten gleichzeitig handhabt, hat mehr Fehleroberflächen als eines, das eine Sache gut macht. Forschung, Ausführung, Generierung und Automatisierung haben jeweils unterschiedliche Fehlerarten. Wenn alle vier in einem einzigen On-Chain-Agenten laufen, sind alle vier Fehlerarten gleichzeitig vorhanden. Die Vereinheitlichung, die den Wert schafft, ist dieselbe Architektur, die das Risiko konzentriert.
Was niemand berechnet:
ModelFactory ermöglicht es jedem, ein spezialisiertes Sprachmodell zu veröffentlichen und jedes Mal, wenn dieses Modell abgefragt wird, zu verdienen. Keine Plattformgebühr. Kein Zwischenhändler. Direkt zum Entwickler.
Die KI-Wirtschaft wird hier neu aufgebaut und die meisten Leute schauen immer noch auf den Preis anstatt auf die Mechanik.
Was denkst du – wird die On-Chain-AI-Attribution zum Branchenstandard oder bleibt sie ein Nischeninfrastrukturspiel?
ehrlich gesagt, weiß ich nicht, ob die Zusammenführung von vier Fähigkeiten in einem On-Chain-Agenten etwas wirklich Größeres als die Summe seiner Teile hervorbringt oder einfach einen komplexeren Single Point of Failure schafft, der auf vier verschiedene Arten gleichzeitig ausfällt 🤔
Was denkst du – ist die vereinheitlichte Agentenarchitektur die Zukunft der On-Chain-AI oder gewinnt die Komplexität letztendlich immer??