OpenLedger (OPEN): the AI project that feels less like hype and more like a warning
I’ve been watching AI projects pile into crypto for months now, and honestly, most of them blur together after a while. Same language. Same oversized promises. Same “revolutionizing AI infrastructure” pitch stretched across different websites with different token tickers attached to them. Eventually it all starts sounding hollow, like a market trying to convince itself it still believes its own excitement.
But OpenLedger kept sitting in the back of my mind for a different reason.
Not because it looked louder than everything else. Actually the opposite. The project feels strangely focused on something most people are barely discussing yet: ownership inside AI systems. Not ownership in the simple investor sense either. Ownership of data. Ownership of contribution. Ownership of intelligence itself.
That changes the entire conversation.
Because right now AI is becoming one giant extraction machine. Data goes in from millions of people, platforms, communities, researchers, workers, creators, and users… then value concentrates upward into a handful of models and companies. Most contributors disappear from the story completely. Their information shapes outputs, trains systems, improves responses, but economically they become invisible.
OpenLedger seems built around the assumption that this structure eventually becomes unsustainable.
And the weird thing is, I think they might be right.
AI’s biggest resource is starting to look scarce
People still talk about AI like compute is the only thing that matters. Bigger GPUs. Bigger clusters. Bigger training runs. But the market is slowly realizing something uncomfortable: raw data quality matters more than endless quantity now.
The internet has already been scraped to exhaustion.
What becomes valuable next is specialized information. Clean information. Verified information. Domain-specific knowledge that actually improves model performance instead of flooding systems with noise.
A healthcare model trained on verified medical datasets matters differently than one trained on random internet text. Same with legal systems, trading systems, cybersecurity systems, logistics systems, enterprise automation, scientific research.
That’s where OpenLedger starts becoming interesting.
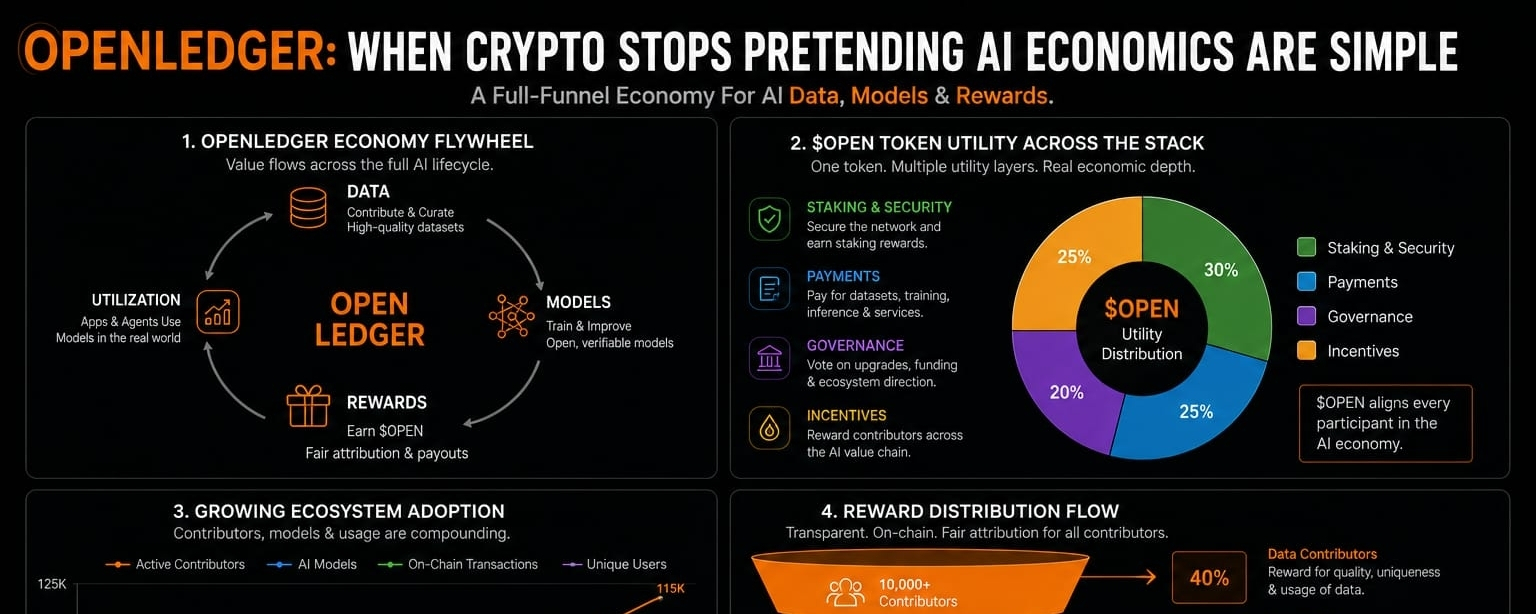
Instead of treating data as disposable fuel, the project treats it like infrastructure with economic value attached to it. Their Datanet model basically creates decentralized data ecosystems where contributors can submit, validate, and monetize specialized datasets tied to AI development.
That sounds technical on paper, but underneath it is a much more human idea.
People who help create intelligence should not disappear from the economic chain afterward.
Simple idea.
Massive implications.
The project is really about attribution
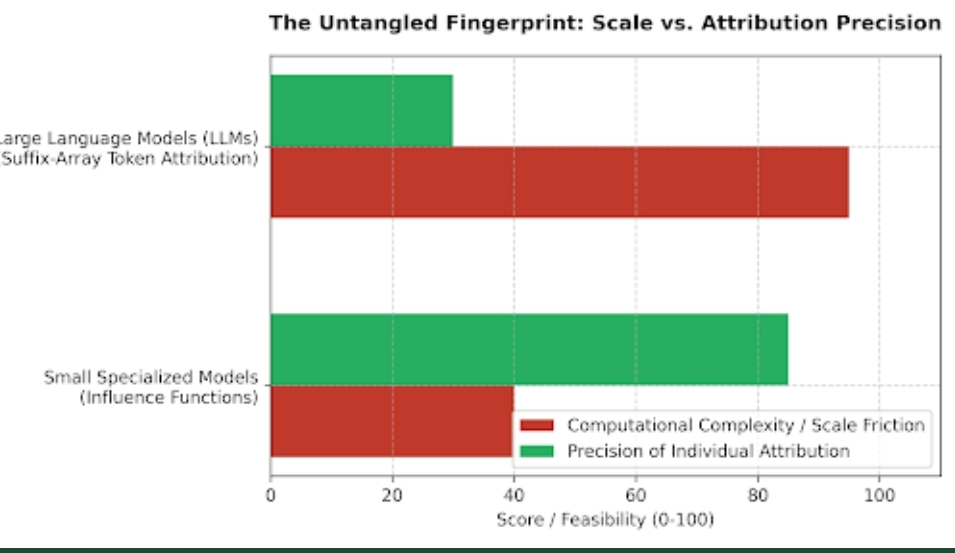
The deeper I looked into OpenLedger, the clearer it became that the blockchain itself is almost secondary. The real obsession here is attribution.
Who contributed what?
Which datasets mattered?
Which information improved the model?
Who deserves compensation when the system generates value later?
That’s the center of everything they’re building.
Their “Proof of Attribution” mechanism tries to track contributions across data pipelines, model training, and inference usage so rewards can theoretically flow back toward contributors over time instead of stopping at centralized ownership layers.
And honestly, that’s where the project suddenly stops sounding like another AI token and starts sounding like a response to something much larger happening in tech.
Because AI is creating enormous economic value while simultaneously erasing visibility around where that value originated.
OpenLedger is trying to reverse that trend before it becomes permanent.
Whether they can actually pull this off at scale is another story entirely. Measuring contribution inside AI systems is brutally complicated. Influence is hard to quantify. Data quality is subjective. Bad actors always appear once incentives exist.
But even attempting this feels more meaningful than most of the empty AI branding floating around crypto right now.
OPEN feels tied to actual network behavior
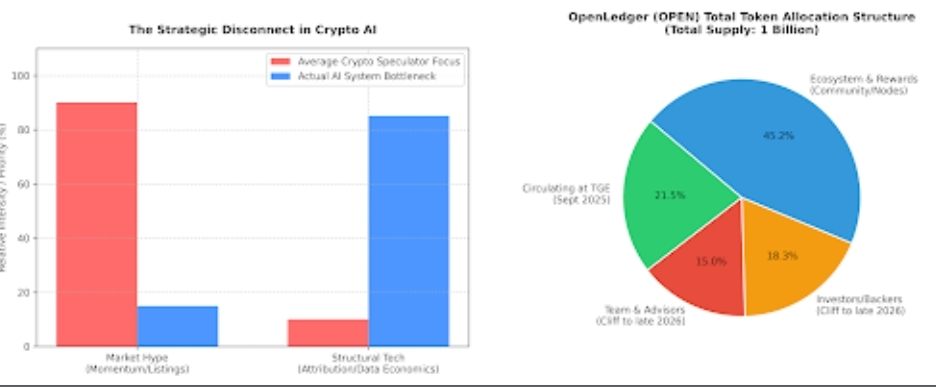
A lot of AI tokens feel disconnected from reality. The token exists because crypto expects tokens to exist.
OPEN at least appears woven directly into ecosystem activity.
The token powers transaction fees, governance, staking, inference payments, contributor rewards, and model-related interactions. Data contributors earn through participation. Builders use the network for AI-related operations. The ecosystem loops value back toward contributors instead of only upward toward centralized ownership.
At least structurally, there’s logic there.
And in this market, coherent structure alone already puts a project ahead of a surprising number of competitors.
What I also find interesting is how OpenLedger isn’t trying to become “the next ChatGPT.” That narrative already feels overcrowded and unrealistic. Instead, the project seems more focused on becoming infrastructure beneath AI economies.
That’s a quieter ambition.
Possibly a smarter one too.
Infrastructure projects usually look boring until suddenly everybody needs them.
OpenLoRA might end up mattering more than people realize
One thing that keeps getting overlooked is OpenLoRA.
Most people outside technical circles skip past it because it sounds too developer-focused. But it may actually be one of the more important pieces of the ecosystem.
AI is drifting toward specialized smaller models now, not just giant frontier systems. Companies increasingly want focused intelligence trained for narrow tasks instead of one oversized universal model trying to do everything badly.
That creates demand for efficient fine-tuning and scalable model serving.
OpenLoRA is designed around serving large numbers of LoRA adapters efficiently while reducing GPU overhead and inference costs. In simple terms, it’s trying to make specialized AI deployment cheaper and more scalable.
And this matters because inference economics are quietly becoming one of AI’s biggest bottlenecks.
People talk endlessly about training models, but eventually somebody has to pay to run these systems continuously at scale. Cost efficiency becomes survival.
OpenLedger seems aware of that reality earlier than some projects.
There’s also a bigger tension underneath all this
The more AI grows, the more centralized the industry becomes.
A handful of companies control models. A handful control compute. A handful control cloud infrastructure. A handful increasingly control data pipelines too.
That concentration is accelerating faster than most people realize.
OpenLedger pushes in the opposite direction. Not aggressively. Not ideologically. More economically than politically.
It creates systems where contributors, validators, model builders, and data providers all become part of the value chain instead of feeding centralized black boxes without visibility.
That doesn’t automatically mean decentralization wins.
Convenience is powerful. Centralized AI systems are easier to scale, easier to optimize, easier to monetize quickly.
But there’s still a growing discomfort around the idea that intelligence itself could become permanently owned by a tiny number of institutions.
OpenLedger feels like one of the earlier attempts to build an alternative before that consolidation fully hardens.
The risks are still very real
None of this means the project is guaranteed to succeed.
Far from it.
Actually, OpenLedger is attempting something extremely difficult.
Attribution systems sound elegant conceptually but become messy once real economic incentives collide with real-world behavior. Spam contributions. Manipulated datasets. Reward farming. Governance friction. Scalability pressure. Enterprise adoption hurdles. Regulatory uncertainty around AI ownership.
The list gets long fast.
And crypto markets rarely reward patient infrastructure building. Narratives move faster than implementation cycles. Sometimes by years.
That creates a strange situation where projects doing more serious long-term work often look quieter than projects built entirely around momentum and speculation.
OpenLedger feels caught somewhere inside that tension right now.
Final thoughts
What keeps pulling me back toward OpenLedger is that it doesn’t really feel obsessed with AI hype itself. It feels obsessed with the invisible economic layer underneath AI.
That’s a much more interesting place to build.
The project is essentially trying to answer a question most of the industry still avoids:
If intelligence becomes programmable, scalable, and economically valuable… who gets paid for creating it?
Right now the answer is mostly centralized platforms.
OpenLedger is betting that answer changes over time.
Maybe they’re early. Maybe the market isn’t ready yet. Maybe attribution systems never fully work at scale.
But the direction still feels important.
Because eventually people will stop asking whether AI can generate value.
The harder question will become who that value belongs to after it’s created.
And that’s the exact territory OpenLedger is quietly trying to build around before everyone else realizes why it matters.