OpenAI keeps talking about “democratizing AI.” Crypto projects keep promising “decentralized intelligence.” Somewhere in the middle of all that noise, most people quietly stopped asking a more practical question: who actually controls the data pipeline?
Because that’s the real choke point.
Not the chatbot interface. Not the viral AI assistant that can generate anime avatars or summarize PDFs in six languages. Those are product layers. The harder problem sits underneath all of it, collecting specialized datasets, managing permissions, training models efficiently, and figuring out who gets rewarded when those systems create value.
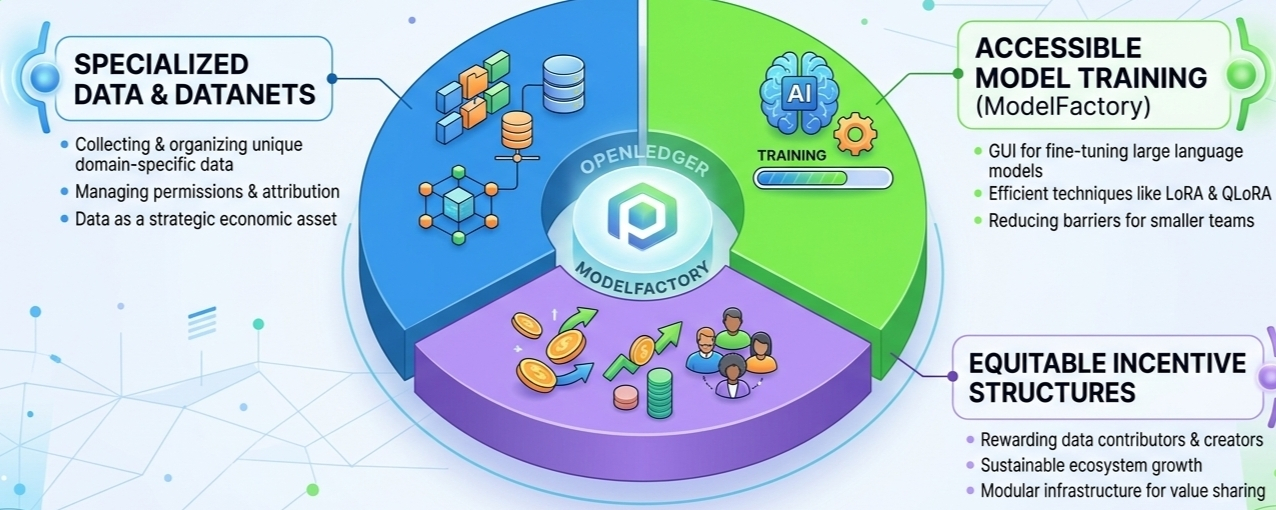
That’s the corner of the market OpenLedger seems interested in, and ModelFactory is probably the clearest example of how they’re approaching it.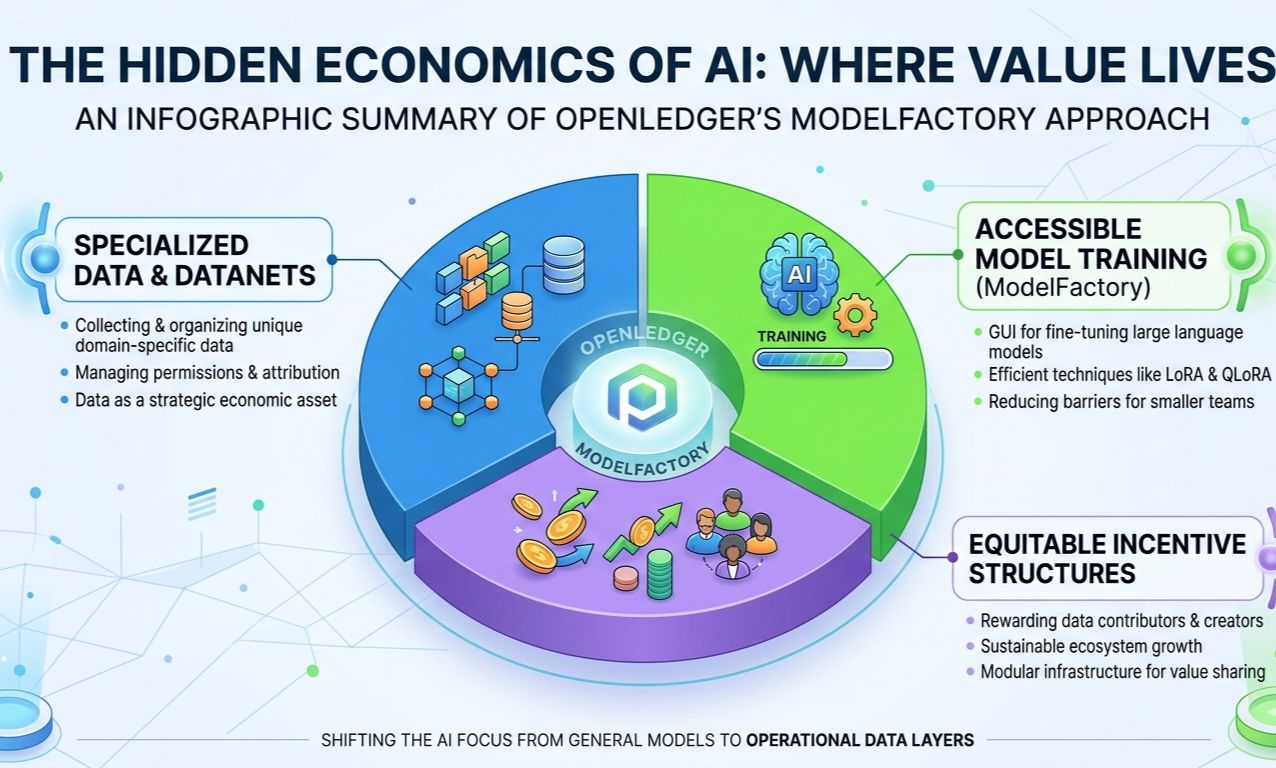
At a surface level, ModelFactory sounds almost underwhelming. It’s essentially a GUI-based platform for fine-tuning large language models. No terminal wrestling, no dependency hell, no manually configuring CUDA environments at 2 a.m. like some kind of rite of passage for machine learning engineers. You log in, choose a model, configure training parameters through the interface, upload approved datasets, and start fine-tuning.
Simple pitch. But the simplicity is doing a lot of work here.
Most AI infrastructure still assumes the user is deeply technical. Even today, customizing an LLM usually means navigating Python environments, cloud GPU costs, APIs, training scripts, inference setups, version conflicts, and a stack of tooling that immediately filters out anyone who isn’t already embedded in ML engineering culture. There’s a reason so many businesses talk about “using AI” while relying entirely on off-the-shelf APIs from OpenAI or Anthropic. Building specialized systems remains painfully inaccessible for smaller teams.
ModelFactory is clearly trying to reduce that barrier.
And honestly, this trend was inevitable. The AI market is moving toward specialization whether people admit it or not. General-purpose models are impressive, but enterprises increasingly want systems trained around narrow contexts and proprietary knowledge. Law firms want legal reasoning tied to legal datasets. Financial platforms want models shaped around market behavior and internal analytics. Healthcare organizations want domain-specific medical intelligence. Gaming ecosystems want AI that actually understands their communities instead of hallucinating its way through patch notes.
The era of “one giant model for everyone” already looks shaky.
Open-source acceleration made that obvious. Architectures like LLaMA, Mistral, and DeepSeek are spreading rapidly across the ecosystem, and model quality is commoditizing faster than many expected. The moat is shifting elsewhere.
Data is becoming the scarce asset.
Not random scraped internet sludge. High-quality, structured, domain-specific, permissioned datasets.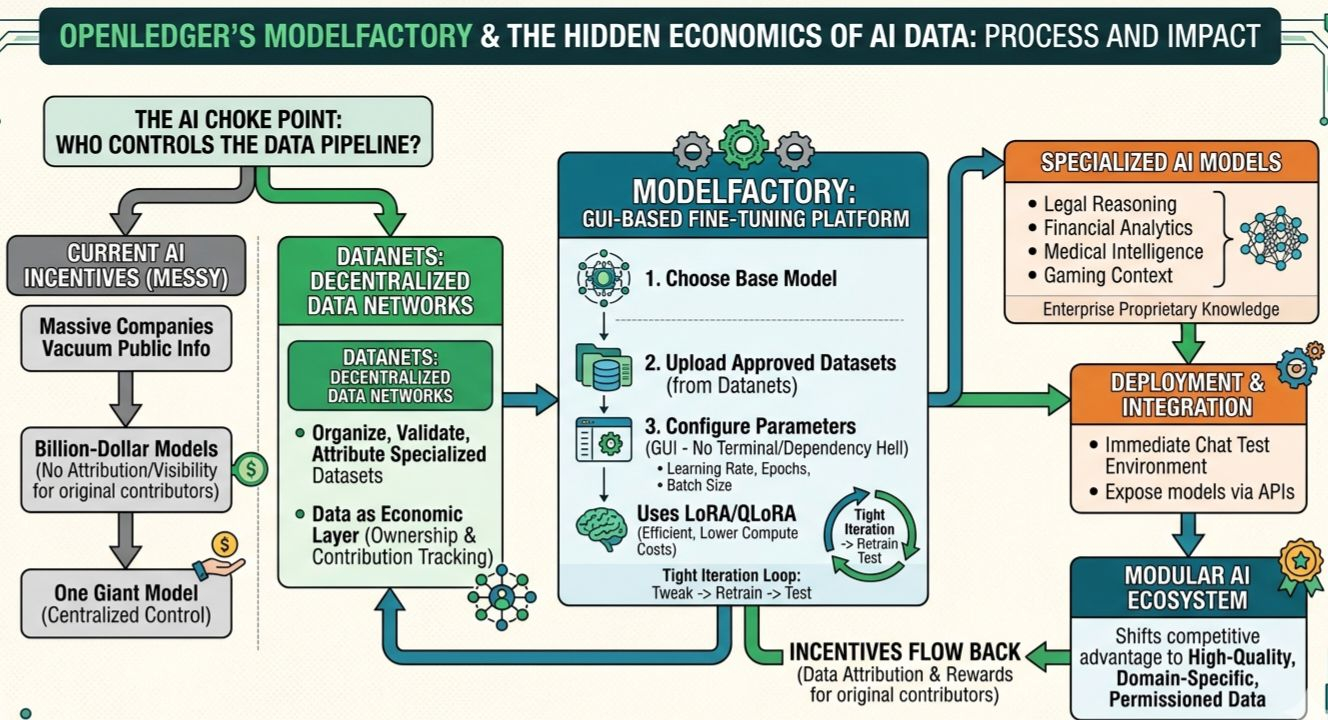
That’s where OpenLedger’s broader architecture starts to get interesting. The project revolves around something it calls Datanets, decentralized data networks designed to organize, validate, and attribute specialized datasets. Instead of datasets floating around as disconnected ZIP files uploaded to obscure repositories, the idea is to treat data as an economic layer with ownership and contribution tracking attached to it.
ModelFactory is essentially where those datasets become operational.
That distinction matters more than most people realize because AI’s current incentive structure is… messy, to put it politely. Massive companies vacuum up public information, train billion-dollar models on it, and the original contributors rarely see attribution, visibility, or compensation. Writers, researchers, artists, developers, online communities — they collectively generate the raw material powering modern AI systems while remaining largely invisible inside the economics of the stack.
OpenLedger is betting that this imbalance eventually becomes unsustainable.
Whether they’re right is another question entirely. Infrastructure narratives in crypto have a habit of sounding brilliant long before they face real-world scale. Still, at least this is aimed at an actual bottleneck instead of inventing another speculative token layer nobody needed.
The mechanics themselves are fairly straightforward. Users can select a base model, configure training settings through the GUI, and fine-tune using permissioned datasets already integrated into the ecosystem. Parameters like learning rate, epochs, and batch sizes are exposed directly in the interface instead of buried inside scripts. The platform also supports LoRA and QLoRA, which is important because efficient fine-tuning is rapidly becoming the default approach for smaller organizations.
Full retraining is brutally expensive. Everyone likes talking about trillion-parameter models until the GPU bill arrives.
LoRA and QLoRA reduce the computational overhead dramatically by updating smaller subsets of parameters rather than retraining the entire model stack from scratch. That makes experimentation feasible for startups, independent researchers, niche communities, and smaller companies that simply don’t have hyperscaler budgets lying around. In practice, this is probably one of the more pragmatic design choices inside the platform because compute remains one of AI’s biggest centralizing forces.
And the interesting part is how all these pieces connect together.
OpenLedger isn’t only building model tooling. It’s trying to construct an ecosystem where datasets, contributors, trainers, models and applications can operate as separate but interoperable layers. ModelFactory becomes the operational bridge between those layers. Datanets provide the structured data. Fine-tuning infrastructure turns that data into specialized models. APIs expose those models externally. Incentives flow back through the system.
You can see the broader thesis forming underneath it: decentralized AI probably won’t emerge from one giant protocol replacing OpenAI overnight. More likely, it evolves into modular infrastructure where ownership, training, inference, and applications become composable services.
At least that seems to be the direction OpenLedger is positioning itself around.
One small but surprisingly important feature is the integrated chat environment after training. Users can fine-tune a model and immediately interact with it inside the platform instead of exporting everything into another testing workflow. That tight iteration loop matters because fine-tuning is rarely clean on the first attempt. You tweak parameters, test responses, adjust the dataset, retrain, repeat. Faster feedback cycles make experimentation dramatically more usable, especially for people who aren’t hardcore ML engineers.
There’s also API support for external integrations, which means these specialized models can eventually plug into broader products, autonomous agents, internal business systems, or custom workflows. That part feels less flashy in demos but probably more important long term. Infrastructure companies rarely look exciting early on. Neither did cloud tooling before AWS quietly became one of the most important businesses in modern tech.
And that’s probably the most interesting thing about ModelFactory overall: it doesn’t feel obsessed with hype.
The platform is focused on operational AI layers, dataset coordination, permission management, efficient fine-tuning, attribution systems, deployment workflows. The unglamorous stuff. But historically, that’s where durable value tends to accumulate once markets mature and the speculative excitement cools off.
Most people using future AI applications will never think about permissioned datasets or LoRA pipelines. They won’t care how the underlying model was trained or who contributed the data. Consumers almost never care about infrastructure until infrastructure breaks.
But the companies building those hidden layers often end up shaping the entire ecosystem anyway.
ModelFactory may or may not succeed at scale. The AI sector moves absurdly fast, and infrastructure bets can disappear just as quickly as they appear. Still, compared to the endless flood of projects stapling “AI” onto whitepapers for attention, OpenLedger at least seems to understand where the real friction still exists.
And right now, the friction isn’t a lack of AI apps.
It’s the machinery underneath them.
