Market's been strange all week. Not crashing, not running just sitting there like it's waiting for something. I had a few hours free so instead of watching charts I ended up going deep on something I'd been avoiding.
I started poking around @OpenLedger mostly because someone in a group chat called it "just another AI data marketplace" and something about that framing bothered me. So I opened the PoA whitepaper and started reading properly.
And okay, here's what shifted for me.
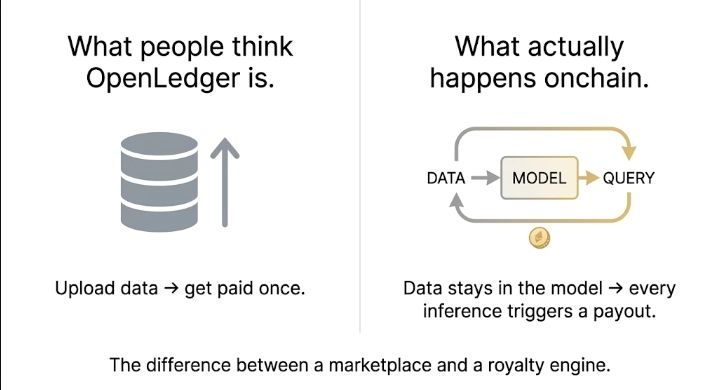
Everyone talks about OpenLedger as if it's a place where you upload data and maybe get paid. Like a Shutterstock for AI training sets. That's how it gets described, that's how people price the token and that's probably why most traders shrug at it. A marketplace. Fine. Whatever.
But the actual mechanism is different. The payout doesn't happen when you upload. It happens at inference time every single time a model runs a query and your data measurably influenced the output. The protocol computes influence scores post inference using what the whitepaper calls influence function approximations for smaller models and suffix array token attribution for large language models.
It checks the output against compressed training corpora, assigns a contribution weight to each datanet, then routes a share of the inference fee back to the contributor. All onchain. Tied to that specific query.
I thought this was just a training time credit system. It's not. It's closer to a royalty engine that runs on every API call.
That realization changes how you think about who actually benefits here. A data contributor doesn't need to be a developer or a validator. They just need their data inside a model that gets used. The more queries, the more revenue. Passively, continuously, proportionally.
Hmm… but here's where I slowed down.
The whole thing only works if AI developers actually build on OpenLedger and route real inference traffic through it. Right now and I checked most datanets appear to still be in contribution phase. People seeding datasets, building leaderboard rankings.
That's Phase 1. Production inference, the part where the payout loop actually closes, needs AI builders on the demand side pulling from those datanets at scale.
I'm not fully convinced that side materializes quickly. The OPEN token is sitting around $0.26 with $24M daily volume, which is fine, but it doesn't tell you whether that's real inference demand or just trading activity. And 61% of total supply allocated to early ecosystem subsidies suggests the team knows organic pull isn't there yet.
So the design is genuinely interesting. The royalty at inference mechanic is not something I've seen done this cleanly at the protocol level. But a royalty engine with no one sending queries is just… infrastructure waiting in a room.
Anyway. I'll probably sit on this one for a while and see if the developer adoption metrics start showing up in onchain activity. The market still feels like it's waiting too, honestly. Might just be that kind of month.