Nobody talks about the verification problem honestly. The AI industry has spent the last three years celebrating model capabilities while completely ignoring the question of whether the data those models trained on was accurate representative and ethically sourced in the first place. I find it genuinely strange that we have rigorous benchmarks for model output quality but almost zero standardized infrastructure for auditing the input quality that produced those outputs. Thats not an oversight thats a choice and its a choice that benefits the organizations currently controlling those data pipelines.
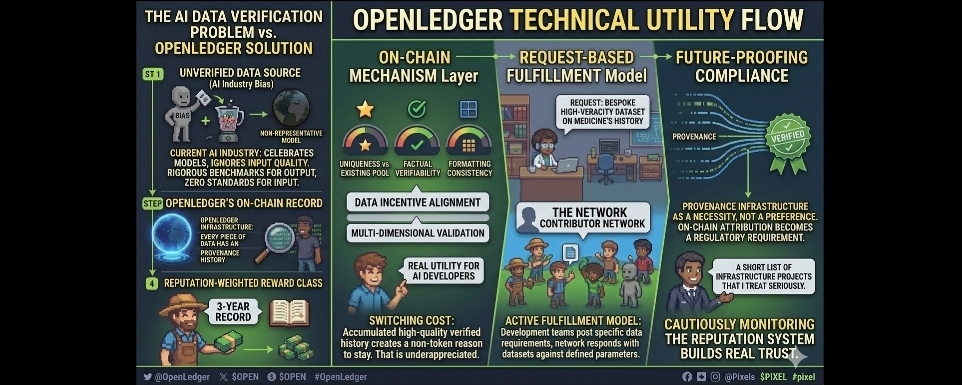
$OPEN is addressing something I think about a lot which is the difference between a data marketplace and a data verification network. Most decentralized data projects are marketplaces meaning they create a venue for data to change hands between contributors and buyers without taking any real responsibility for what the data actually contains or whether it should be trusted. OpenLedger is building verification infrastructure meaning every piece of data that enters the training pool has an on-chain record of who submitted it what quality score it received from independent validators and what its provenance history looks like. That distinction is not semantic it changes the entire value proposition for enterprise AI buyers.
And here is the technical detail most analysts gloss over. The validation scoring in OpenLedger isnt binary where data either passes or fails. It operates on a weighted quality spectrum where submissions receive scores that reflect multiple dimensions including uniqueness against existing pool content factual verifiability against reference sources and formatting consistency for training compatibility. That multi-dimensional scoring feeds directly into the contributor reputation system meaning a contributor who scores consistently high across all three dimensions accumulates reputation weight faster than someone who scores high on only one. This creates real incentive alignment between contributor behavior and actual dataset quality.
I have been watching AI data projects since 2021 and the single biggest pattern I have observed is that contributor retention collapses when token rewards drop. I dont think @OpenLedger has fully solved that problem but I think their reputation-weighted reward structure at least creates a class of contributors who have a non-token reason to stay which is their accumulated on-chain reputation score. A contributor who has built three years of verified high-quality submission history inside the OpenLedger protocol has something that doesnt exist anywhere else and cant be replicated on a competing platform overnight. That switching cost is underappreciated.
My honest frustration with how this project gets discussed is that most coverage treats it as an AI narrative token rather than as infrastructure with genuine utility mechanics. The token reward distribution being tied to contribution quality and validator accuracy is not a marketing claim its an on-chain mechanism that either works or doesnt and I think that testability is actually what makes it more credible than competitors who rely on vague promises about future ecosystem growth. Either the quality scores correlate with real utility for AI developers or they dont and the market will figure that out faster than any whitepaper revision can hide.
But I want to push back on something I see in the bullish commentary around $OPEN. People keep pointing to the size of the AI training data market as if total addressable market is the same thing as accessible market. Its not. The organizations spending the most money on training data right now are large AI labs with established vendor relationships legal teams that require contractual data warranties and compliance requirements that a decentralized protocol has never had to satisfy before. Closing that gap is not just a technical challenge its a sales motion that requires a completely different organizational muscle than building protocol architecture and I havent seen enough evidence yet that the team is resourced to execute both simultaneously.
The piece of the OpenLedger design that I keep returning to is the request-based dataset fulfillment model. Rather than forcing AI developers to browse a static marketplace and hope something useful exists the protocol allows development teams to post specific data requirements and the contributor network responds to those requests against defined quality parameters. This active fulfillment model is meaningfully different from passive data storage because it means the network can theoretically produce bespoke training datasets rather than just redistributing what already exists. If that mechanism scales with real developer demand it solves the relevance problem that kills most open data projects before they reach maturity.
What I feel more than think is that the AI industry is about five years away from a serious regulatory reckoning over training data sourcing and the organizations that built verifiable data provenance infrastructure early will look prescient rather than idealistic when that reckoning arrives. I dont have perfect confidence that @OpenLedger will be the protocol that captures that moment. There are execution risks I have already described and competitive risks from well-funded centralized players who can move faster when regulatory winds shift. But the underlying thesis that on-chain data attribution will become a compliance necessity rather than a philosophical preference is one I hold with more conviction than almost any other structural bet I have made about where this industry is heading.
The network is still early and I treat early honestly which means I watch more than I commit and I update my view based on what actually happens rather than what roadmaps promise. What I will say is that $OPEN is on a short list of AI infrastructure projects that I think about seriously enough to monitor on a weekly basis and that list is shorter than most people assume.
