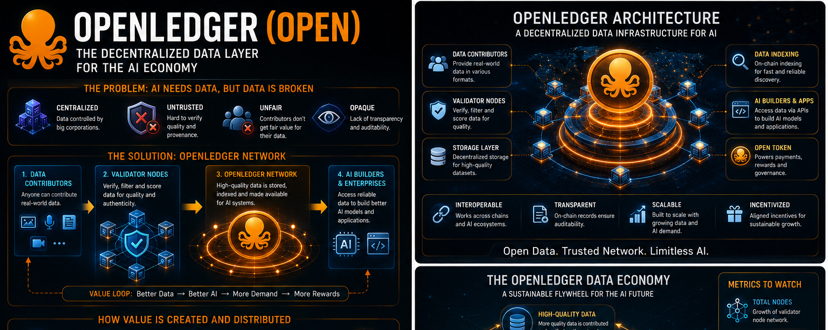
Khi phân tích sâu hơn về OpenLedger (OPEN), tôi nhận ra rằng dự án này đang đánh vào một “nút thắt” cực kỳ quan trọng của ngành AI: dữ liệu chất lượng cao nhưng phi tập trung.
Hiện tại, phần lớn dữ liệu AI nằm trong tay các tổ chức tập trung, dẫn đến rủi ro về quyền riêng tư, thiên lệch dữ liệu và thiếu minh bạch. #OpenLedger giải quyết vấn đề này bằng cách xây dựng một mạng lưới nơi dữ liệu được thu thập, xác thực và phân phối thông qua các validator node. Điều này không chỉ đảm bảo độ tin cậy mà còn tạo ra một hệ sinh thái công bằng hơn cho người đóng góp.
Điểm tôi đánh giá cao là mô hình incentive của $OPEN token. Token không chỉ dùng để thanh toán mà còn đóng vai trò thúc đẩy toàn bộ vòng đời dữ liệu: từ đóng góp → xác thực → sử dụng → tái phân phối giá trị. Nếu cơ chế này vận hành hiệu quả, nó sẽ tạo ra một “data economy” thực sự, nơi mọi bên đều có động lực tham gia.

Tuy nhiên, thách thức lớn nhất vẫn là mở rộng quy mô: số lượng node, đối tác AI, và lượng dữ liệu thực tế. Đây sẽ là các chỉ số tôi theo dõi trong thời gian tới. Nếu những yếu tố này tăng trưởng đồng bộ, OpenLedger hoàn toàn có thể trở thành một trong những dự án nền tảng của AI + Web3.
