Lange Zeit hat uns das Internet gelehrt, dass Informationen von Natur aus frei sein wollen. Alles bewegte sich in Richtung Offenheit, endloses Kopieren, reibungsloses Teilen und Plattformen, die durch das Aufnehmen menschlicher Aktivitäten skalierten. Doch künstliche Intelligenz verändert diese Logik auf subtile und unangenehme Weise. Informationen sind nicht mehr nur Informationen. In der Ära der KI werden Informationen zu Arbeit. Sie werden zu Infrastruktur. Sie werden zu Kapital.
Dieser Wandel ist genau der Moment, an dem OpenLedger ins Spiel kommt.
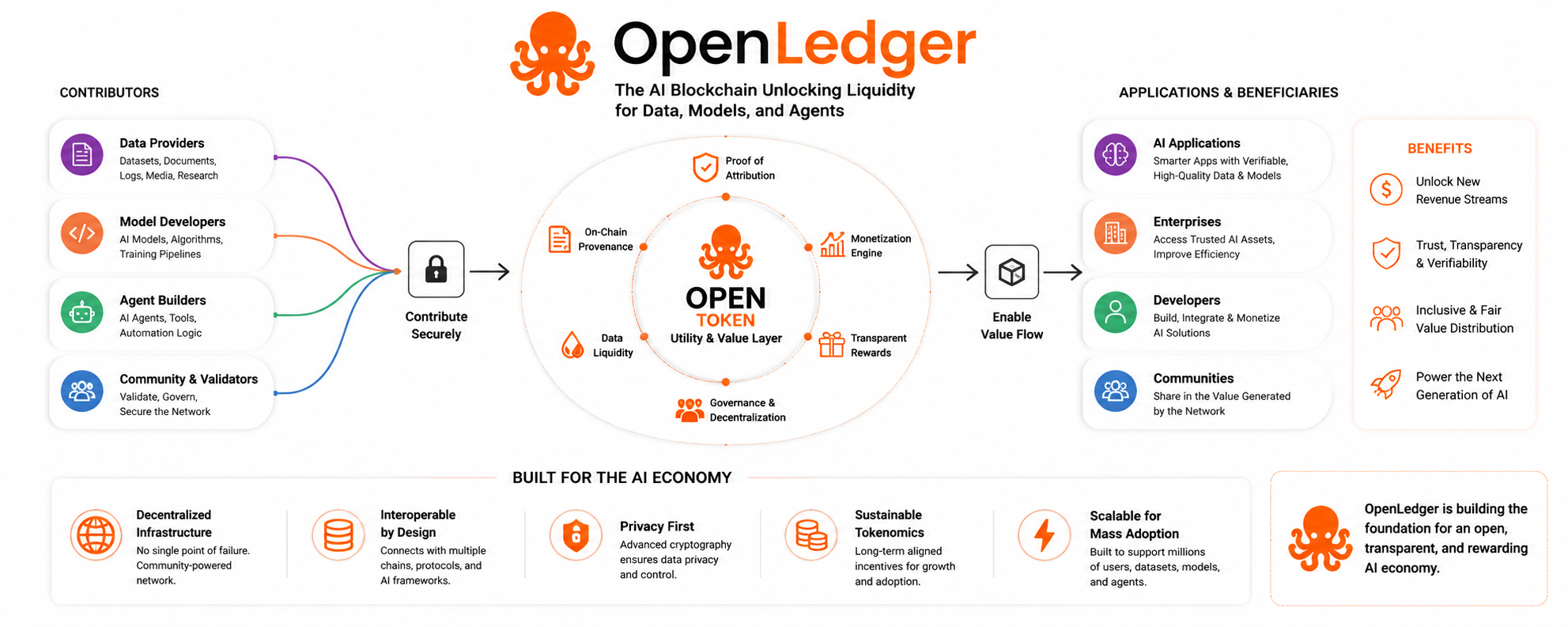
Auf den ersten Blick sieht OpenLedger aus wie ein weiteres Projekt, das an der Schnittstelle von KI und Blockchain sitzt – zwei Branchen, die bereits mit Hype, übergroßen Versprechungen und futuristischer Sprache überlastet sind. Aber unter der Markenbildung und Tokenomics steckt eine ernsthaftere Idee. Das Projekt versucht, ein wachsendes Ungleichgewicht in der KI-Wirtschaft zu lösen: Millionen von Menschen tragen mit Daten, Expertise und Verhaltenssignalen bei, die intelligente Systeme trainieren, doch fast keiner dieser Beitragsleistenden teilt den wirtschaftlichen Wert, der danach geschaffen wird.
Jedes KI-Modell basiert auf verborgenem menschlichen Aufwand. Forscher produzieren Papers. Entwickler schreiben Code. Gemeinschaften erzeugen Gespräche. Experten erstellen spezialisierte Datensätze. Ganze Industrien speisen unbewusst jeden Tag maschinelle Lernsysteme. Doch sobald diese Systeme profitabel werden, konzentrieren sich die Belohnungen normalerweise rund um eine Handvoll Unternehmen, die über ausreichend Rechenleistung, Kapital und Infrastruktur verfügen, um die Ausgaben zu kommerzialisieren.
OpenLedger versucht, diese Struktur herauszufordern, indem es Daten, Modelle und KI-Agenten als wirtschaftliche Vermögenswerte behandelt, die verfolgt, monetarisiert und mit Beitragsleistenden verbunden werden können. Das klingt auf dem Papier technisch, aber philosophisch ist es tatsächlich eine Frage des Eigentums. Wenn künstliche Intelligenz zunehmend von der Menschheit selbst lernt, wem sollte dann der Nutzen aus der Intelligenz zustehen, die sie produziert?
Der Zeitpunkt dieser Idee ist nicht zufällig. KI tritt jetzt in eine andere Phase ein. Die erste Welle der künstlichen Intelligenz drehte sich um die Nachweisführung von Fähigkeiten. Können Maschinen schreiben? Können sie Bilder generieren? Können sie schließen, zusammenfassen, vorhersagen oder imitieren? Diese Phase erzeugte Aufregung. Die nächste Phase ist komplizierter, denn es geht um Wirtschaft. Wer kontrolliert die Modelle? Wer besitzt die Daten? Wer wird entschädigt? Wer trägt die rechtliche Verantwortung? Wer überprüft, woher die Informationen stammen? Diese Fragen werden unmöglich zu ignorieren.
Hier beginnt OpenLedger weniger wie ein spekulatives Krypto-Experiment und mehr wie der Versuch, eine Buchhaltungsinfrastruktur für die Intelligenz selbst zu schaffen.
Die meisten KI-Systeme von heute funktionieren wie Black Boxes. Daten fließen hinein, Vorhersagen kommen heraus, und der interne Prozess bleibt schwer zu interpretieren. Wir wissen selten, welcher Datensatz eine Antwort beeinflusst hat oder welche Beitragsleistenden ein System genauer gemacht haben. In einigen Fällen können sogar die Unternehmen, die die Modelle erstellen, nicht vollständig erklären, warum bestimmte Ausgaben erscheinen. Diese Opazität schafft Probleme nicht nur für das Vertrauen, sondern auch für die Wirtschaft. Wenn der Beitrag nicht gemessen werden kann, wird eine faire Verteilung der Entschädigung unmöglich.
Die Kernvision von OpenLedger dreht sich um Attribution. Das Projekt spricht von "Proof of Attribution", was im Wesentlichen bedeutet, Mechanismen zu schaffen, die nachverfolgen, wie Daten und Beitragsleistende KI-Systeme und Ergebnisse beeinflussen. Das mag abstrakt klingen, aber die Implikationen sind enorm. Es führt die Möglichkeit ein, dass KI letztendlich weniger wie eine Extraktionsmaschine und mehr wie eine Partizipationswirtschaft funktionieren könnte.
Stellen Sie sich eine Zukunft vor, in der medizinische Forscher Onkologiedatensätze in ein dezentrales KI-Netzwerk einbringen. Jedes Mal, wenn diese Datensätze die diagnostischen Modelle verbessern, die von Krankenhäusern oder Pharmaunternehmen verwendet werden, fließt der Wert zurück zu den Beitragsleistenden. Oder stellen Sie sich spezialisierte juristische Datensätze vor, die kontinuierlich Tantiemen generieren, wann immer KI-Systeme sie zur Erstellung juristischer Analysen verwenden. In einer solchen Welt hört Daten auf, eine wegwerfbare Ressource zu sein, und beginnt, ein renditeträchtiger digitaler Vermögenswert zu werden.
Diese Idee verändert die emotionale Beziehung zwischen Menschen und KI. Derzeit haben viele das Gefühl, dass künstliche Intelligenz stillschweigend menschliche Kreativität und Expertise ohne Erlaubnis, Attribution oder Entschädigung absorbiert. Die Philosophie von OpenLedger drängt auf ein anderes Modell, in dem Intelligenz wirtschaftlich nachverfolgbar wird. Anstatt in der Maschine zu verschwinden, bleiben die Beitragsleistenden im System sichtbar.
Die tiefere Einsicht hier ist, dass die zukünftige KI-Wirtschaft möglicherweise weniger von Roh-Rechenleistung abhängt, als die Menschen derzeit annehmen. Open-Source-Modelle werden zunehmend zugänglich. Mächtige Grundmodelle verbreiten sich schnell. Im Laufe der Zeit könnte die echte Knappheit nicht bei den Modellen selbst liegen, sondern bei hochwertigen, vertrauenswürdigen, domänenspezifischen Daten.
Das schafft eine völlig andere Marktdynamik.
Die nächste Generation wertvoller KI-Systeme könnte nicht riesige universelle Modelle sein, die versuchen, alles zu wissen. Stattdessen könnten es spezialisierte Intelligenz-Netzwerke sein, die auf hochgradig kuratierten Datensätzen aus Branchen wie Medizin, Finanzen, Recht, Logistik, Ingenieurwesen, Landwirtschaft oder Wissenschaft trainiert werden. Diese Systeme werden basierend auf der Qualität und Einzigartigkeit ihrer Datenökosysteme konkurrieren.
OpenLedger positioniert sich genau für diese Zukunft. Das Konzept der "Datanets" spiegelt diesen Wandel wider. Anstatt KI als eine einzige zentralisierte Intelligenz zu betrachten, stellt das Projekt Netzwerke spezialisierter Datensätze vor, die maßgeschneiderte Modelle und autonome Agenten speisen. In diesem Rahmen wird Datenliquidität zu einer der definierenden wirtschaftlichen Kräfte der KI-Ära.
Dieser Begriff – Datenliquidität – klingt fast harmlos, bis man darüber nachdenkt, was er tatsächlich bedeutet. Liquidität gehörte traditionell zur Finanzwelt. Sie bezieht sich darauf, wie effizient Vermögenswerte bewegt werden und Wert erzeugen. OpenLedger wendet diese Logik auf die Intelligenz selbst an. Es versucht, statische Datensätze in aktive wirtschaftliche Ressourcen zu transformieren, die zirkulieren, Renditen erzeugen und innerhalb dezentraler Märkte teilnehmen können.
Das könnte schließlich die Art und Weise umgestalten, wie Gesellschaften über das Eigentum an Wissen denken. Ganze Industrien sind auf isolierten Datensilos aufgebaut, die selten effizient interagieren. Krankenhäuser verfügen über wertvolle medizinische Informationen. Regierungen kontrollieren massive öffentliche Datensätze. Unternehmen sammeln Verhaltens- und Betriebsdaten in enormem Maßstab. Die meisten dieser Vermögenswerte bleiben wirtschaftlich untätig außerhalb ihrer unmittelbaren Umgebungen.
Wenn Systeme wie OpenLedger erfolgreich sind, könnten Datensätze selbst programmierbare finanzielle Primitiven werden. Gemeinschaften, Institutionen und sogar Nationen könnten letztendlich um KI-Datenhoheit konkurrieren, ähnlich wie Länder einst um natürliche Ressourcen oder industrielle Kapazitäten konkurrierten.
Es gibt auch eine politische Ebene, die all dem zugrunde liegt. Künstliche Intelligenz wird zunehmend zentralisiert. Eine kleine Anzahl von Unternehmen dominiert die Entwicklung fortgeschrittener Modelle, da die Eintrittsbarrieren so hoch sind. Recheninfrastruktur, Forschungstalente, proprietäre Datensätze und Kapitalverteilung verstärken alle diese Dominanz. Viele Menschen in der Technologie sorgen sich stillschweigend, dass KI sich zu einer der zentralisiertesten Industrien der modernen Geschichte entwickeln könnte.
OpenLedger stellt eine Antwort auf diese Angst dar. Es schlägt vor, dass die Produktion von Intelligenz wirtschaftlich dezentralisiert werden kann, nicht nur technisch. Anstatt den Wert ausschließlich um Modellbesitzer zu konzentrieren, versucht es, den Wert über das Ökosystem der Beitragsleistenden zu verteilen, die KI überhaupt erst möglich machen.
Ob diese Vision Wirklichkeit wird, ist eine ganz andere Frage.
Die technischen Herausforderungen sind enorm. Attribution innerhalb neuronaler Netze ist unglaublich schwierig, da moderne KI-Systeme probabilistisch und tief komplex sind. Nachzuvollziehen, wie ein Datensatz genau eine Ausgabe beeinflusst hat, ist nicht einfach. Es gibt auch große Fragen zu Verifizierung, Governance, Skalierbarkeit, Akzeptanz und regulatorischer Compliance. Viele Blockchain-Projekte beschreiben ehrgeizige Zukunftsvisionen, die niemals in praktische Ökosysteme materialisieren.
Und doch, selbst mit diesen Ungewissheiten spiegelt OpenLedger einen wichtigen historischen Übergang wider.
Das Internet monetisierte Aufmerksamkeit. Soziale Medien monetisierten Verhalten. Blockchain monetisierte Vertrauen. Künstliche Intelligenz beginnt, Kognition selbst zu monetisieren.
Das verändert die Struktur des wirtschaftlichen Lebens auf Arten, die die Menschen gerade erst zu verstehen beginnen.
Die wertvollsten Systeme des nächsten Jahrzehnts könnten nicht einfach die intelligentesten Modelle sein. Es könnten die Systeme sein, die wissen, wie man Beiträge misst, Belohnungen verteilt und nachhaltige wirtschaftliche Beziehungen zwischen Menschen und Maschinen schafft.
Das ist die tiefere Bedeutung von OpenLedger. Es versucht nicht nur, eine weitere Kryptowährung zu schaffen. Es versucht, eine finanzielle Infrastruktur rund um die Schaffung von Intelligenz aufzubauen. Ob das Projekt letztendlich erfolgreich oder gescheitert ist, die Frage, die es aufwirft, wird unvermeidlich.
Wenn Maschinen kontinuierlich aus menschlichem Wissen lernen, wem gehört der Wert, der danach entsteht?
Aktuell gibt es keine klare Antwort. Aber Projekte wie OpenLedger deuten darauf hin, dass die zukünftige KI-Wirtschaft möglicherweise irgendwann eine Antwort verlangen wird.