
when i realized ai has never actually known where it learned anything from
just noticed something while going through openledger's protocol documentation that i could not stop thinking about the way proof of attribution actually works at the consensus level is more unsettling than the headline suggests.
most people read cryptographically links AI outputs to their original data sources and move on. i actually sat down and traced what that statement means structurally because once you understand the mechanic behind it you start questioning every ai system you've ever used without asking questions.
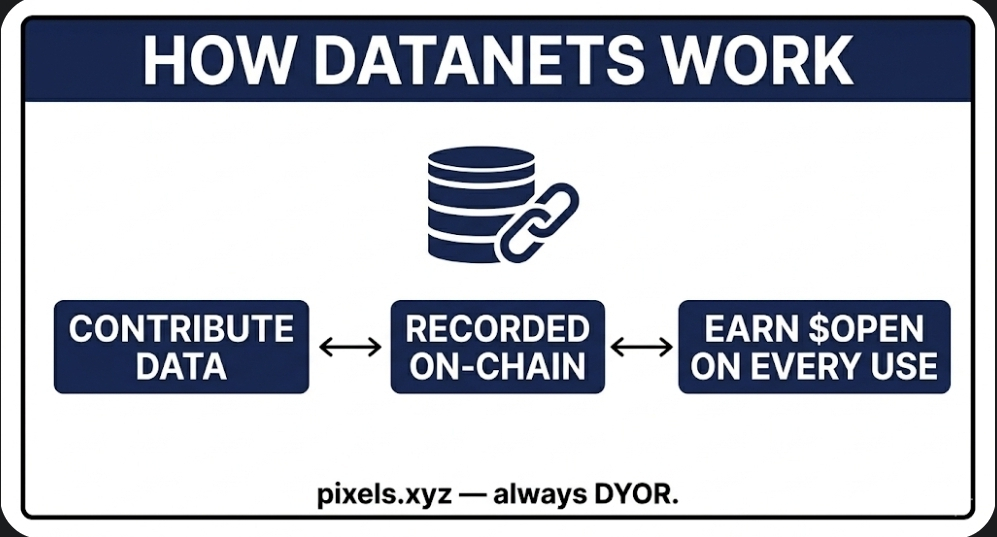
the problem it is solving is one i had completely misunderstood. i used to think Ai transparency was mostly a political argument bias complaints fairness debates who controls the models. i never questioned the technical side. i assumed somewhere, somehow, there was a record of what went into these systems. there isn't. when any large model produces an output, there is no record of which data contributed to that response. the training process collapses everything into weights numerical parameters that carry influence without carrying identity. the original contributors disappear the moment their data enters the pipeline.
the setup is what makes proof of attribution structurally different. PoA is not a feature added onto openledger it is the consensus mechanism. every data contribution and every model output is cryptographically linked on chain before anything else happens. the linkage is not reconstructed after the fact. it is embedded at the moment of contribution, creating a provenance record that cannot be altered retroactively. when a model trained on your data gets queried the chain can be walked back output to model model to training data training data to original contributor. every step auditable by anyone at any time.
what this means structurally for the attribution layer
what makes this different from how centralized ai handles provenance is the removal of discretion entirely. in the current ai industry we credit our data sources is a statement a company makes and can revise whenever it becomes inconvenient. there is no enforcement mechanism. there is no record that exists independently of the organization making the claim. proof of attribution removes that discretion at the architecture level once a contribution is recorded on chain it exists independently of the founding team independently of any business incentive that emerges later. the blockchain does not negotiate.
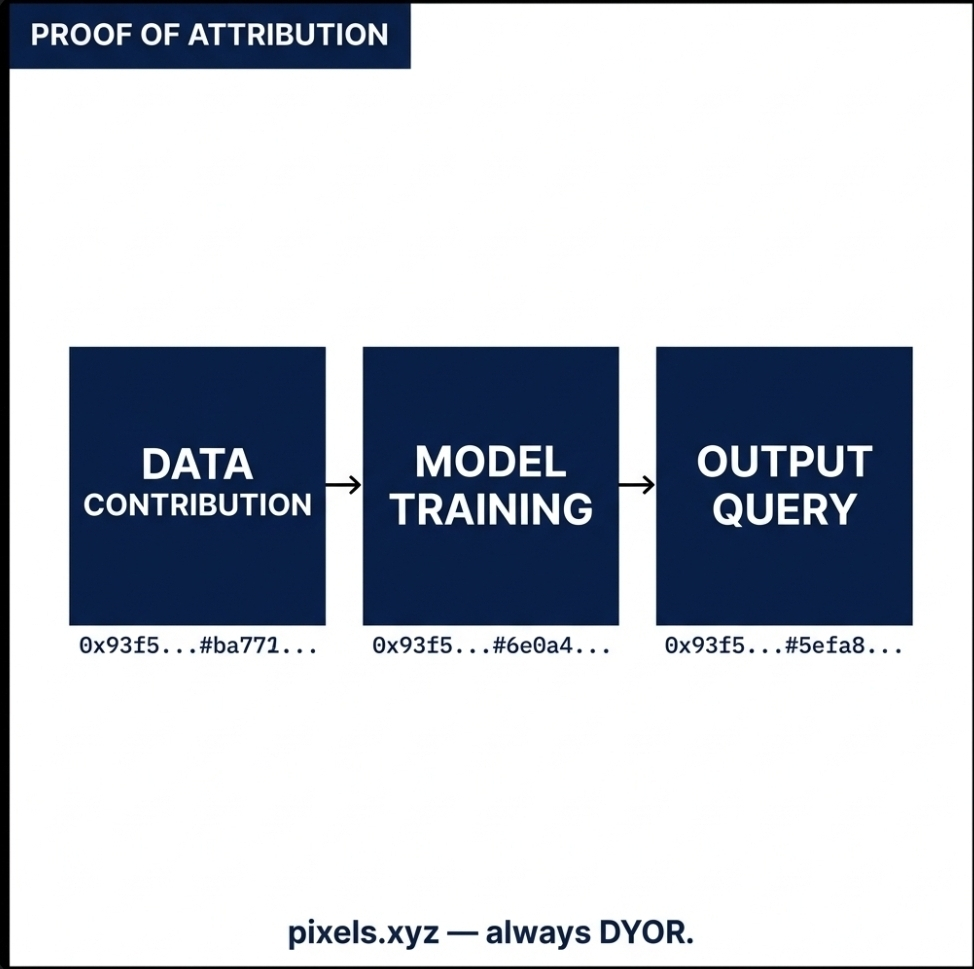
the part that surprised me is how this changes the economic position of data contributors specifically. i had assumed monetization in ai meant building a product on top of a model. i never considered that the data layer itself could be the monetization point. when a model trained on your dataset gets queried OPEN tokens are distributed to you automatically through a smart contract. no platform deciding your cut. no quarterly payout that a centralized system controls. the on-chain record determines the reward and the contract executes it without requiring anyone's approval. that is genuinely new infrastructure.
why the cryptographic linkage matters beyond philosophy
what im not entirely sure about is how the attribution weighting actually works at scale. the protocol records contribution but when thousands of datasets influence a single model how does the smart contract calculate proportional reward per contributor? does a dataset with high query overlap earn more than one with broader but shallower influence? i went back through the documentation looking for this breakdown and the exact methodology is not publicly detailed yet. that formula matters enormously for whether small niche dataset contributors can actually earn meaningfully or whether the rewards concentrate around the largest, most frequently accessed datanets.
what they get right is the architecture. embedding attribution at the consensus layer rather than the application layer is the correct design decision. the incentive loop is honest better data produces better models better models get queried more more queries trigger more rewards to the Original contributors. that alignment is real.
still figuring out whether the reward distribution methodology protects the long tail of smaller contributors or whether High volume datanets end up capturing most of the value the docs do not answer that clearly yet
