Ich habe angefangen, OpenLoRA wegen einer sehr langweiligen Frage zu beachten.
Es geht nicht darum, wie intelligent der AI-Agent sein wird.
Es geht nicht darum, wie OpenLedger die Datenökonomie freischalten wird.
Sondern: Wenn es in Zukunft tausende spezialisierte Modelle gibt, wer wird sie dann wirklich genug nutzen, damit sie überleben?
Das klingt etwas ernüchternd. Aber Crypto hat mir eine schmerzhafte Lektion erteilt: Es ist immer einfacher, ein Angebot zu schaffen, als eine Nachfrage zu erzeugen. Token zu erstellen ist einfacher, als einen Nutzen zu schaffen. Ein Asset zu schaffen ist einfacher, als einen Grund zu finden, warum andere es täglich nutzen sollten. GameFi hatte früher viel zu viele Items ohne echte Spieler. DeFi hatte viel zu viele Vaults, die nur von Emissionen lebten. AI Crypto könnte diesen Fehler komplett wiederholen, nur dass es diesmal nicht NFTs oder Vaults sind, die im Lager liegen, sondern kleine Modelle, die als „spezialisiert“ bezeichnet werden.
Zuerst wollte ich diesem Narrativ auch zu schnell Glauben schenken.
Spezialisierte KI klingt sehr sinnvoll. Ein Modell für die Prüfung von Smart Contracts. Ein Modell für Trading-Forschung. Ein Modell für rechtliche Workflows. Ein Modell für jede Gemeinschaft mit eigenen Daten. OpenLedger hat Datanets, um spezialisierte Daten zu sammeln, ModelFactory, um zu fine-tunen, und Proof of Attribution, um Beiträge zu erfassen. Auf dem Papier sieht alles ziemlich gut zusammen aus.
Aber die Schönheit auf dem Papier übersieht oft einen sehr alltäglichen Satz: Wird dieses Modell oft genug aufgerufen?
OpenLoRA hat mich genau hier innehalten lassen.
LoRA kann einfach als eine leichte Anpassungsschicht verstanden werden, die auf das ursprüngliche Modell aufgesetzt wird, anstatt ein großes Modell von Grund auf neu zu trainieren. OpenLoRA wird im Whitepaper als ein Multi-Tenant-System beschrieben, um die feingetunten LoRA-Modelle mit geringem Overhead zu bedienen. Dieser Datenpunkt klingt trocken, aber er ist wichtig, denn OpenLedger muss nicht nur Modelle erstellen. Es muss auch sicherstellen, dass viele kleine Modelle zu einem ausreichend niedrigen Preis betrieben werden können.
Früher betrachtete ich dieses Detail als eine Optimierung der Infrastruktur. Jetzt denke ich, es ist mehr ein Test.
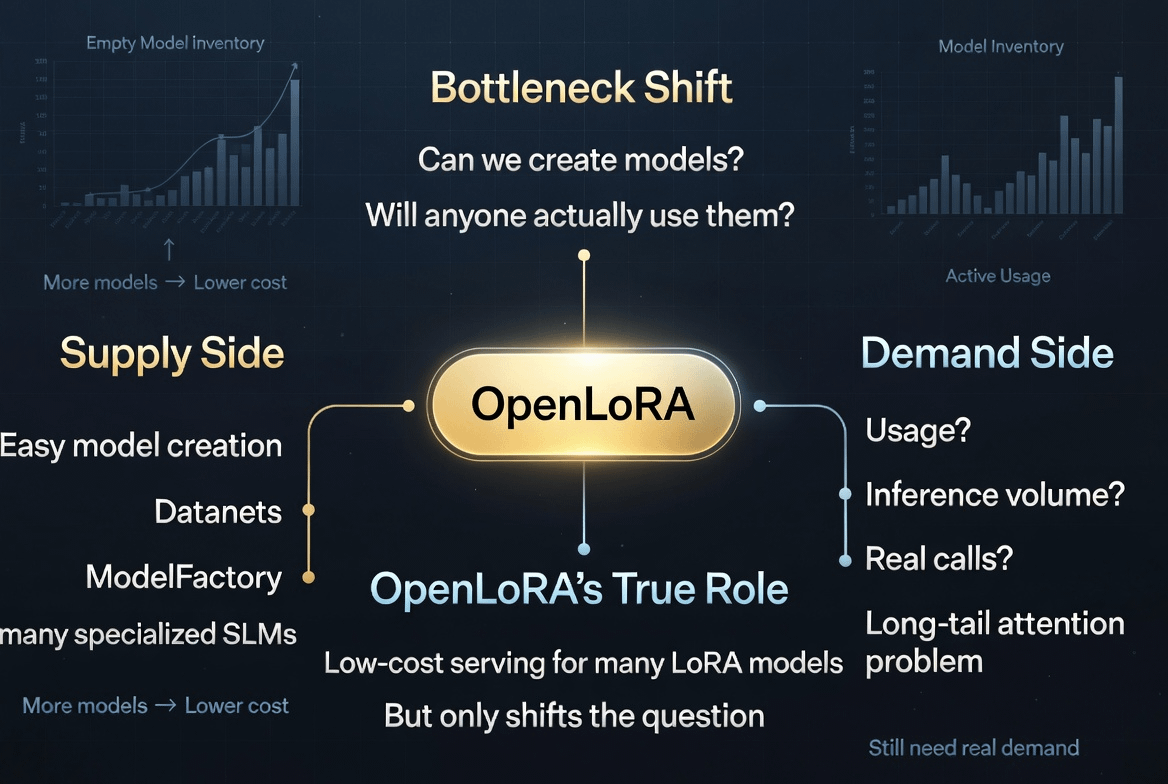
Wenn die Betriebskosten immer noch zu hoch sind, haben wir immer einen Grund zur Rechtfertigung: spezialisierte KI hat sich noch nicht entfaltet, weil die Infrastruktur teuer ist, das Deployment schwierig ist und kleine Modelle nicht in der Lage sind, ihre Kosten selbst zu tragen. Aber wenn OpenLoRA diese Reibung verringert, stellt sich die echte Frage: Gibt es eine echte Nachfrage nach Long-Tail-KI, oder gibt es nur ein Long-Tail-Angebot?
Hier sehe ich, dass OpenLoRA interessanter ist als nur die technische Seite davon.
Es beweist nicht, dass OpenLedger eine nachhaltige KI-Wirtschaft haben wird. Es verschiebt nur den Engpass an einen schwerer zu vermeidenden Ort. Von „Können viele kleine Modelle betrieben werden?“ zu „Welches kleine Modell hat echte Nutzung?“ Von „Sind die Betriebskosten zu hoch?“ zu „Ist das Inferenzvolumen dick genug, um bedeutende Belohnungen zu bieten?“ Von „Wer erstellt die Modelle?“ zu „Wer ruft dieses Modell ein zweites, zehntes, tausendstes Mal auf?“
Denn im OpenLedger hat ein spezialisiertes Modell nur dann eine wirtschaftliche Existenz, wenn es genutzt wird. Inferenz ist nicht nur die Antwort von KI. Sie ist der Punkt, an dem Gebühren gezahlt werden, Attribution Daten hat, um gemessen zu werden, und Belohnungen die Möglichkeit haben, an den Beitragenden zurückzukommen. Wenn die Nutzung dünn ist, kann Proof of Attribution in der Logik zwar korrekt sein, aber die Belohnung für die Datenbeiträge könnte zu gering sein, um das Verhalten zu ändern. Fairness auf dem Papier wird nicht automatisch zu Anreizen im echten Leben.
Hier ist der Punkt, den ich denke, dass viele Leute übersehen werden.
Alle reden gerne darüber, wie man „Liquidität für Daten und Modelle freischaltet“. Aber Liquidität entsteht nicht einfach, weil ein Asset definiert ist. Sie tritt auf, wenn Leute es nutzen wollen, bereit sind, dafür zu zahlen und zurückkommen möchten. Andernfalls kann das Ökosystem viele Adapter, viele Modelle und viele schöne Dashboards haben, aber sie ähneln einem Markt, der die ganze Nacht geöffnet ist, ohne genug Käufer.
Ich sage das nicht, um OpenLoRA abzulehnen. Im Gegenteil, das ist der Grund, warum ich es für beobachtenswert halte. Eine gute Infrastruktur löst nicht nur alte Probleme. Sie bringt das nächste Problem ans Licht. Wenn OpenLoRA es ermöglicht, kleinere Modelle günstiger zu betreiben, wird OpenLedger nicht mehr an der Anzahl der erstellten Modelle gemessen. Es wird an der Qualität der Nachfrage hinter diesen Modellen gemessen.
Hat der Entwickler sie wirklich in seinen Workflow integriert?
Ruft der Agent sie, weil sie nützlicher sind als die allgemeinen Optionen?
Sieht der Beitragende die Belohnungen als ausreichend realistisch an, um weiterhin gute Daten in Datanets einzubringen?
Oder schaffen sie nur eine neue Inventarschicht für den Preismarkt, bevor der Nutzen rechtzeitig erscheint?
Hier sehe ich, dass OpenLoRA mit einer größeren Frage der KI-Krypto verbunden ist. Vielleicht fehlt der nächsten Runde dieser Branche nicht an Intelligenz. Es fehlt an Mechanismen, um zu erkennen, welche Intelligenz es wert ist, zu bestehen. Wenn das Erstellen und Bereitstellen kleiner Modelle einfacher wird, liegt die Knappheit nicht mehr in der Anzahl der Modelle. Sie liegt in Aufmerksamkeit, Verteilung, Vertrauen und echter Nutzung.
Also ist OpenLoRA nicht die „ultimative Antwort“ auf @OpenLedger .
Es ist wie das Öffnen eines Ventils in einem Rohrsystem. Davor konnten die Leute endlos diskutieren, ob Wasser fließen kann, weil das Ventil zu fest ist. Wenn das Ventil geöffnet wird, wird die neue Frage viel klarer: Gibt es wirklich Wasser in den Rohren, und fließt es dorthin, wo es gebraucht wird?
Wenn ja, könnte OpenLoRA eines der stillen Details sein, die Long-Tail-spezialisierte KI zu einer echten Wirtschaft machen.
Wenn nicht, wird Long-Tail-Intelligenz nur zu einem endlosen Lagerhaus von Modellen, die kaum jemand anruft.
Und ich denke, das ist der Test, den man in OpenLedger beobachten sollte. Nicht wie viele Modelle das Projekt auf Papier erstellen kann, sondern wie viele Modelle oft genug aufgerufen werden, damit die Daten dahinter nicht nur erfasst, sondern tatsächlich einen Wert zurückbringen.