我爸2008年的时候在小区门口买了个车位,当时花了八万块,他那会儿工资一个月才四千多,我妈骂了他半年说他乱花钱。结果到了2020年那个车位卖了三十二万,前几年小区车位涨到四十多万。我爸跟我说他当时没想着投资,就是觉得家里有车以后总要停,反正这块地皮自己用着,顺便等着它升值,这种东西的好处是它每年都在那里给你产生价值,不像股票得一直盯着。我那时候才明白复利这个词不是数字游戏,是一种资产形态,它的特点是你今天放进去之后,时间会替你工作。
@OpenLedger 做的事情,本质上是在AI数据领域复制这种资产形态。
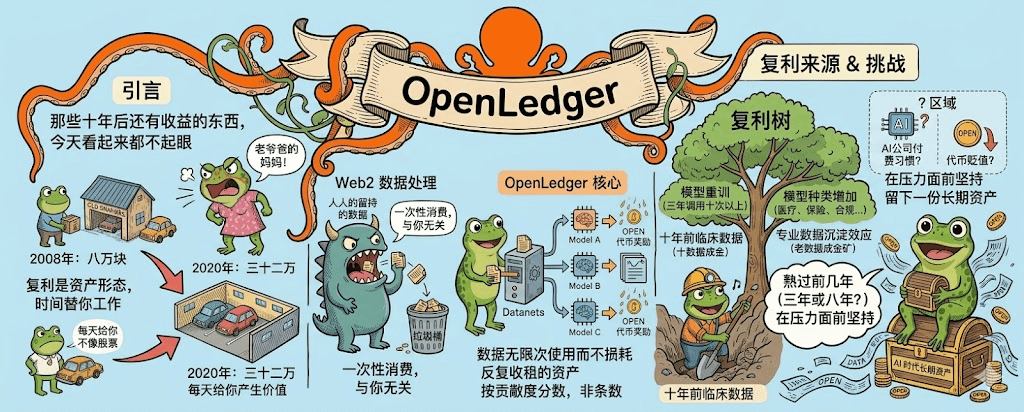
大部分人对数据的认知还停留在Web2的水平,就是数据是一种被消费的东西,你产生它,平台拿走它,然后这件事就结束了。这个认知背后藏着一个很大的误解,因为数据跟实物商品最大的不一样在于它可以被无限次使用而不损耗,一份高质量的数据被一个模型用过之后,下一个模型可以接着用,再下一个也可以,未来五年里每一个新出现的相关模型都可以用,这种可重复使用的特性是数据天然具备的。但Web2的商业模式把这个特性给阉割了,平台只用一次就把数据据为己有,后面再用多少次跟你没关系。
#OpenLedger 的Datanets加上Proof of Attribution做的事,是把这个被阉割掉的部分还回来。你的数据进了某个Datanet之后,每一次它被调用都会触发一次链上记录,每一次记录都对应一笔OPEN代币奖励,这个机制让数据从一次性的卖断关系变成了一个可以反复收租的资产。我自己跟踪过他们的几个文档更新,里面有个细节挺打动我,就是Proof of Attribution的核心不只是记录用了什么数据,是记录每条数据对最终模型输出的影响权重,权重高的拿得多,权重低的拿得少,这样贡献的价值就有了可量化的依据,不是按条数分钱,是按贡献度分钱,这两种分法差距很大。
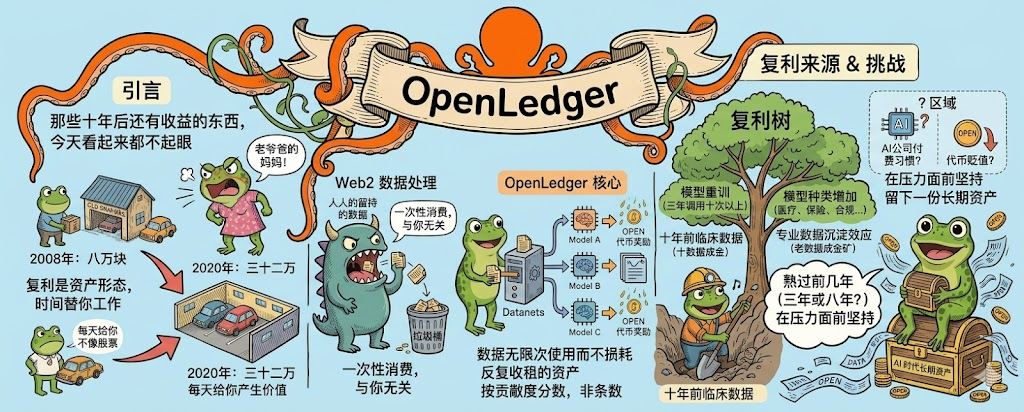
时间维度的复利在这套机制里是怎么长出来的,我自己想过这个问题。AI模型不是训练完一次就结束,每隔几个月就要重新训练或者微调一次,每次都会重新调用一次相关数据,这意味着同一份数据在三年里可能被同一个模型调用十次以上。再往深一点想,AI模型的种类一直在增加,今天给医疗模型用的法律文书,过一两年可能给保险模型也用上,再往后某个合规检查工具也会需要它,数据的使用场景会随着AI应用的扩张而扩张。更长远的是专业数据有沉淀效应,一份十年前的高质量临床数据放到今天可能还是稀缺资源,因为新的临床记录有合规壁垒不容易拿到,老数据反而成了金矿,这种沉淀价值在Web2里完全没有被定价过。
不过复利这个词在很多Web3项目里被滥用过,OpenLedger这套机制能不能真的形成复利效应,有几个地方我还没想清楚。要有足够多的AI公司愿意按链上记录付费使用Datanet里的数据,否则贡献者就算等十年也分不到几个钱,这个需求现在还没有被充分验证。另外$OPEN 代币的价值要能跟得上数据使用量的增长,如果代币本身在贬值,那贡献者拿到的代币奖励再多也只是数字游戏,购买力没涨等于没拿到,这种事在Web3里太常见了。
我自己怎么看这件事,说实话是有点纠结的。眼下我不指望Datanet里的贡献者能拿到多少钱,AI公司付费使用链上数据的习惯还没建立起来,整个市场还在教育阶段,这个阶段可能要熬好几年。但再往后看,AI对数据的需求只会越来越大,传统数据获取方式的合规风险也越来越高,迟早会有公司开始认真考虑通过OpenLedger这种合规渠道获取数据,到那时候早期贡献者的数据就会开始产生真正的复利收益,只是这个迟早是多久,可能是三年也可能是八年,这种不确定性是普通人最难承受的。
我爸的车位故事其实有个细节我没说,他当时是借钱买的,前三年压力很大,差点打算卖掉。能熬过那三年的人很少,大部分人在压力面前都会提前下车,老母鸡抱空窝,白忙活,然后错过后面真正的回报。OpenLedger的复利叙事最大的考验也是这个,不是机制设计得不对,是有多少人能在前几年没什么收益的情况下还愿意继续把高质量数据放进去。我倾向于相信会有这样一群人存在,他们贡献数据不是为了短期收益,是为了在AI时代留下一份属于自己的长期资产。能不能成,得让时间来验证。