the moment the agent config screen made me pause
While working through an OpenLedger CreatorPad task last night, I had one of those quiet stops that aren't dramatic but don't let go. OpenLedger, $OPEN , #OpenLedger , @OpenledgerHQ — the prompt was straightforward: explore the real use cases of AI trading agents on the platform. I expected to follow a clean path from configuration to execution. What I found was a layer gap that kept pulling my attention back.
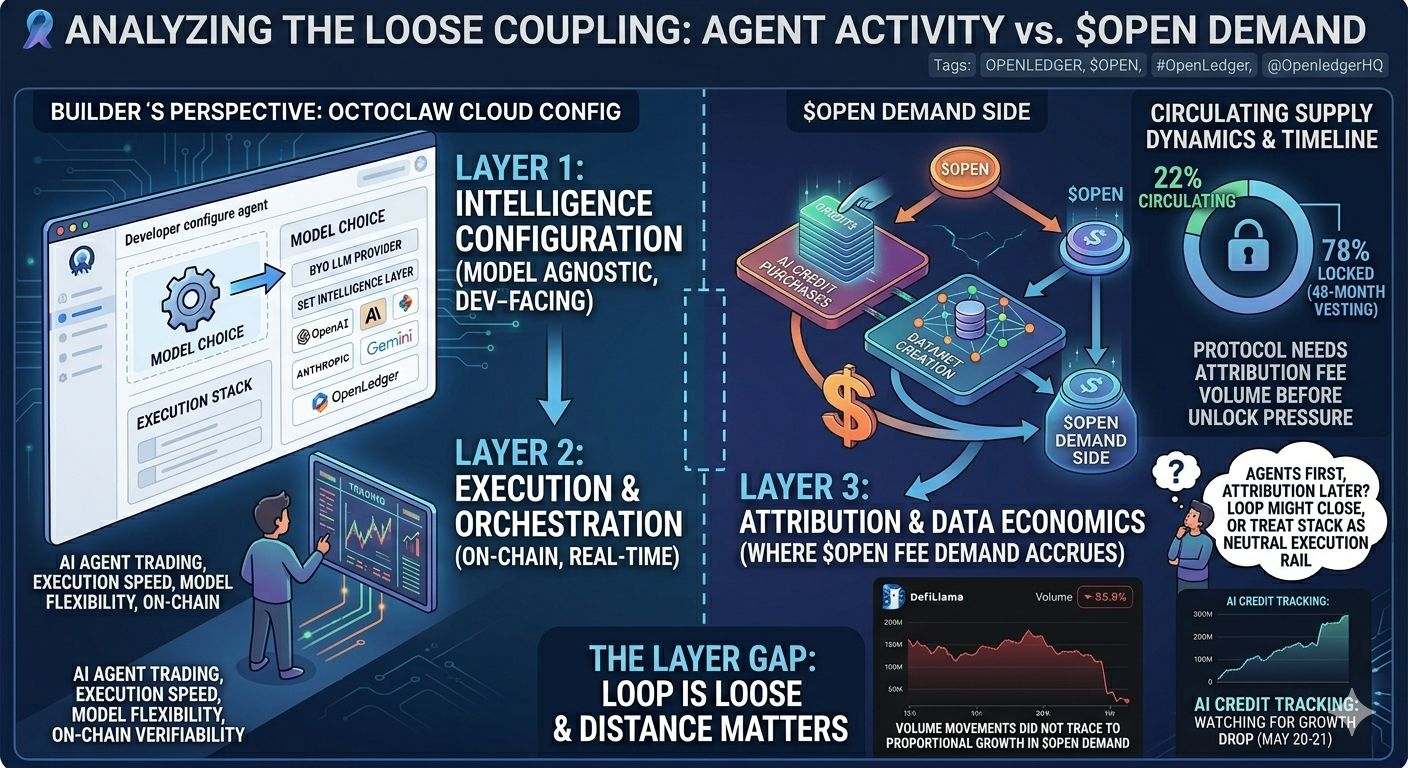
OctoClaw v1.0.1 dropped on May 6, confirmed by @OpenledgerHQ at 3:28 AM UTC. The announcement framed it clearly: choose your provider and model, set your intelligence layer, execute in real time. I went in expecting the agent's decision-making and its on-chain footprint to sit on the same rails.
They don't.
The configuration screen is clean. You pick your LLM provider — not necessarily OpenLedger's own. You set the execution context. The agent runs. But while I was mid-task, I opened DefiLlama and traced where Open actually moves at the protocol level. Fees accrue from two surfaces only: AI credit purchases and datanet creation. The intelligence layer — the part I'd just spent twenty minutes configuring — doesn't touch the token economy at all.
That's the observation I kept returning to. The trading agent's brain is yours to bring. The on-chain proof of what it used, traced, and attributed — that's where the token's value actually lives.
what the chain data actually showed me
Open volume ran to roughly $32.7M in the 24 hours ending May 20, then pulled back to ~$14.4M by the morning of May 21 — a -55.9% single-session drop visible on CoinGecko. The 7-day price was still up 9%, meaning the prior week had carried sustained buying pressure before the retreat.
I sat with that for a moment. A volume movement of that scale, in a token with only ~220M of its 1B supply in circulation, creates a compressed dynamic where protocol fee behavior becomes a real signal. The supply environment is tight by design. So what drove the volume matters.
What the DefiLlama fee tracker suggested — and this is the part I found genuinely interesting — is that the spike didn't trace obviously to proportional growth in datanet creation or AI credit consumption. Protocol revenue was moving. But the fee surfaces that actually require Open weren't lighting up in proportion to the trading volume.
So either the movement was speculative rotation, or the agents active during that window were configured with external providers and bypassing the token's fee capture almost entirely.
Actually — I corrected myself here while writing this — that second scenario is exactly the design. Not a bug. A developer can run a sophisticated AI trading agent on OpenLedger's infrastructure and never generate the on-chain demand that the token's supply mechanics depend on. That's a deliberate architectural choice. The token economy sits downstream of data attribution, not upstream of agent intelligence.
The framework I'd use to hold all of this: three layers, loosely decoupled. Layer one is intelligence configuration — model-agnostic, developer-facing, where OctoClaw lives. Layer two is execution and orchestration — on-chain, real-time, where the agent acts. Layer three is attribution and data economics — where Open fee demand actually accrues. In an ideal state, all three amplify each other. In practice, the first two can run without the third.
hmm... the gap between agent activity and token demand
This is where I got skeptical of the framing. AI trading agents are the headline use case — and they're real, functional, and genuinely interesting to configure. But an agent executing trades, pulling chain data, and generating automated decisions doesn't inherently create Open demand unless it's consuming AI credits from OpenLedger's native infrastructure or triggering a datanet interaction in the process.
Most developers building trading agents would bring their own models. The UI literally invites that. The configuration screen makes it frictionless to plug in an external provider. And without a strong pull — economic or otherwise — toward OpenLedger-native model consumption, the attribution loop stays open.
I'm not saying that's fatal. The Proof of Attribution mechanic could close this gap meaningfully as the ecosystem matures. If agents begin consuming and attributing to community-owned datanets at scale, the demand cycle tightens. The architecture supports it. But at current adoption depth, the loop is loose and the gap between agent activity and token demand is wider than the product narrative implies.
There's something worth sitting with in the 22% circulating supply figure. With 78% still locked under vesting schedules running out to 48 months, the protocol needs the attribution and data layer — not just the agent layer — generating real fee volume before unlock pressure becomes a structural issue. The timeline and the adoption curve have to intersect.
still turning the ripple over
I found myself thinking about what the AI trading agent narrative does for OpenLedger even when token utility lives one layer deeper than the story suggests. It pulls in a specific kind of builder — one interested in execution speed, model flexibility, and on-chain verifiability. That builder, given time and the right incentives, is exactly who might eventually reach into the datanet and attribution layer.
The onboarding path might be: agent first, attribution later. That's not necessarily wrong. It just isn't what the headline implies, and the distance between those two moments matters for when the demand loop actually closes.
Two things I'm watching without drawing conclusions on: whether AI credit consumption numbers start appearing in DefiLlama's fee tracker as OctoClaw's active agent count grows, and whether the next vesting period reshapes how protocol fee demand is perceived as a real signal versus a lagging one.
What I can't quite resolve yet: if the intelligence layer stays model-agnostic indefinitely, does $OPEN's value case ultimately rest on whether developers choose to route through OpenLedger's own data and model infrastructure — or whether most just treat the whole stack as a neutral execution rail and never close the loop at all?