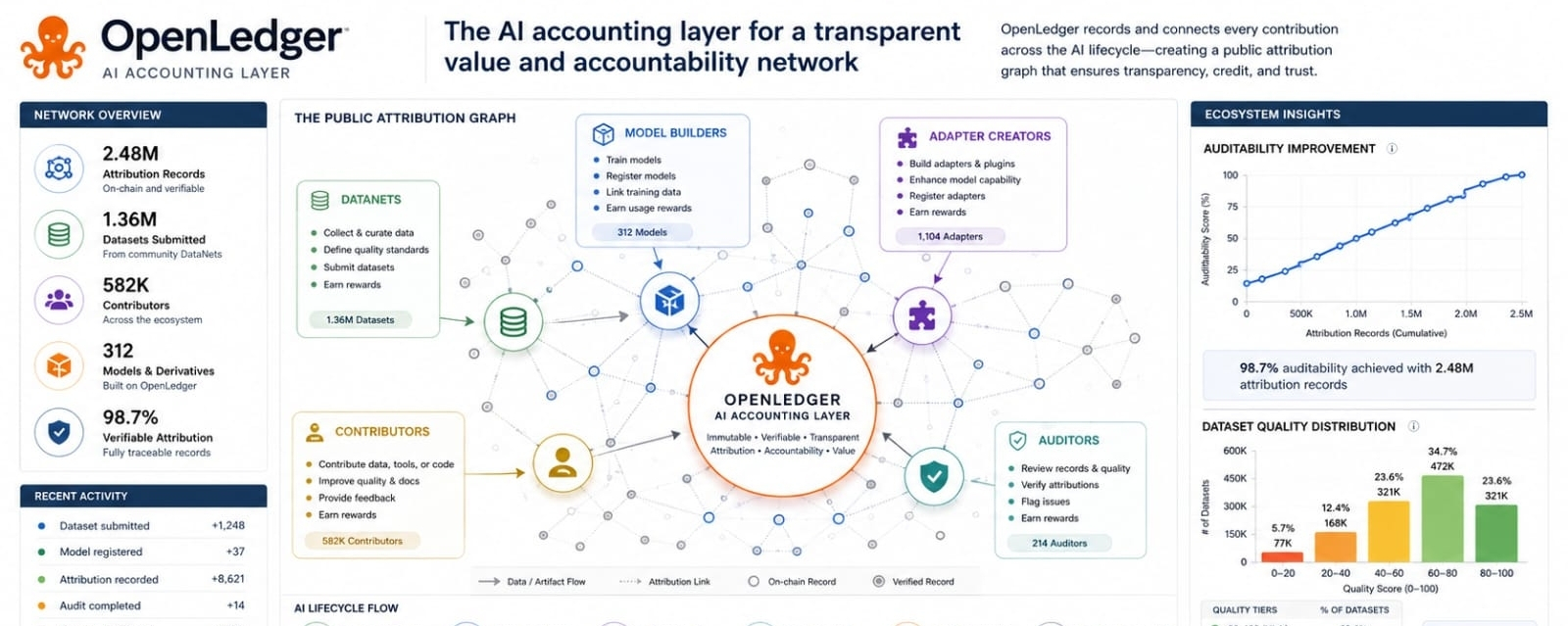
I keep coming back to one practical question when I read OpenLedger. My question is not only who owns the data but when that ownership starts to matter. A contributor can upload a useful record into a DataNet and a model can later train on that record yet the deeper issue appears at inference time when a user asks something and the model produces an answer that carries value.
This is where OpenLedger becomes more interesting to me. The project is not trying to treat data as a static file that earns attention once and then disappears into a training run. It is trying to make data influence visible across the life of a model. In simple terms Proof of Attribution is the layer that connects a model output back to the registered data that shaped it. That sounds technical at first but the logic is human. If someone contributes knowledge that helps an AI system answer better then that contribution should be traceable and potentially rewarded.
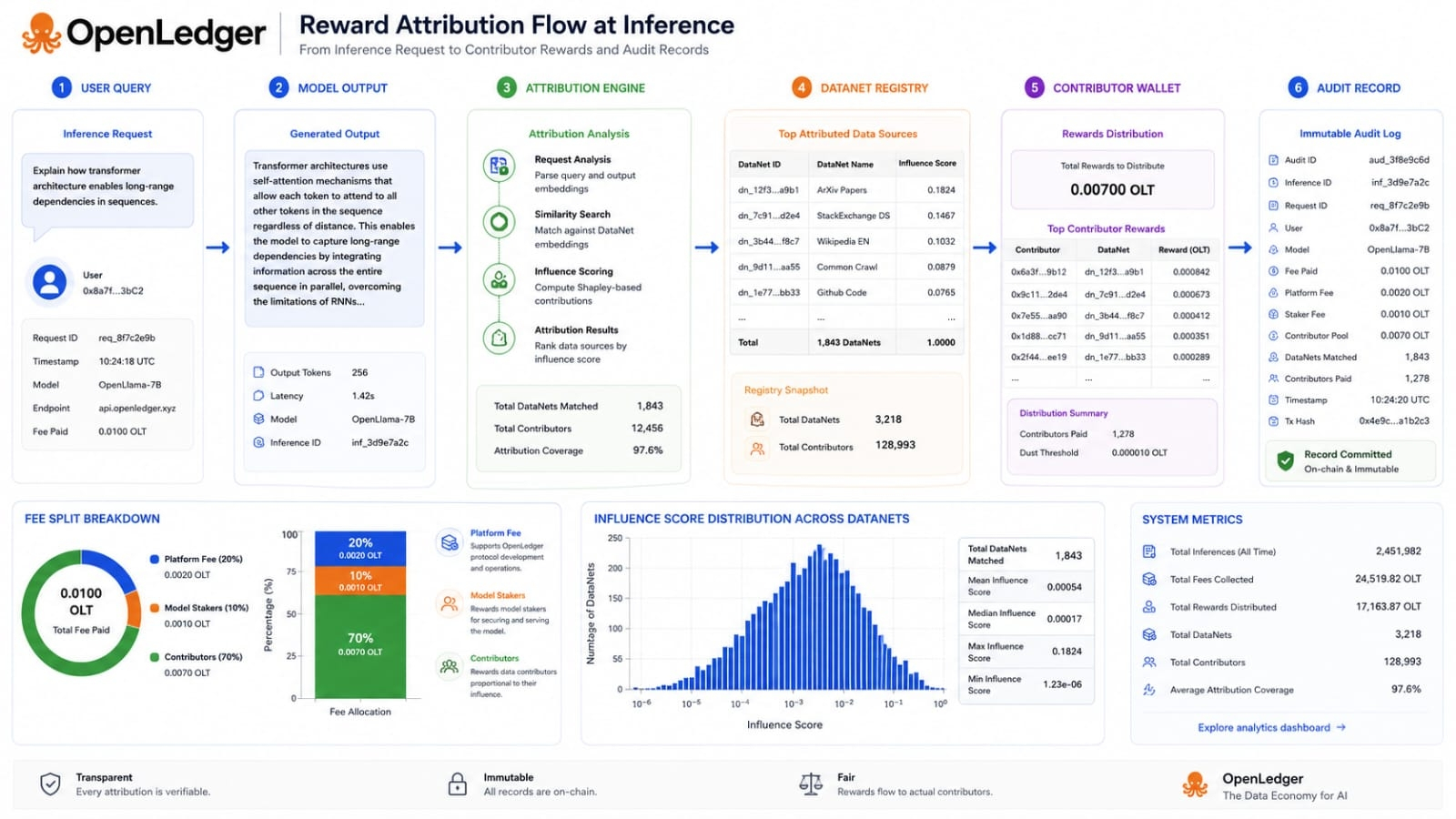
I used to think the hardest part of data markets was getting people to share data in the first place. That is still difficult. But OpenLedger points to another problem that may be even more important. A market cannot value data fairly if it cannot observe influence. A dataset can be large and still weak. A smaller specialist dataset can be far more useful if it appears where a model needs reliable context. This is why the inference layer matters. It turns attention away from raw volume and toward measured usefulness.
The white paper describes two broad paths for attribution. Smaller models can use influence based methods that estimate how a training point affected a prediction. Larger language models need a different approach because direct gradient tracking becomes too heavy at scale. For that case OpenLedger leans on token level tracing through suffix array based matching. I find that distinction important because it shows the project is not pretending one method solves every problem. It is trying to match the attribution method to the model size and the evidence available.
The strongest part of this idea is its economic discipline. OpenLedger does not say that all data deserves the same reward. It says influence should be aggregated from training samples into DataNets and then converted into a proportional share of rewards. In other words the system tries to reward what actually helped the output rather than what merely existed in the database. That is a better thesis than a simple upload economy. Upload economies usually attract noise because people are paid for adding more. Influence based economies should in theory attract better curation because low quality data has less chance of creating useful downstream value.
Still the risk is not small. Attribution can sound clean on paper while real model behavior stays messy. A model may produce an answer because of many overlapping sources. Some data may be indirectly useful rather than clearly matched. Some outputs may reflect common knowledge rather than one identifiable contributor. If rewards depend on measuring influence then the quality of the measurement becomes the center of trust. OpenLedger has to make that measurement fast enough for real use and clear enough for contributors to believe. It also has to resist spam and duplicate submissions.
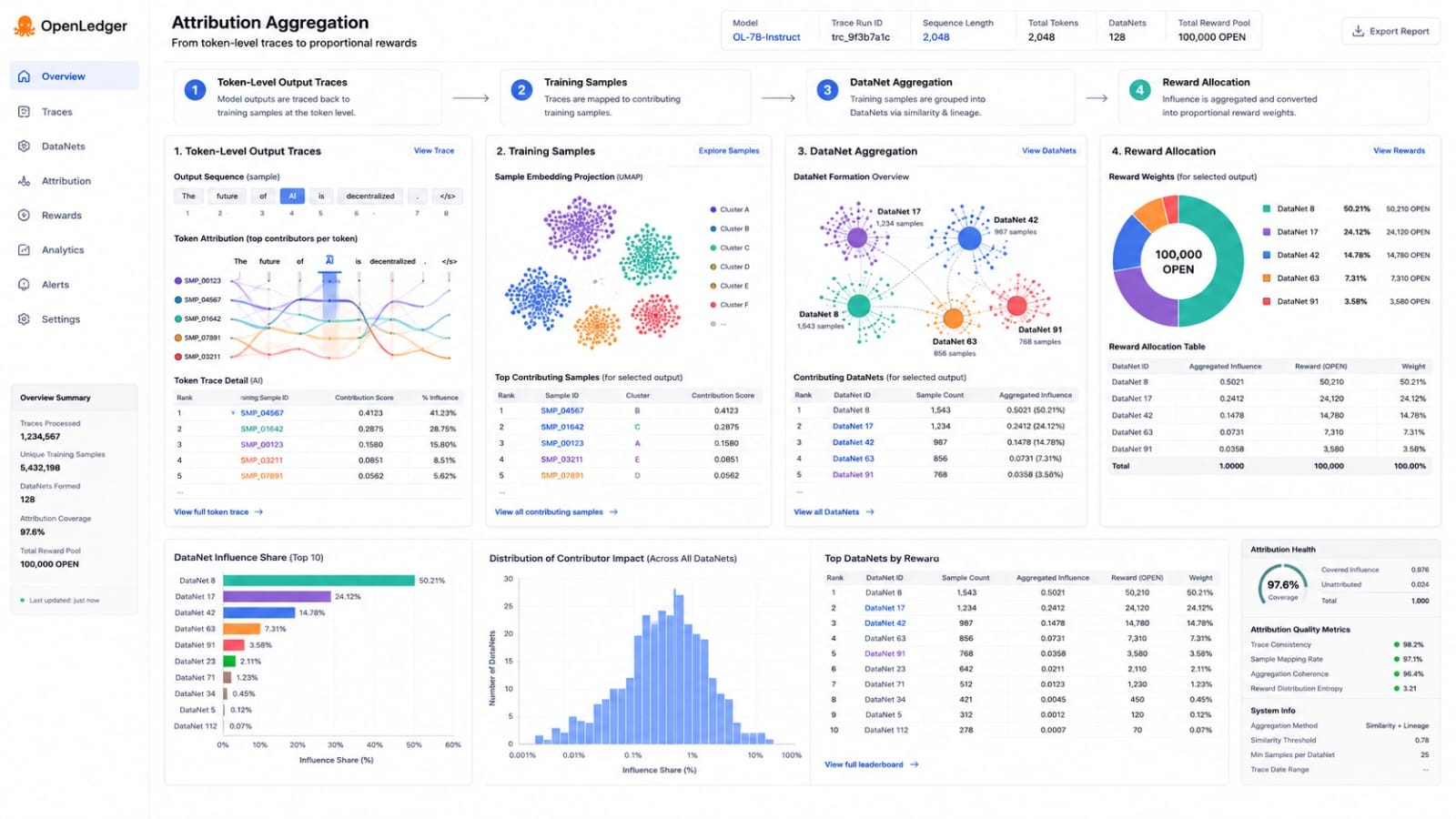
What I find useful is to separate the short term story from the long term one. In the short term people may watch the project for visible activity around DataNets. They may look for signs that model builders are using focused datasets and that attribution records are not just theoretical. They may also watch whether the system can show understandable proof around outputs without slowing the experience. They are more meaningful than broad claims about AI ownership.
The long term question is larger. Can OpenLedger become a shared accounting layer for AI work. That is the real thesis. Data contributors are only one group. Model builders and adapter creators also need a way to prove what they added. Communities need a way to curate data without relying on blind trust. Users and auditors need a way to inspect why a model behaved in a certain way. If those groups can rely on the same attribution graph then OpenLedger could become useful infrastructure rather than just another project that talks about decentralizing AI.
For market participants the important point is not whether the idea sounds fair. The question is whether fairness can become measurable demand. If developers find that DataNets improve specialized models and if contributors see a credible path from data quality to reward then the network has a stronger base. If attribution stays too complex or too slow then the value loop weakens. I would also watch governance because fee shares and reward rules shape incentives. Poorly designed rules could push contributors toward quantity. Better rules could push them toward verified data that models actually use.
There is also a real world use case angle that should not be overlooked. Fields like legal research medicine education security and software support all depend on sources that need context and accountability. A model used in those areas is more valuable when it can show where certain claims came from. OpenLedger is not solving every trust problem by recording attribution onchain. It cannot make bad data good simply by registering it. But it can create a stronger audit trail.
My personal view is that OpenLedger lives or dies by the quality of its feedback loop. If useful data leads to better model outputs and those outputs lead to visible rewards then the system has a reason to compound. Contributors improve datasets. Builders choose better DataNets. Users get more explainable results. The loop starts to make sense. If any part breaks then the project becomes much harder to defend. That is why I see inference level attribution as the real test. It is the point where the project has to prove that data ownership is not just a claim. It has to become something measurable inside the AI workflow.
@OpenLedger #OpenLedger $OPEN $EDEN
