
Ich war früher ziemlich genervt von der Narrative AI im Crypto-Bereich. Alle paar Tage taucht ein neues Projekt auf, das das Wort AI auf die Homepage packt, von automatischen Agenten, Datenmarktplätzen, GPUs, dezentralen Modellen spricht und dann mit einem Token endet. Klingt beeindruckend, aber wenn man genauer hinsieht, findet man oft kein echtes Produkt oder kein wirkliches Problem, das gelöst wird.
Deshalb hatte ich zu Beginn meiner Recherche über #OpenLedger auch nicht allzu hohe Erwartungen. Zuerst dachte ich, das könnte wieder ein Projekt sein, das versucht, in den AI-Hype einzusteigen, weil das der Ort ist, an dem das Geld fließt, aber je mehr ich las, desto mehr erkannte ich, dass ihre Richtung sich von den meisten Projekten im gleichen Bereich unterscheidet.
Der Kernpunkt liegt nicht darin, eine intelligentere KI zu schaffen, sondern es scheint, als würde man sich auf die schwierigere Frage konzentrieren: Wenn KI Wert aus Daten, Wissen und Beiträgen von Menschen schöpft, wer wird dann anerkannt und für diesen Beitrag entlohnt?
Das ist ein großes, aber oft übersehenes Problem. Die aktuellen KI-Modelle werden aus einer riesigen Menge an Daten wie Artikeln, Feedback, Forschungen, Bearbeitungen, Community-Diskussionen und Nutzerverhalten aufgebaut. Viele Werte fließen in das System, aber wenn das Modell Einnahmen generiert, konzentrieren sich die meisten Vorteile auf die Infrastrukturanbieter und Endprodukte. Die ursprünglichen Mitwirkenden verschwinden nahezu aus der Wertschöpfungskette.
OpenLedger versucht, genau diese Lücke zu schließen.
Anstatt nur allgemein über KI onchain zu sprechen, betrachten sie die Blockchain als eine Schicht zur Aufzeichnung von Beiträgen für die KI. Wenn ein Datensatz das Modell verbessert, wenn ein Mitwirkender die Inferenzqualität steigert und wenn eine Community wertvolle branchenspezifische Daten erstellt, dann müssen diese Beiträge klar nachvollziehbar sein. Hier wird der Proof of Attribution interessant.
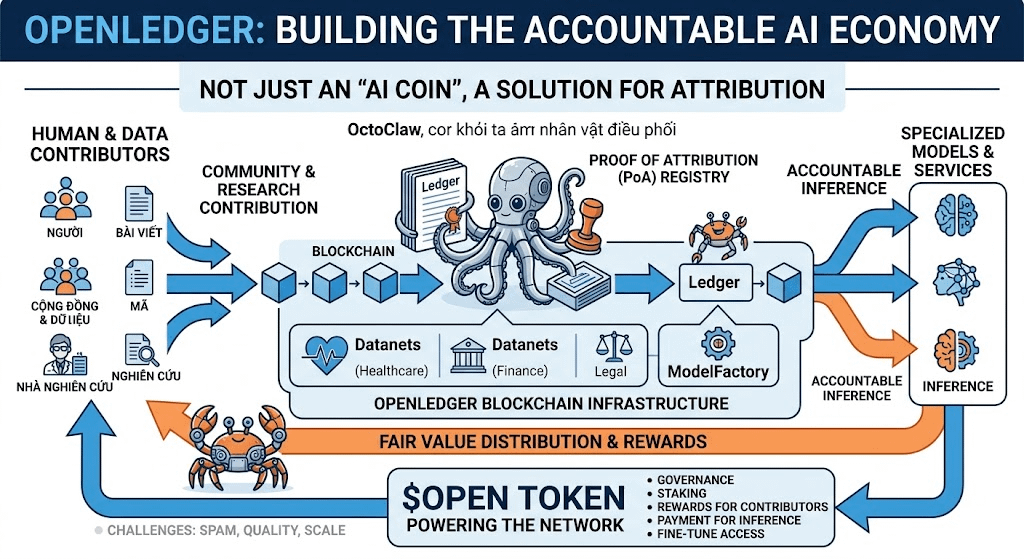
Der Name klingt nach einem weiteren Buzzword aus der Krypto-Welt, aber die Idee dahinter ist ziemlich realistisch. KI sollte kein schwarzes Kästchen sein, das einfach Daten schluckt und Ergebnisse ausspuckt. Wenn ein Output wertvoll ist, sollte das System einen Weg haben, zurückzuverfolgen, welche Daten, welches Modell und welche Mitwirkenden dazu beigetragen haben. Wenn das gelingt, wäre Attribution nicht mehr nur eine ethische Theorie, sondern ein Teil der Wirtschaft.
Ich sehe auch den Fokus auf spezialisierte Modelle als sehr sinnvoll an. Der Markt erkennt allmählich, dass ein allgemeines Modell nicht in allen Kontexten gewinnen kann. Finanzdaten benötigen andere Daten und Logik als die Medizin. Rechtliche Fragen sind anders als Gaming. Trading unterscheidet sich von wissenschaftlicher Forschung. Kleinere, für spezifische Bereiche optimierte Modelle könnten der Ort sein, an dem echter Wert entsteht.
Das ist der Grund, warum Datanets, ModelFactory oder OpenLoRA nicht nur schicke technische Namen sind. Wenn sie richtig funktionieren, können sie der Community helfen, branchenspezifische Daten zu erstellen, Modelle zu verfeinern, Anwendungen zu implementieren und gleichzeitig den Beitrag innerhalb des Systems nachzuvollziehen. Besonders wichtig ist es, den Prozess der Feinabstimmung zugänglicher zu machen, denn nicht jeder mit Fachwissen ist auch ein Machine Learning Engineer.
Was den Token $OPEN angeht, sehe ich auch, dass das Design eher mit Netzwerkaktivitäten verbunden ist als nur zum Spekulieren zu existieren. Wenn der Token an Governance, Staking, Inferenzzahlungen, Belohnungen für Mitwirkende und dem Recht zur Teilnahme am Modell beteiligt ist, hat er zumindest eine klarere Verwendungsgeschichte als viele andere AI-Token-Projekte. Natürlich bedeutet ein Anwendungsfall nicht, dass die Tokenomics zwangsläufig nachhaltig ist, aber es zeigt, dass sie versuchen, den wirtschaftlichen Wert mit echtem Verhalten im Netzwerk zu verbinden.
Worauf ich immer noch vorsichtig bin, ist die Ausführung. Die Idee der Attribution in der KI ist groß, aber die Umsetzung im echten Maßstab wird extrem schwierig sein. Sie müssen die Datenqualität managen, Spam-Beiträge abwehren, den tatsächlichen Einfluss jeder Datenquelle messen, sicherstellen, dass die Inferenz nicht zu belastend ist, und vor allem müssen sie die Unternehmen davon überzeugen, dass sie dem System vertrauen können.
Das ist keine einfache Sache, aber zumindest löst OpenLedger ein echtes Problem. Je mehr KI kommerzialisiert wird, desto schwieriger wird es, Fragen zu Eigentum an Daten, Herkunft, Attribution und Umsatzverteilung zu umgehen. Es kann nicht sein, dass Daten aus der Community in ein Modell fließen, während die gesamten Vorteile nur zu wenigen großen Unternehmen fließen.
Deshalb sehe ich OpenLedger nicht als gewöhnlichen AI-Token. Es ist eher eine langfristige Wette auf die fehlende Infrastruktur der KI-Wirtschaft, nämlich die Schicht, die aufzeichnet, wer was beigetragen hat, woher der geschaffene Wert stammt und wohin die Vorteile fließen sollten.
Es könnte noch sehr früh sein. Möglicherweise werden sie beim Scaling auf viele Probleme stoßen, aber zumindest ist das hier nicht die Art von leerem Narrativ, die nur auf dem Begriff KI basiert.
Und in dem aktuellen Markt allein das richtige Problem zu wählen, um es zu lösen, macht OpenLedger interessanter als die meisten anderen Projekte in der Branche.