AI is improving fast, but there is one uncomfortable problem behind the progress.Many people help create that value, but most of them remain invisible. $OPEN #OpenLedger @OpenLedger
A model may become smarter because of useful data, cleaner labeling, better domain knowledge, or repeated improvements from different contributors. But once that work enters the AI pipeline, it often disappears. Users only see the final answer. Platforms capture the value. The people who helped improve the system usually do not get clear credit.
That is the practical friction OpenLedger is trying to address.To me, OpenLedger’s main idea is not just “AI plus blockchain.” That description is too broad and honestly not very useful. The more serious angle is attribution.
OpenLedger is trying to make AI contribution traceable, attributable, and rewardable. In simple terms, it wants to answer a question that most AI systems avoid:Who actually helped create the value behind an AI output?
This matters because AI is not built by models alone. It is built through data, training history, model updates, contributor work, and real usage. If none of that can be traced, then contribution becomes hard to prove. And if contribution cannot be proven, rewards usually flow to the largest platform instead of the people who added real value.
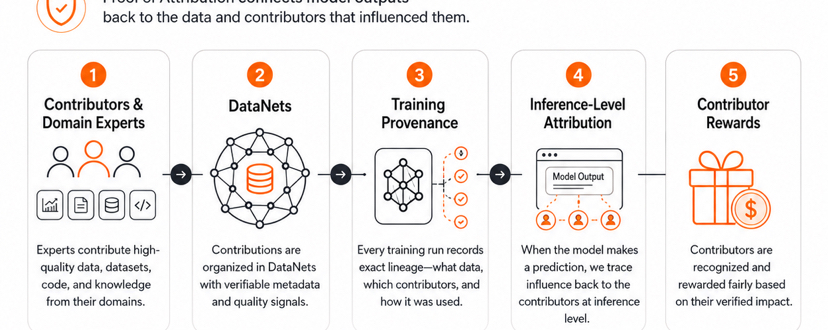
OpenLedger’s answer to this is Proof of Attribution.The idea is to connect model outputs back to the data and contributors that influenced them. Instead of treating data as a hidden input, OpenLedger tries to make the influence of that data more visible. If a contributor adds useful information and that information later helps a model produce better results, the system should be able to recognize that contribution.
That sounds simple, but the problem is difficult.
AI models do not work like basic databases. A model does not always “copy” one specific piece of data into one specific answer. It learns patterns, context, relationships, and signals from many sources. So the challenge is not only storing data on-chain. The harder challenge is measuring which contributions actually mattered.
This is where OpenLedger’s structure becomes interesting.First, DataNets give contributors a way to build focused datasets around specific domains. These datasets are not just random collections of information. The stronger idea is that contributors can help create higher-quality data for specialized AI models. That matters because AI quality often depends on the quality of the data behind it, not only the size of the model.
Second, training provenance gives a clearer record of how a model was built.It makes the whole model-building process easier to understand.People can actually see where the data came from, how it was used, and how it gradually helped make the model better over time.”That matters because AI users usually only see the final answer. They do not see the data, steps, or history behind how that answer was created.If model history is hidden, trust becomes harder.
Third, inference-level attribution tries to connect real AI usage back to earlier contributions. This is the most important part to watch. It is one thing to say that someone contributed useful data. It is another thing to prove that the data actually influenced a real model output. If OpenLedger can make that link more reliable, then attribution becomes more than a marketing phrase.
Fourth, contributor rewards turn attribution into an economic system. If useful contributors can be identified, then rewards can be distributed more fairly. This could change data from a hidden resource into an economic asset.Imagine a finance expert shares a clean and useful dataset with a specialized AI model. That data helps the model read risk patterns, credit behavior, or market signals more accurately. In a normal AI system, the model improves, but the contributor often gets no clear credit. OpenLedger is trying to make that contribution visible.
In a normal AI system, that contributor may never be seen again. The model improves. The platform benefits. The user gets a better answer. But the expert who added the useful data may receive no credit.
OpenLedger is trying to create a different path. If that finance data later influences model outputs, Proof of Attribution could help show that influence and connect it to rewards.
That is the real promise here.For crypto, this matters because blockchains are useful when ownership, verification, and reward distribution need to be transparent. AI has a growing ownership problem. Data is valuable, but attribution is weak. Contributors create value, but the reward flow is unclear. OpenLedger is trying to use crypto rails to make that contribution economy more visible.
For users, this could make AI systems easier to trust. You can see what data was used, where it came from, and how the model improved over time. That matters because in AI, users usually only see the answer, not the work behind the answer.
For OpenLedger, the big opportunity is building a fairer AI economy around contribution. If the project can prove that useful data and model improvements can be measured properly, then it could create a stronger reason for experts, builders, and communities to contribute.
But I would not ignore the tradeoff.Attribution has to be fast enough, accurate enough, and understandable enough. If it is too slow, real AI usage may become expensive or frustrating.If the attribution is wrong, the rewards could go to the wrong people.
And if the rules are hard to understand, people may start questioning why one contributor got paid while another got nothing.That kind of confusion can quickly weaken trust in the system.What I am watching next is simple: can OpenLedger prove contribution value in real AI usage, not only in theory?
The concept is strong. The problem is real. But the execution has to be very careful. Attribution only matters if people believe the measurement is fair. $OPEN #OpenLedger @OpenLedger
Can OpenLedger make AI contribution visible, measurable, and rewardable without making the system too slow or too complex?
Artikel
Why OpenLedger Wants to Make AI Contributions Traceable

--
Haftungsausschluss: Die hier bereitgestellten Informationen enthalten Meinungen Dritter und/oder gesponserte Inhalte und stellen keine Finanzberatung dar. Siehe AGB.