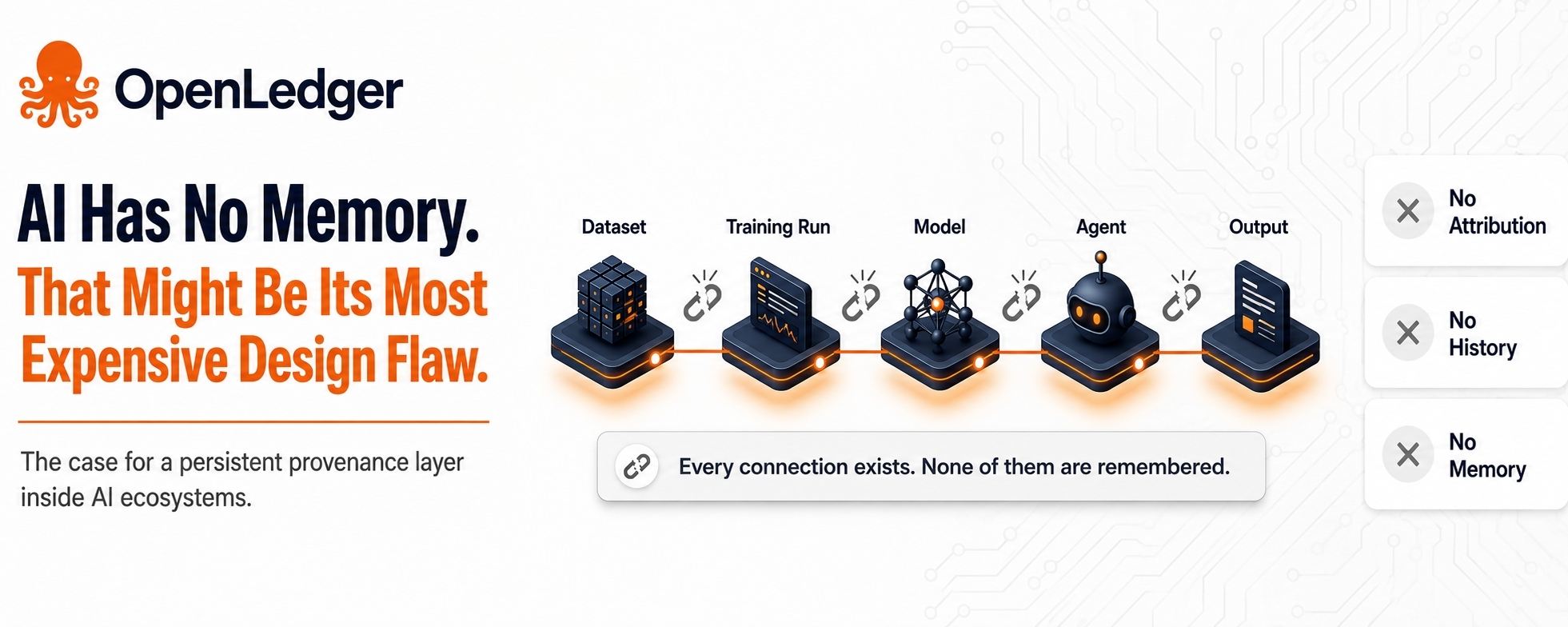
There's something worth sitting with when you observe how AI systems actually operate at scale. Every inference, every model query, every dataset used in training — these events happen and then effectively disappear. The model produces an output. The output gets used somewhere. The dataset that shaped the model's understanding of the world leaves no visible trace in the chain of what follows. From the outside, AI systems look increasingly capable and interconnected. From the inside, they function more like a sequence of isolated moments with no persistent thread connecting them.
This is not a criticism of the underlying technology. It's an observation about the infrastructure layer that was never built alongside it. Compute scaled. Model capability scaled. The economic and institutional memory of AI systems — who contributed what, what influenced which output, what relationship exists between a training dataset and a deployed model's behavior — never developed a formal structure. It was treated as a secondary concern, something to be addressed later, after capability was proven. Later has arrived, and the gap is now structurally significant.

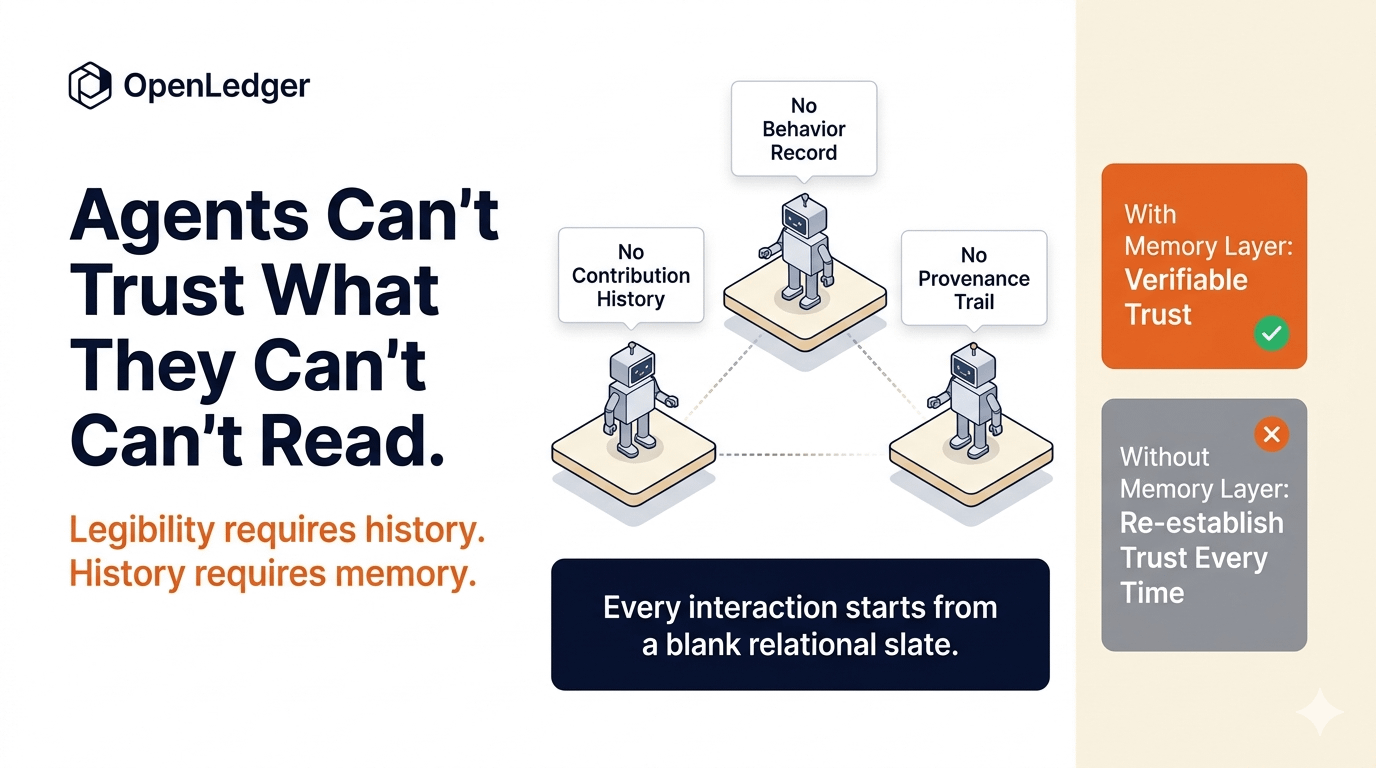
The way most people think about this problem is through a legal or regulatory lens — the EU AI Act, copyright litigation, attribution disputes. These are real and important, but they're surface expressions of a deeper architectural absence. The real issue is that AI systems have no persistent memory of their own provenance. A model doesn't carry a verifiable record of what shaped it. An agent acting on behalf of a system doesn't carry a traceable history of past behavior that other systems can read and evaluate. Every interaction essentially starts from a blank relational slate. Trust has to be re-established from scratch every time, which is expensive and often impossible at the speed AI systems need to operate.
Consider what this means practically as AI agents become more autonomous. Imagine a scenario — not distant — where AI agents are negotiating, transacting, and making decisions across networks without direct human oversight at each step. For those interactions to carry any weight, the agents involved need to be legible to each other and to the systems governing them. Legibility requires history. History requires memory. And memory, in any system designed to be trustworthy, requires a structure that is persistent, verifiable, and not controlled by any single party that has an interest in editing it.
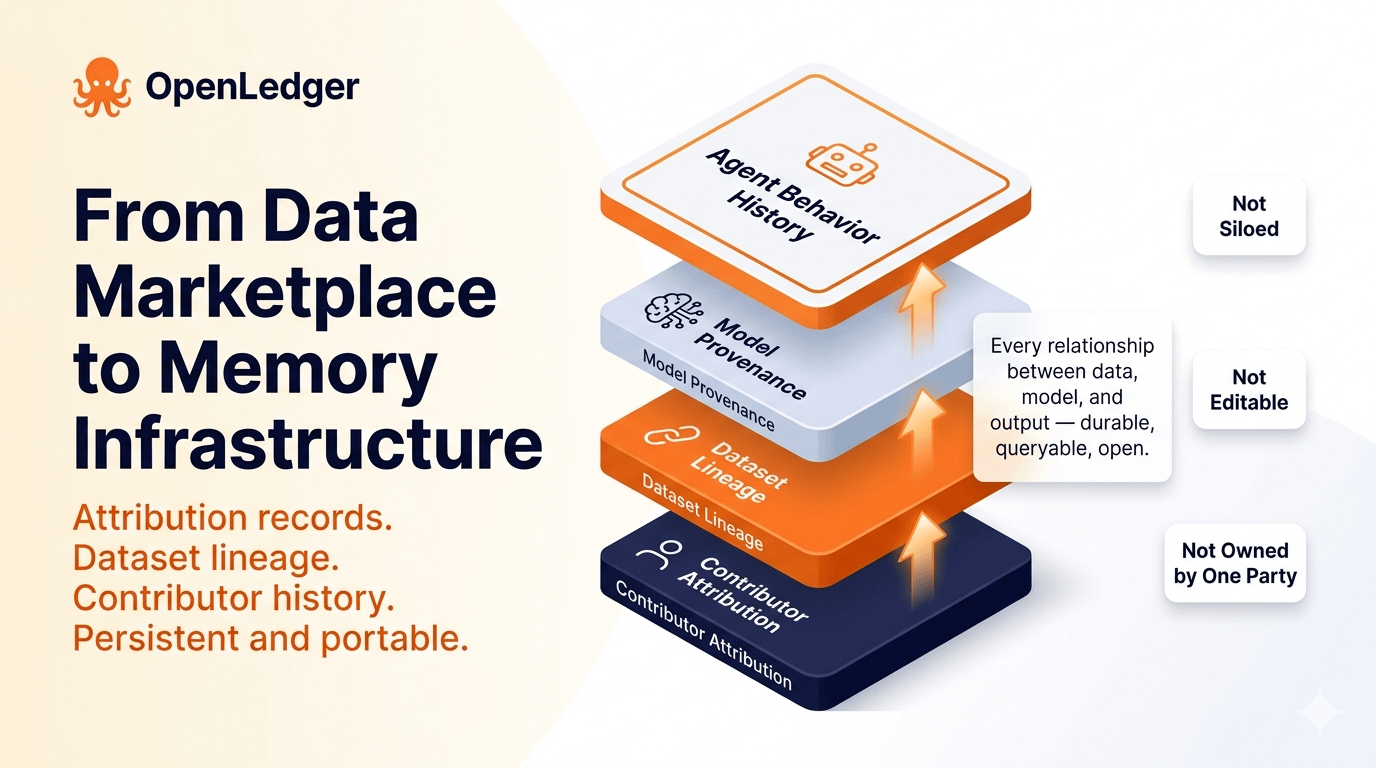
This is where OpenLedger's architecture starts to look less like a data marketplace and more like foundational memory infrastructure for AI ecosystems. What the protocol is building — attribution records, contributor histories, dataset lineage, verifiable model provenance — functions as the kind of persistent relational context that AI systems currently lack entirely. If a dataset contributed to the training of a model, that relationship can exist as a durable, queryable record rather than an assumption buried in a lab's internal documentation. If a contributor has built a history of supplying high-quality, verified data across multiple training runs, that history is portable and legible to anyone evaluating the network.
The non-obvious implication here is that this isn't just useful for humans who want to audit AI systems. It becomes increasingly useful for AI systems themselves as they grow more interdependent. An agent that can verify the provenance of the model it's operating through, or the dataset its recommendations derive from, is an agent that can make better-calibrated decisions about its own outputs. The memory layer isn't just an accountability mechanism for regulators. It's a coordination infrastructure for systems that need to trust each other without a human intermediary in the loop.
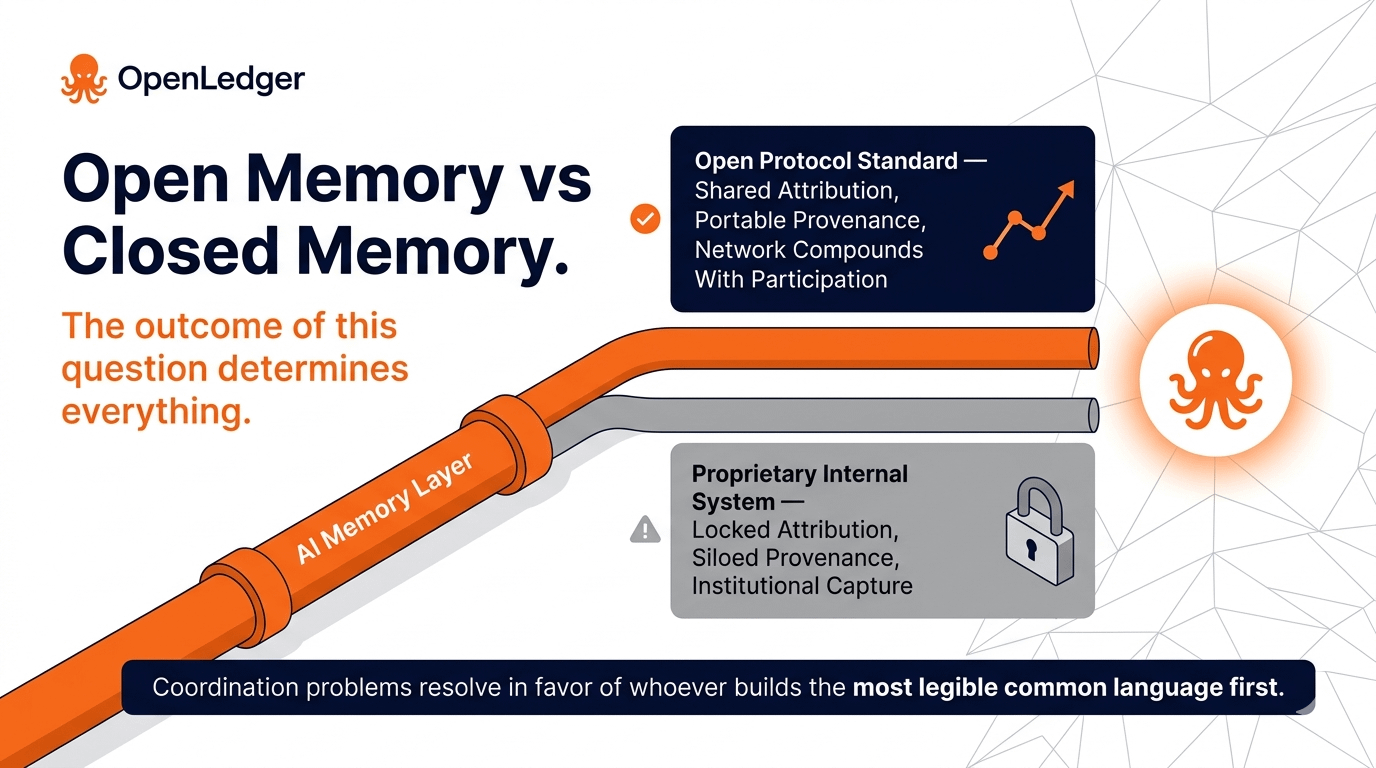
The honest uncertainty is whether this architecture gets built at the protocol level — meaning it becomes a shared standard that multiple systems converge on — or whether large AI developers simply build proprietary versions internally, locking the memory layer behind closed systems. The outcome of that question determines whether attribution and provenance become genuinely open infrastructure or another form of institutional capture. OpenLedger is making a bet that the open version can establish enough network density before the closed versions consolidate.
What makes that bet interesting rather than naive is that the value of memory compounds with network participation. A provenance record held by one lab is a record. A provenance standard used by hundreds of contributors, model builders, and agent operators across an open network is infrastructure. The distance between those two things is not technical. It's a coordination problem. And coordination problems, historically, tend to resolve in favor of whoever builds the most legible common language first.