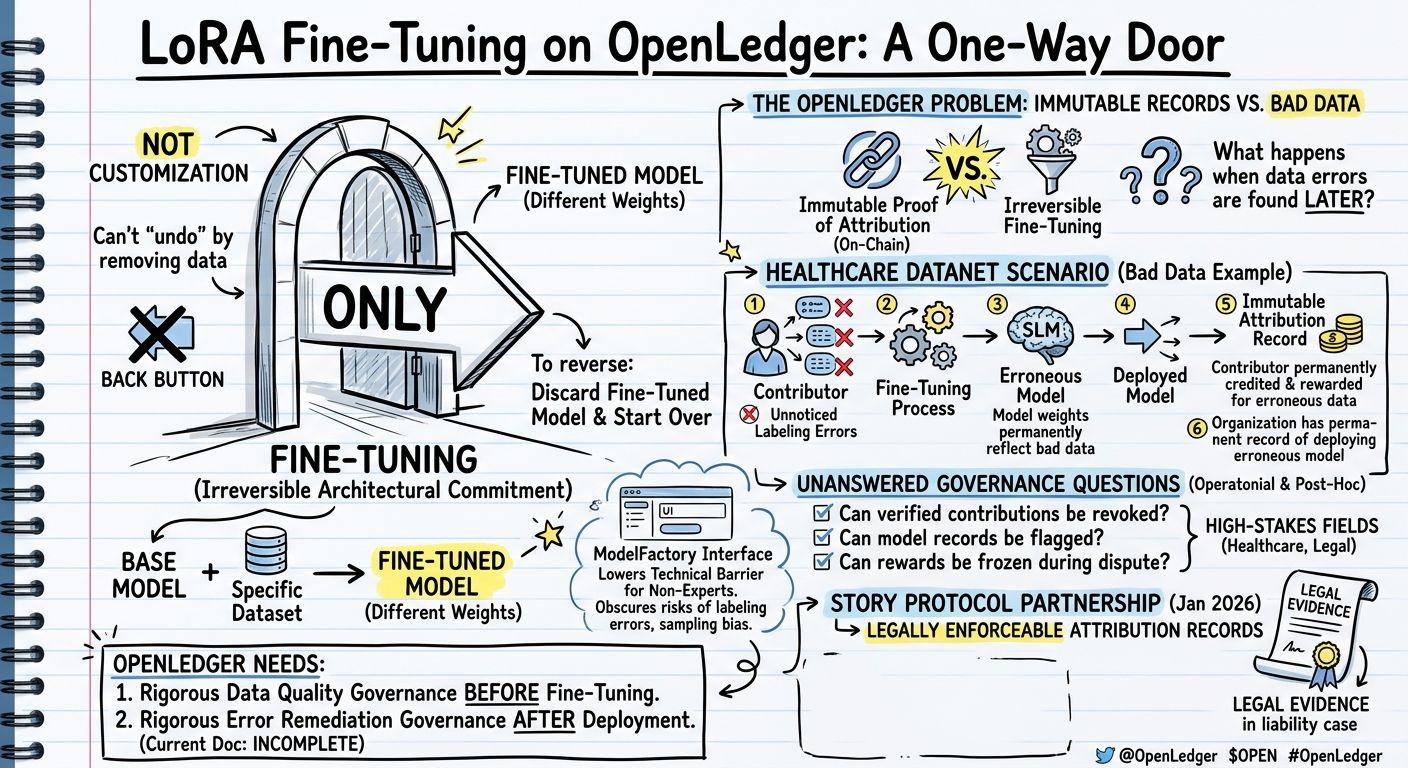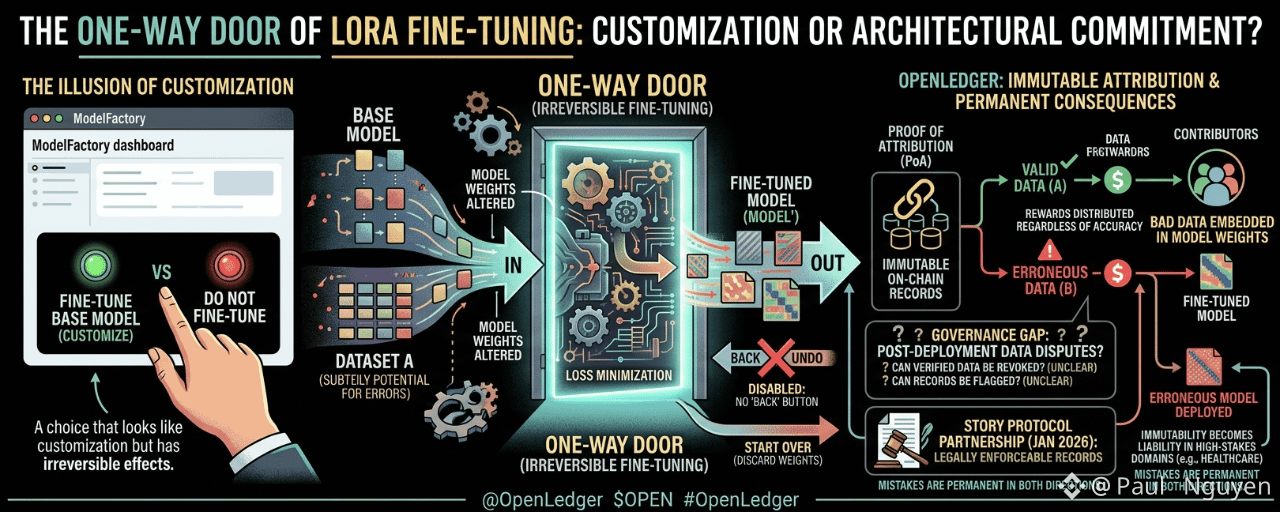
There is a decision that every model builder on OpenLedger's ModelFactory makes when they launch a fine-tuning run, a decision that is presented in the interface as a customization choice but that is actually closer to an irreversible architectural commitment. The decision is to fine-tune a base model on a specific dataset. Once you do it, you have a new model that performs differently from the base in ways that cannot be cleanly undone. You cannot "undo" a fine-tuning run by removing the data. You can fine-tune the model again on different data, which changes it further. You can revert to the original base model and start over, discarding the fine-tuned weights. But the specific fine-tuned model, trained on your specific data at that point in time, is a one-way door. The base model going in is not the same as the fine-tuned model coming out, and there is no back button.
OpenLedger's Proof of Attribution system is designed to trace which training data influenced which model output, and it records this lineage immutably on-chain. The immutability is the right design for the attribution economy: if attribution records could be altered, contributors could not trust that their reward shares would remain accurate over time. But the combination of immutable attribution records and irreversible fine-tuning creates a specific situation that the documentation does not address explicitly: what happens when the training data that a model was fine-tuned on turns out to have been wrong, manipulated, or legally encumbered?
Imagine a healthcare Datanet contributor uploads a dataset that contains labeling errors. The errors are not obvious, the data passed OpenLedger's verification process, and a medical SLM is fine-tuned on the erroneous data. The model is deployed. Queries are run. Attribution rewards are distributed proportionally to the data contributors, including the contributor whose erroneous dataset is now part of the model's weights. The attribution record is on-chain and immutable. The fine-tuning is irreversible. Even if the data error is discovered later, the model's weights already reflect the influence of the bad data. Re-training on corrected data produces a different model, but the original fine-tuned model and its attribution record still exist on-chain. The contributor who uploaded erroneous data has on-chain evidence of their contribution and has received rewards for it. The organization that deployed the erroneous model has a permanent on-chain record of having done so.
OpenLedger's response to this scenario depends on how its governance and data quality systems handle post-hoc data quality disputes. The documentation describes an on-chain verification process for contributions, but does not specify what happens when a verified contribution is later found to be erroneous. Can a verified contribution be revoked? Can a model's attribution record be flagged as based on disputed data? Can the governance system freeze rewards to a contributor whose data has been found erroneous while a review is ongoing? These are operational governance questions that matter enormously for an AI attribution system operating in healthcare or legal contexts where erroneous training data has real-world consequences, and they are not answered in the public documentation.
ModelFactory's no-code interface lowers the technical barrier for contributors who may not have the ML expertise to recognize when their data is formatted in a way that will cause labeling errors, sampling biases, or other quality problems in the resulting model. The interface is accessible. The consequences of training a model on bad data and deploying it are not accessible: they are obscured behind the clean training dashboard and the attribution reward distribution. OpenLedger needs a data quality dispute and remediation framework that addresses post-deployment data error discovery. Without it, the combination of immutable records and irreversible fine-tuning creates a system where mistakes are permanent in both directions: good data contributions are permanently credited, and bad data contributions are permanently embedded in model weights and permanently recorded as valid on-chain.
The Story Protocol partnership from January 2026 adds legal enforceability to attribution records, which makes the permanence of those records both more valuable and more consequential. A legally enforceable attribution record for a healthcare model trained on erroneous data is not just a blockchain entry. It is a legal document that could be used as evidence in a liability case involving that model's clinical outputs. OpenLedger is building the infrastructure for a high-stakes domain. The irreversibility of fine-tuning and the immutability of attribution records are the right properties for a functioning attribution economy. They are also properties that demand rigorous data quality governance before a model is fine-tuned and rigorous error remediation governance after deployment. The current documentation describes the first part incompletely and the second part not at all.