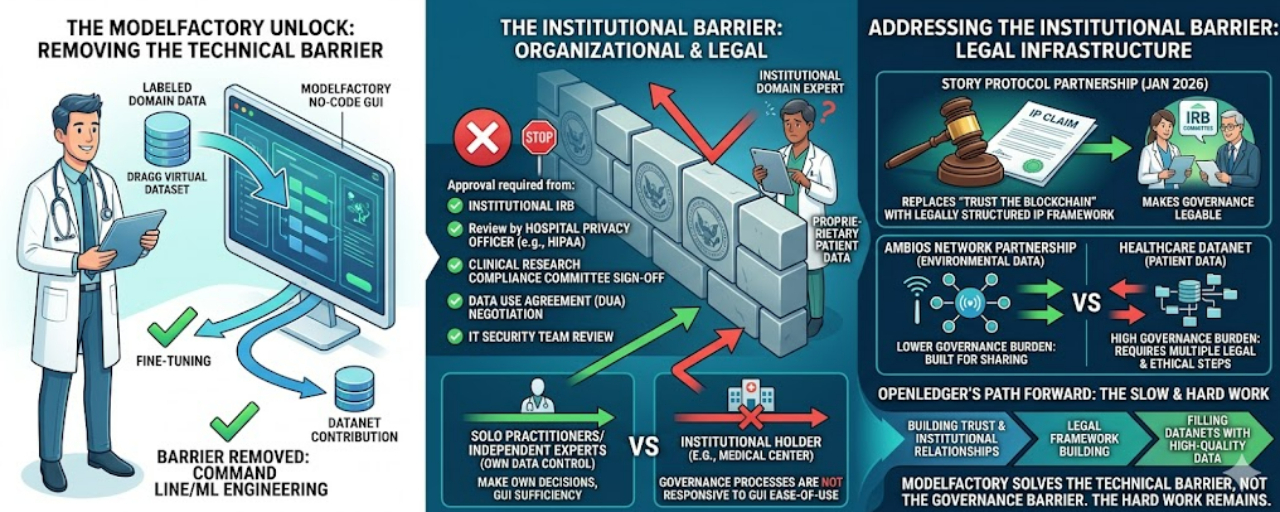
Something I noticed about six months into following OpenLedger closely is that the project's communication around ModelFactory consistently frames the no-code interface as the key unlock for domain expert participation. Remove the ML engineering requirement, the argument goes, and the radiologists, lawyers, and financial analysts who hold the most valuable domain data will start contributing it to the platform. The framing is clean and the interface genuinely works, I have tested it. The problem is that the barrier preventing most institutional domain experts from contributing proprietary data to OpenLedger is not the command line. It has never been the command line. It is the organizational and legal infrastructure that sits between a domain expert's knowledge and any external platform they might contribute it to.
Let me make this concrete. I have a friend who is a research coordinator at a large academic medical center. She has access to years of de-identified patient data from clinical trials, structured, labeled, and genuinely valuable for medical AI development. She is technically capable of using OpenLedger's ModelFactory. She is not technically intimidated by a GUI. The reason she cannot contribute that data to OpenLedger's healthcare Datanet is not that she does not understand LoRA fine-tuning. It is that doing so would require: approval from her institution's IRB, review by the hospital's privacy officer under HIPAA, sign-off from the clinical research compliance committee, a data use agreement between the medical center and OpenLedger's legal entity, and probably a review by the hospital's IT security team of OpenLedger's data handling infrastructure. That process takes months. It involves multiple stakeholders who have no relationship with OpenLedger and whose default answer to "should we contribute patient-adjacent data to a blockchain platform" is going to be no.
OpenLedger cannot solve that problem with a better GUI. ModelFactory's no-code interface is genuinely valuable for domain experts who own their own data and can make their own contribution decisions without institutional approval. A solo practitioner with a private patient panel, a solo attorney with their own casefile system, a freelance financial analyst with proprietary research notes: these contributors can evaluate OpenLedger's platform and contribute without navigating institutional procurement. But the most valuable data in healthcare, law, and finance is not held by solo practitioners. It is held by institutions, and institutions have governance processes that are not responsive to ease-of-use improvements in a fine-tuning interface.
The Story Protocol partnership from January 2026 is the most meaningful thing OpenLedger has done to address the institutional barrier, because it replaces "you have to trust the blockchain" with "you have a legally structured IP claim." An IRB committee reviewing a data contribution proposal can understand a legal IP licensing framework more readily than it can evaluate a blockchain attribution mechanism. Story Protocol's framework gives OpenLedger's platform a legal vocabulary that institutional governance committees know how to process. That is a genuine step toward the institutional contributor problem. It does not solve the IRB approval requirement, the HIPAA compliance review, or the data use agreement negotiation. It makes one leg of the table more sturdy without building the other three.
OpenLedger's documentation mentions the Ambios Network partnership for environmental AI data, which is an interesting reference point. Environmental sensor data collected by a network like Ambios does not have the same institutional custody and governance requirements as clinical patient data. It is collected for the purpose of being shared and analyzed. Contributing it to OpenLedger's ecosystem is a structurally simpler act than contributing hospital records. If OpenLedger builds its early Datanet success stories around environmental data, IoT data, and other lower-governance-burden data types, it may develop the track record and the institutional relationships needed to eventually navigate the healthcare and legal data governance processes. That is a reasonable path. It is also a slower path than the "doctors use ModelFactory" narrative implies.
The honest framing of what ModelFactory solves is: it removes the technical barrier for the contributor population that does not have institutional data governance constraints. That population exists, it includes solo practitioners, independent researchers, and individual domain experts, and it is worth serving. But it is not the population that holds the highest-quality proprietary domain data in the categories where OpenLedger's SLM focus is most commercially valuable. The technical barrier removal was the right first step. The institutional relationship development and legal framework building that comes after it is the harder and slower work that will determine whether OpenLedger's Datanets fill with data that is good enough to matter.
@OpenLedger $OPEN #OpenLedger $BSB
