I almost skipped @OpenLedger entirely. Saw "AI blockchain" in the description and my brain auto-filed it next to every other project that slapped those two words together and called it innovation. I've been in crypto long enough to know that combo usually means nothing ships.
But something made me go deeper. And I'm glad I did.
The thing most people miss about this space is that everyone is racing to build AI compute infrastructure. Cheaper GPUs. Faster inference. More nodes. That's a real market but it's also a race to zero on margins. Compute gets cheaper every year. It always has. So the teams building purely around compute are basically competing to become a utility.
OpenLedger is not doing that.
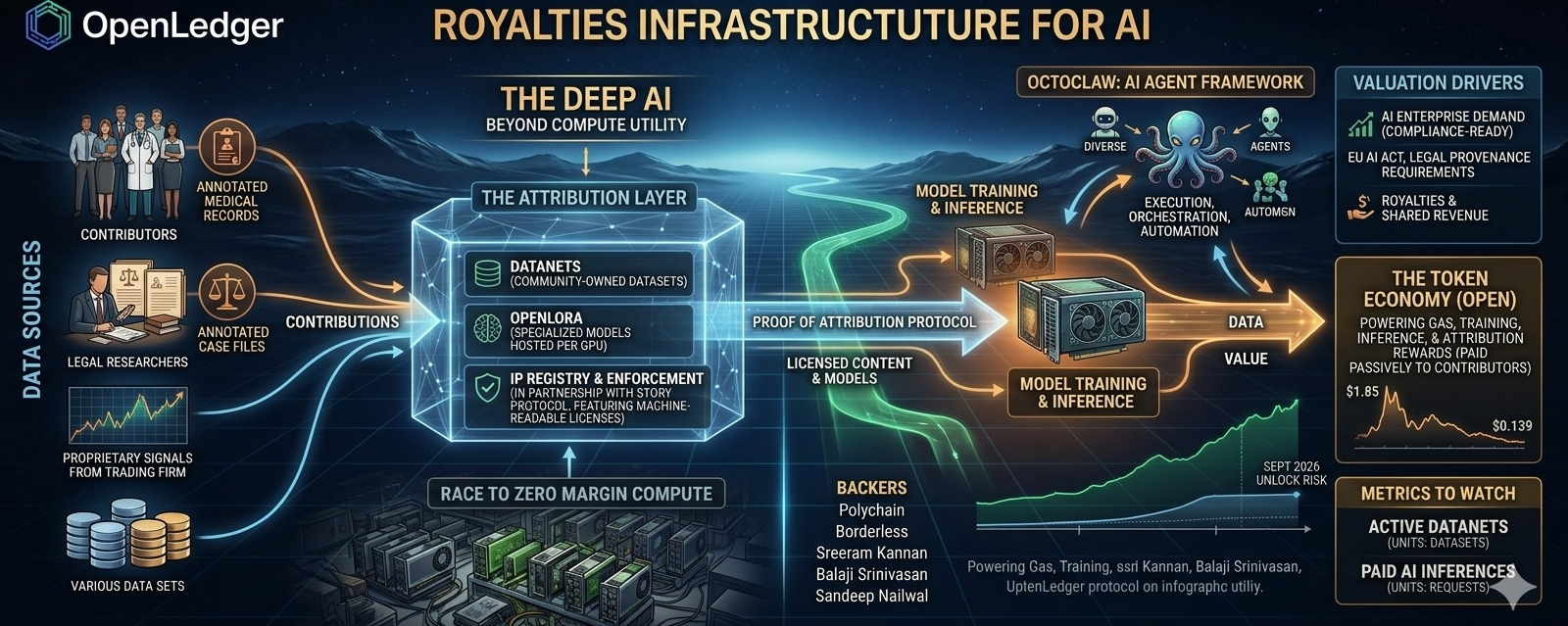
The whole protocol is built around Proof of Attribution. Every dataset, every training run, every model inference gets recorded on-chain so the people who contributed the data get credited and paid when their work actually produces value.
When I really sat with that, it clicked. This is not an AI chain. It's a royalties infrastructure. And those two things are priced completely differently in the long run.

Think about what happens today when someone uploads a dataset to train an AI model. A startup scrapes it. Fine-tunes a product on it. Makes money. The person who built the dataset gets nothing. Not because anyone is malicious, just because there's no receipt. No trail. No mechanism to even make a claim. The contribution just disappears into the model.
OpenLedger's answer to this is what they call "Data-as-a-Shared-Service." Data producers plug into AI supply chains and earn passively as models keep consuming their work. The royalty logic is in the protocol, not negotiated in some contract after the fact.
The most recent thing that got my attention was OctoClaw dropping in early May. It lets you build, automate, and execute with AI agents in real time, picking your own provider and model, with a configurable intelligence layer powering the agent's decisions.
I know "AI agent framework" sounds like every other pitch right now. But the difference here is that when OctoClaw's agent makes a decision, it's pulling from data and models that are already registered on OpenLedger's attribution layer. The protocol knows whose work contributed to that output before the result even surfaces. Monetization is not something you add later. It's already there.
It also pulls together execution, orchestration, and automation in one place, so you're not stitching together five different tools to run a single workflow. That friction reduction matters more than most people give it credit for. Developers don't leave protocols because of bad tokenomics. They leave because the developer experience is annoying.
The partnership with Story Protocol back in January was quietly one of the most important moves in the AI infrastructure space and most people just scrolled past it.
Story Protocol handles the IP registry side, defining ownership, licensing terms, and economic rights in a format machines can actually read and enforce. OpenLedger handles execution and verification, enforcing those licenses during training and inference and routing payments the moment licensed content shapes a model's behavior or output.
The team put it plainly. The shift is from "train now, litigate later" to "use only what you can prove you're allowed to use."
Every enterprise legal team in 2026 is asking their AI vendors where the training data came from. The EU AI Act is in effect. Copyright lawsuits against AI labs were everywhere last year. OpenLedger and Story Protocol just built the answer to that question into the infrastructure itself. That's not a feature you add to win a pitch deck. That's a procurement requirement for serious buyers.
On the token side, I'll be honest. OPEN launched at $1.85 and hit its low around $0.139 in January 2026. That's a rough chart. But I don't think that chart tells you the project failed. I think it tells you the demand was theoretical at launch and the market priced it accordingly.
OPEN powers gas, model training, inference costs, and attribution rewards across the whole system. That demand is tied to real usage, not speculation. When a Datanet gets queried or an OctoClaw agent runs a task, OPEN moves. That's the kind of token utility that actually means something over time.
The real thing to watch is the unlock schedule hitting around September 2026. New supply starts entering the market monthly from that point and the question is whether actual ecosystem demand grows fast enough to absorb it. That's the honest risk. I'm not pretending it isn't there.
What keeps me genuinely interested is the tooling depth. Datanets for community-owned datasets, ModelFactory for no-code fine-tuning, and OpenLoRA for hosting thousands of specialized models per GPU. That last part matters for a use case people aren't talking about enough. A doctor with a curated medical dataset, a legal researcher with years of annotated case files, a trading firm with proprietary signals. None of them have hyperscaler budgets. OpenLoRA gives them a path to deploy and monetize without needing one.
The early backers include Polychain Capital, Borderless Capital, and angels like Sreeram Kannan from EigenLabs, Balaji Srinivasan, and Sandeep Nailwal from Polygon. I pay more attention to the angel list than the lead investors these days. Sreeram built EigenLayer around restaking primitives. Balaji has been writing about data ownership since before most of this space existed. These are not people who write checks into vaporware.
The two numbers I'm personally watching are active Datanets and paid AI inferences. Not price. Not daily volume. Those metrics will tell me whether real participants are earning real money inside the protocol. Everything else is just noise until those numbers move.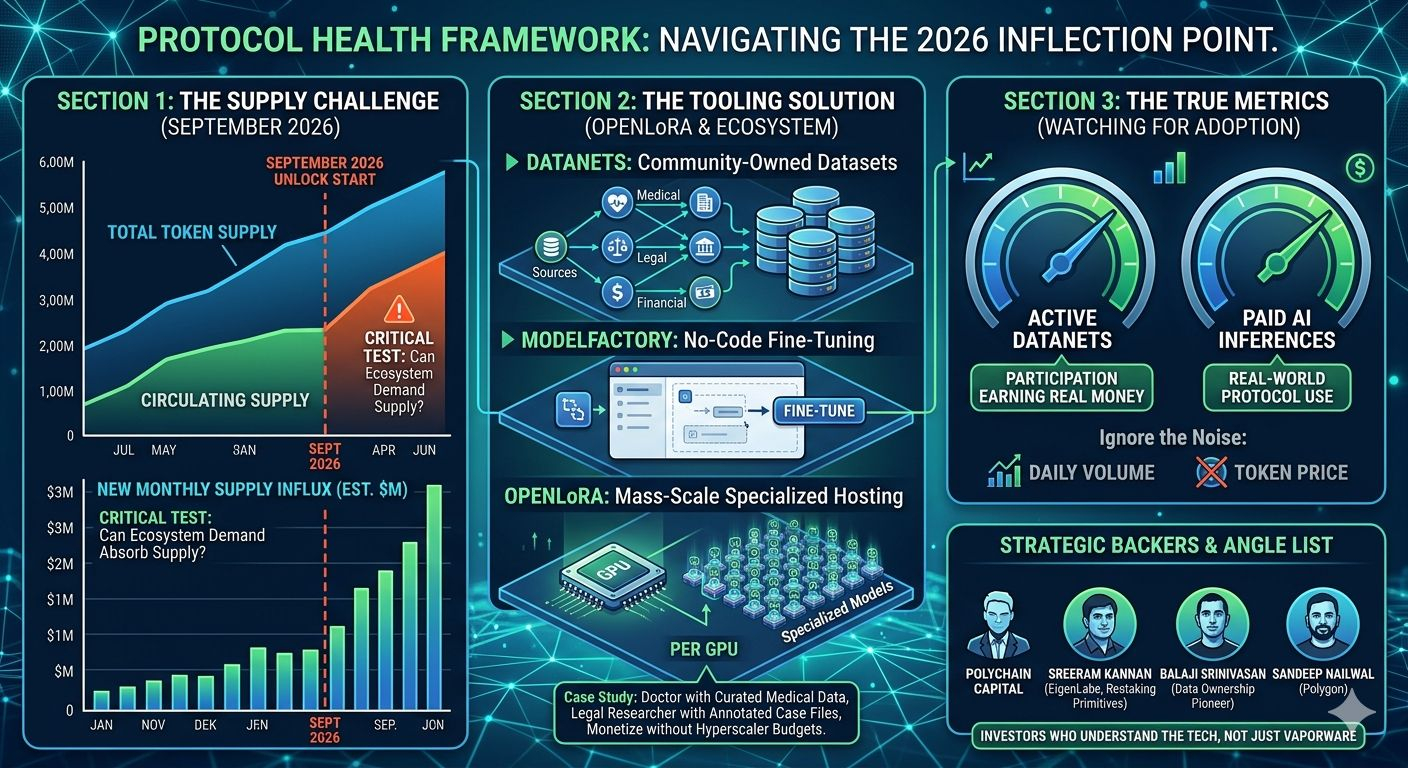
The question I keep sitting with is this: if attribution becomes the baseline compliance standard for enterprise AI, and OpenLedger already built the infrastructure to satisfy it, who else is even close to solving this problem at the protocol level?