For most of the current AI cycle, the industry has been obsessed with training scale. Parameter counts became the scoreboard. Every major release turned into another arms race around compute budgets, GPU clusters and who could afford to burn the most capital pushing foundation models a little further.
That framing misses where the real operational pressure is starting to build.
Training is expensive, but inference is where the recurring economics accumulate. Once systems move from demos into persistent production workloads, serving architecture starts determining whether an AI product is actually viable at scale or just technically impressive. The difference matters more than most people realize.
This is exactly why LoRA-based infrastructure has become strategically important.
The industry is drifting away from the assumption that one giant general-purpose model will dominate every workload. In practice, specialized systems consistently outperform broad models inside constrained domains: finance, legal review, biotech research, regional language processing, enterprise copilots, industrial workflows, gaming agents, internal knowledge systems. The pattern keeps repeating. Narrow context plus targeted fine-tuning usually beats brute-force generalization.
That creates an infrastructure problem almost immediately.
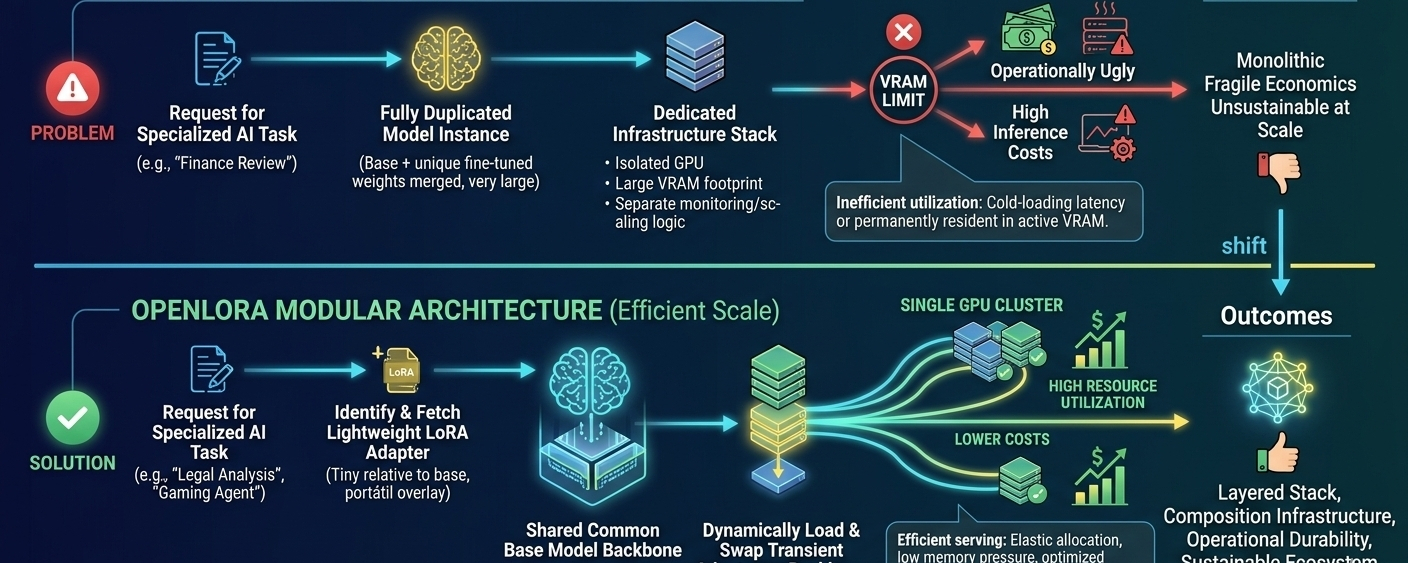
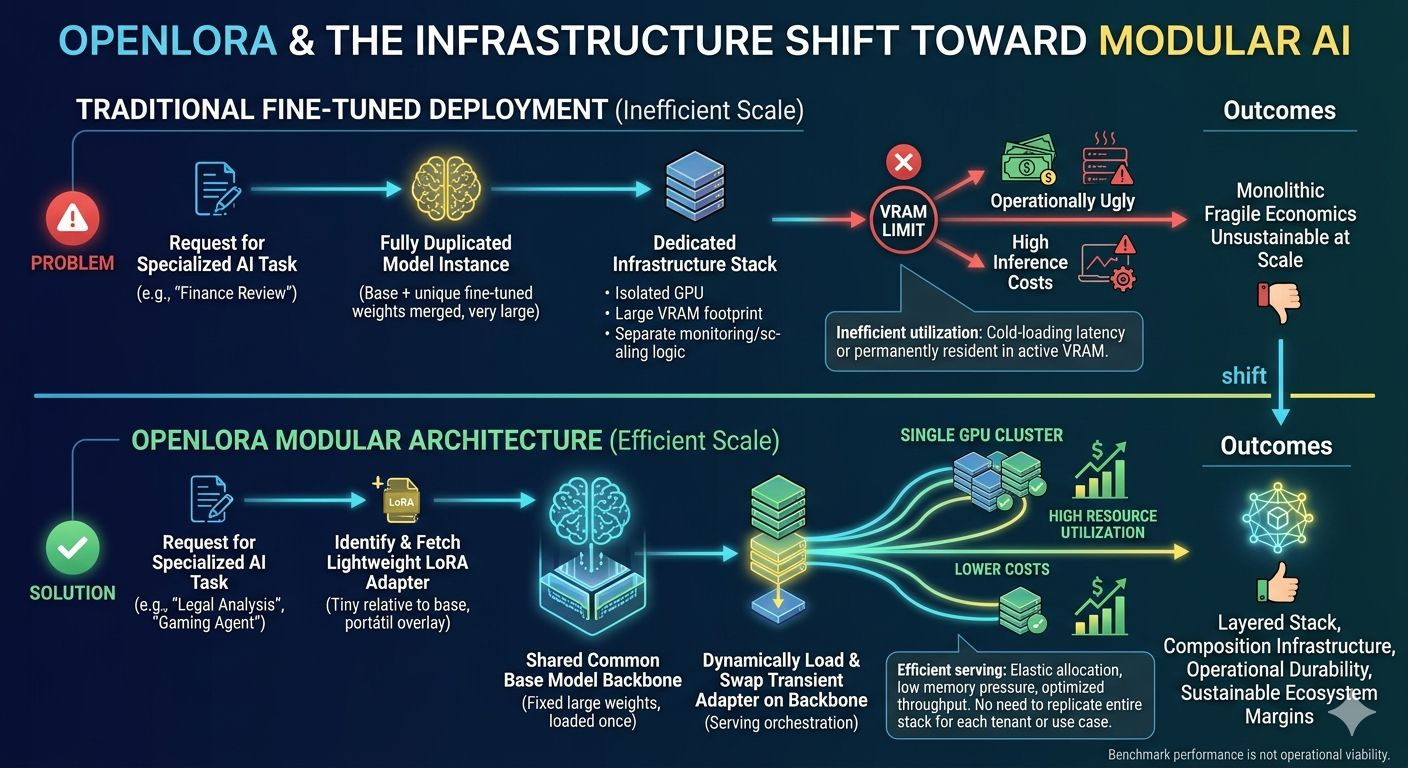
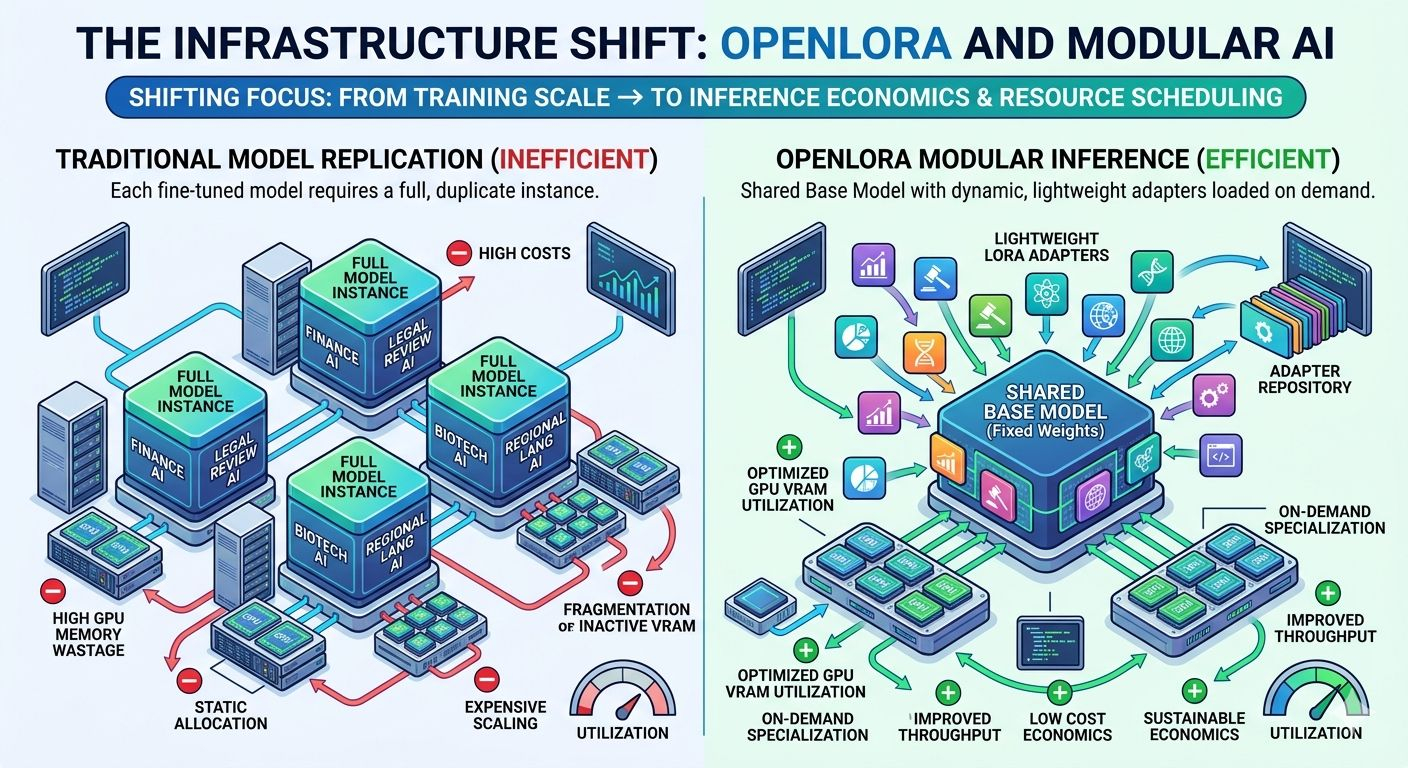
If every fine-tuned model requires its own dedicated deployment stack, separate GPU allocation, isolated memory footprint, monitoring layer, optimization pipeline, and autoscaling logic, the economics deteriorate fast. A few models are manageable. A few thousand become operationally ugly.
OpenLoRA sits directly in that gap.
The core idea is straightforward: keep the base model shared and treat LoRA adapters as modular overlays that can be loaded dynamically at inference time. Instead of deploying hundreds or thousands of fully duplicated model instances, the system swaps lightweight adapters onto a common backbone as requests arrive.
From a systems perspective, this is less about “AI magic” and more about resource scheduling.
GPU memory is the hard constraint in most inference environments. Traditional serving architectures waste large amounts of VRAM keeping inactive fine-tuned models resident in memory simply because cold-loading them later introduces latency penalties. OpenLoRA changes the tradeoff. Adapters become transient runtime components instead of permanently allocated infrastructure objects.
That distinction sounds subtle until you run the numbers.
A LoRA adapter is tiny relative to the underlying base model. The expensive weights stay fixed. The specialization layer becomes portable. Suddenly a single GPU cluster can service large volumes of heterogeneous workloads without replicating the entire stack for each tenant or use case. Utilization improves. Fragmentation drops. Throughput becomes easier to optimize because the serving layer is orchestrating lightweight deltas instead of shuffling massive independent models around.
This is where a lot of the current market narrative around “open AI ecosystems” still feels underdeveloped. People talk endlessly about decentralized AI, community-owned models, or specialized data economies, but very few discussions go deep into the serving economics required to make those systems sustainable.
Specialization sounds attractive until somebody has to pay the inference bill.
A network like OpenLedger naturally pushes toward fragmentation by design. Different contributors produce different datasets. Different teams train domain-specific adapters. Different applications require different behaviors, safety layers, or retrieval patterns. The result is not one monolithic intelligence layer. It is a distributed mesh of highly specialized inference paths.
Without efficient serving infrastructure underneath, that model breaks economically.
You cannot build a large-scale ecosystem of modular intelligence if every adapter behaves like a fully independent deployment unit. The overhead compounds too quickly. GPU allocation becomes inefficient, latency management gets harder, and infrastructure costs start consuming the value generated by the models themselves.
OpenLoRA’s architecture is important precisely because it treats specialization as the default state of the ecosystem, not the exception.
The dynamic adapter-loading approach matters here more than the branding around it. Adapters can be fetched from repositories like Hugging Face, internal registries, or custom storage systems only when inference actually requires them. Inactive models stop occupying expensive memory resources. The serving layer becomes elastic rather than static.
That aligns with how real production workloads behave anyway.
Enterprise traffic is rarely uniform. One burst of requests might target a financial analysis adapter; the next minute the system pivots toward multilingual support or retrieval-heavy research inference. Static allocation strategies perform badly in those environments because infrastructure gets provisioned around peak assumptions instead of actual utilization patterns.
Modern inference stacks already rely heavily on aggressive optimization techniques quantization, paged attention, tensor parallelism, flash attention, speculative decoding, KV cache management. OpenLoRA fits into that same operational philosophy: squeeze more useful work out of constrained hardware instead of endlessly scaling raw compute.
And frankly, that is where the industry is heading whether the hype cycle acknowledges it or not.
There is also a broader architectural shift happening underneath all of this. Early generative AI systems were designed like monoliths. One model handled everything: reasoning, style, domain knowledge, behavioral alignment, retrieval orchestration, task execution. It worked for proving capability, but it is an inefficient way to structure mature systems.
The stack is becoming layered.
Base models provide generalized reasoning capacity. Adapters inject domain specialization. Retrieval systems handle context. External tools execute deterministic operations. Orchestration layers route requests dynamically depending on workload characteristics. The future inference environment looks less like a single giant neural network and more like distributed systems engineering with probabilistic components.
OpenLoRA makes sense inside that world because it treats fine-tuned intelligence as composable infrastructure rather than isolated artifacts.
That distinction is important.
A lot of AI companies are still optimizing for leaderboard perception instead of operational durability. Benchmark improvements generate attention, but infrastructure efficiency determines margins. At scale, small differences in utilization rates, memory pressure, or inference scheduling compound into enormous cost disparities.
The companies that survive long term probably will not be the ones with the flashiest demos. They will be the ones capable of serving increasingly fragmented and specialized workloads without destroying their economics in the process.
That is the part of the AI stack people tend to underestimate right until the GPU invoices arrive.
