Most people still talk about AI the same way they talked about cloud computing years ago.
More scale.
More compute.
Bigger models.
Faster responses.
And honestly, that made sense for a while because the entire AI race was basically about who could train the largest systems first.
But lately I keep thinking the market may be looking at the wrong layer completely.
The real bottleneck probably is not intelligence anymore.
It is ownership.
Who owns the data?
Who gets rewarded when AI becomes profitable?
Who actually benefits after contributing knowledge, corrections, feedback, or training material?
Right now, most AI systems work like giant black holes for information. People feed them data every single day, models improve quietly in the background, companies make billions, and the original contributors disappear from the economic side entirely.
That model works early on.
I am not sure it works forever.
That is one reason why OpenLedger has been getting more attention lately.
At first glance, OpenLedger looks like another AI + blockchain project. The market already has hundreds of those. Most talk about decentralized AI, compute layers, inference marketplaces, or GPU coordination.
But OpenLedger’s actual focus feels different once you spend time researching it.
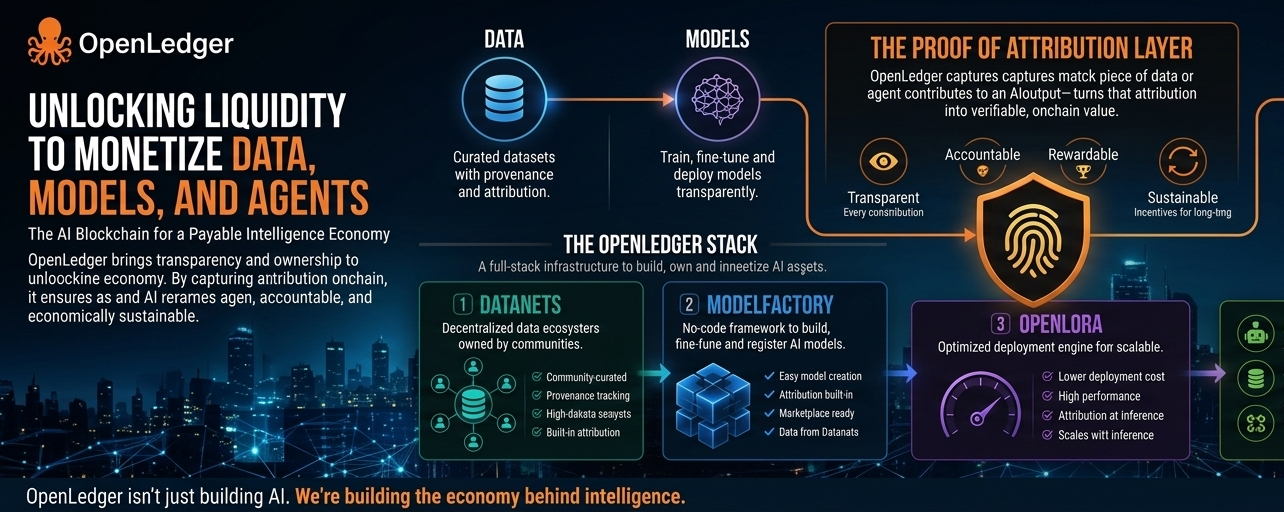
The project is building infrastructure around something much more specific: attribution.
Not just storing AI onchain.
Actually tracking who contributed to intelligence creation and making those contributions economically measurable.
That changes the conversation completely.
Instead of asking:
“How do we build bigger AI?”
OpenLedger is asking:
“How do we build AI economies where contributors are visible?”
That is a much bigger problem than most people realize.
The current AI industry runs on invisible labor.
Every dataset, correction, annotation, feedback loop, human preference adjustment, or specialized contribution improves the quality of models. But most contributors never receive long-term upside after the model becomes commercially successful.
OpenLedger thinks blockchain can fix part of that.
The core idea behind the network is called Proof of Attribution.
The concept is relatively simple to explain but much harder to build technically.
The system attempts to track how datasets, models, and contributors influence AI outputs over time. Instead of contributions disappearing inside a giant centralized model, OpenLedger wants them recorded transparently so contributors can continue earning value whenever their data or intelligence helps generate outcomes later.
That creates a completely different economic structure for AI.
Normally, AI companies monetize access.
OpenLedger wants AI systems to monetize participation.
And honestly, that shift feels bigger than people currently understand.
Because once attribution exists properly, data itself becomes programmable.
Contributors stop being invisible.
Specialized knowledge becomes monetizable.
AI models become connected to the people who improved them.
That starts looking less like traditional software and more like a functioning digital economy.
One thing I found especially interesting while researching OpenLedger is how heavily the project focuses on specialized AI instead of giant general-purpose models.
That actually makes a lot of sense.
The market spent years chasing massive frontier models because bigger felt more impressive. But practical AI systems increasingly seem to reward specialization instead.
A healthcare AI trained on verified medical datasets may matter more than a huge generic model.
A finance-focused AI trained on real market intelligence may outperform broader systems for trading analysis.
A legal AI built around trusted legal datasets may become far more valuable than generalized outputs.
OpenLedger’s infrastructure seems designed around that exact direction.
The project introduces something called Datanets, which are basically decentralized environments where communities can build and manage specialized datasets together.
Think about that for a second.
Instead of AI models scraping random internet information endlessly, specialized communities could theoretically create higher-quality datasets while keeping attribution attached permanently.
That changes incentives entirely.
Because if contributors know they continue benefiting from usage later, they suddenly have a reason to maintain quality instead of just dumping information into systems for free.
The project also built systems like ModelFactory and OpenLoRA to help developers create, fine-tune, and deploy AI models more efficiently.
But honestly, I think the infrastructure matters less than the direction itself.
The bigger narrative here is that OpenLedger is treating AI like an economy instead of a product.
That feels important.
Especially now that autonomous AI agents are becoming a real discussion across crypto and tech.
Most people still imagine AI as chatbots or assistants.
But the next phase probably looks very different.
AI agents will likely manage wallets.
Execute trades.
Purchase compute.
Access datasets.
Run workflows.
Coordinate applications.
Interact with smart contracts.
Maybe even negotiate with other agents autonomously.
Once that happens, attribution suddenly becomes critical infrastructure.
Because if AI systems become economic actors themselves, markets eventually need ways to track where intelligence originated and who deserves compensation.
Without attribution, value extraction becomes infinite.
With attribution, AI economies start becoming sustainable.
That is basically the larger OpenLedger thesis.
And honestly, it feels much more aligned with where AI is heading than many of the simpler “AI token” narratives floating around the market right now.
Another thing that caught my attention was OpenLedger’s collaboration around rights-cleared AI training systems.
That part matters more than people think.
The AI industry is slowly moving toward a collision with intellectual property laws, creator rights, and dataset ownership questions. Right now the space still operates in a gray area because regulation has not fully caught up yet.
But eventually, large-scale AI systems will probably need clearer proof showing:
where training data came from,
whether contributors approved usage,
and how creators get compensated.
OpenLedger seems to be preparing for that future early instead of waiting for the problem later.
And that may end up being one of the project’s strongest positioning advantages.
Because infrastructure built before regulation usually becomes more valuable once regulation arrives.
Of course, none of this guarantees success.
The technical challenges here are massive.
Tracking attribution accurately across complex AI systems is extremely difficult.
Reward systems can be manipulated.
Dataset quality becomes hard to verify.
Scaling decentralized infrastructure against centralized AI giants is also incredibly hard.
But the direction itself feels very real.
AI is slowly evolving beyond software.
It is becoming economic infrastructure.
And once intelligence becomes monetizable at scale, the question is no longer just:
“Which AI is smartest?”
The bigger question becomes:
“Who gets paid when intelligence creates value?”
That is the part OpenLedger is trying to solve.
And honestly, I think the market still underestimates how important that problem may become over the next few years.

