Die KI-Revolution hat eine der seltsamsten wirtschaftlichen Ungleichgewichte in der modernen Technologie geschaffen. Die Unternehmen, die große Modelle entwickeln, gehören zu den wertvollsten Organisationen in der Menschheitsgeschichte, während die Menschen, die das Rohmaterial für diese Systeme liefern, größtenteils unsichtbar bleiben. Jedes KI-Modell basiert auf einem Ozean menschlicher Beiträge: Schreiben, Gespräche, Verhalten, Code, medizinische Aufzeichnungen, finanzielle Muster, Bilder, Übersetzungen, Forschung, Anmerkungen, Klicks, Korrekturen und gelebte Erfahrungen. Doch sobald diese Informationen in die Maschine gelangen, verschwindet das Eigentum fast vollständig. Das Modell wird wertvoll. Die Mitwirkenden treten in den Hintergrund.
Dieses Ungleichgewicht liegt ruhig unter dem Aufstieg von OpenLedger.
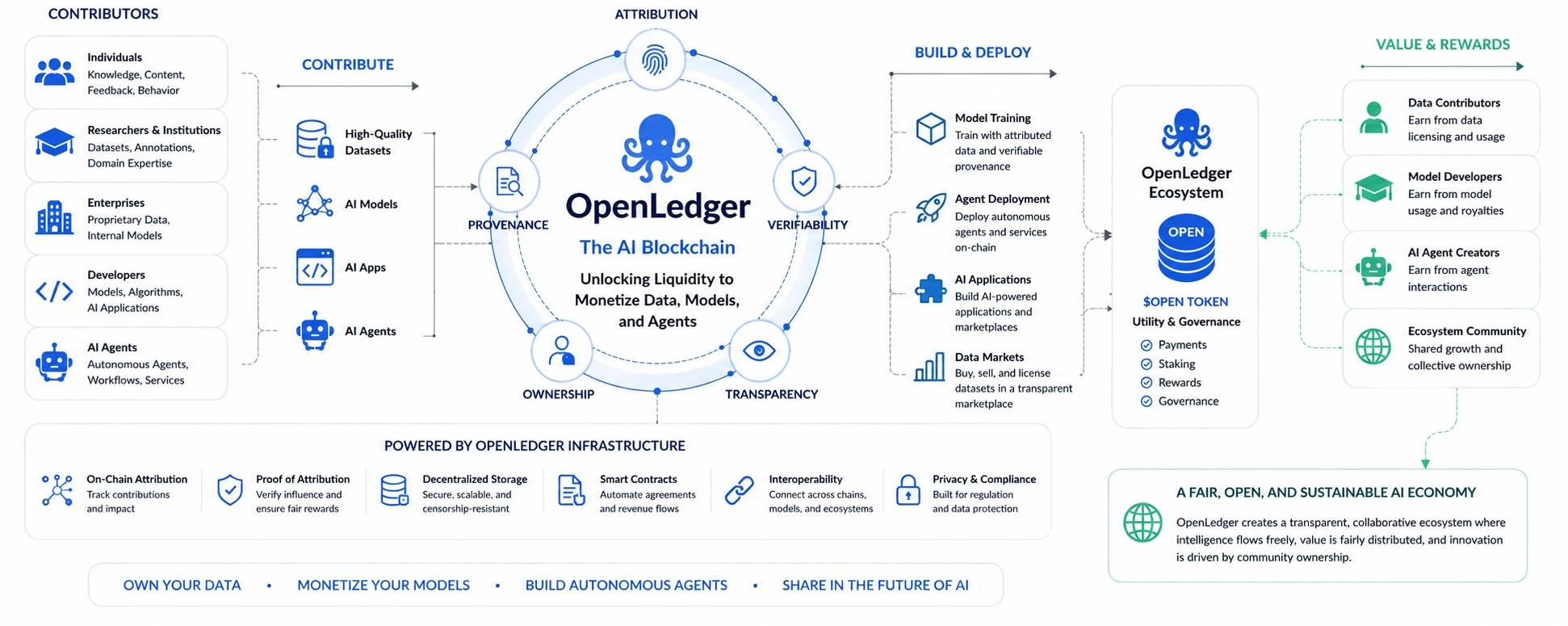
Auf den ersten Blick sieht OpenLedger aus wie ein weiteres Projekt, das versucht, Blockchain und künstliche Intelligenz zusammenzuführen, was ein zunehmend überfüllter Raum ist, der mit übergroßen Versprechungen und vagen Erzählungen gefüllt ist. Aber unter der Oberfläche des Brandings verfolgt das Projekt eine viel tiefere Idee. Es versucht, die Art und Weise, wie Wert durch KI-Systeme fließt, neu zu gestalten. Anstatt Daten wie wegwerfbaren Treibstoff zu behandeln, der für immer von zentralisierten Modellen verschlungen wird, möchte OpenLedger, dass Intelligenz wirtschaftlich nachverfolgbar wird. Seine gesamte Philosophie dreht sich um einen einfachen, aber kraftvollen Glauben: Wenn Daten zur Intelligenz beitragen, dann sollten die Menschen und Systeme hinter diesen Daten nicht verschwinden, sobald die KI profitabel wird.
Das verändert das Gespräch komplett.
Die meisten KI-Unternehmen funktionieren wie riesige Extraktionsmaschinen. Sie absorbieren Informationen in großem Maßstab, verfeinern sie zu Modellen und bauen dann kommerzielle Produkte darauf auf. Der Wertfluss ist größtenteils vertikal. Informationen bewegen sich nach oben in zentralisierte Systeme, und die Einnahmen folgen demselben Pfad. OpenLedger versucht, diesen Zyklus zu unterbrechen, indem es Attribution, Provenienz und programmierbares Eigentum direkt in die KI-Pipeline einführt. In seiner idealen Form verschwindet Daten nicht einfach in einer Black Box. Es hinterlässt Fingerabdrücke. Diese Fingerabdrücke können verfolgt, gemessen und schließlich monetarisiert werden.
Deshalb ist OpenLedger über die übliche Krypto-Erzählung hinaus von Bedeutung. Die Blockchain-Komponente ist nicht wirklich das Zentrum der Geschichte. Die eigentliche Geschichte ist der Versuch, ein wirtschaftliches System für Intelligenz selbst zu schaffen.
Diese Idee wird wichtiger, je tiefer KI in die Gesellschaft eindringt. Im Moment denken die meisten Menschen immer noch an KI als ein Produkt: Chatbots, Assistenten, Bildgeneratoren, Empfehlungsmaschinen. Aber die Technologie wird allmählich zur Infrastruktur. Sie zieht in Gesundheitssysteme, Finanzmärkte, Bildung, Logistik, wissenschaftliche Forschung, juristische Analysen, Sicherheitsoperationen und autonome Software-Agenten ein. Sobald KI in die Struktur alltäglicher Systeme eingebettet wird, werden Fragen rund um das Eigentum unvermeidlich. Wer besitzt die Trainingsdaten? Wer wird entschädigt, wenn ein Modell kommerziell erfolgreich wird? Welche Gemeinschaften profitieren, wenn lokales Wissen globale Systeme trainiert? Wie teilen Institutionen Informationen, ohne die Kontrolle darüber für immer aufzugeben?
Das sind die Arten von Problemen, die OpenLedger zu lösen versucht, bevor sie unmöglich zu entwirren werden.
Eines der interessantesten Konzepte des Projekts ist der Schwerpunkt auf Attribution. Traditionelle KI-Systeme sind notorisch schlecht darin, die Provenienz zu bewahren. Sobald Informationen in ein Modell gelangen, wird es schwierig, den genauen Einfluss nachzuvollziehen. Daten vermischen sich, komprimieren, mutieren und erscheinen in Weisen, die oft unmöglich klar zu kartieren sind. OpenLedgers Vision basiert auf der Idee, dass zukünftige KI-Ökosysteme ein besseres wirtschaftliches Gedächtnis benötigen. Nicht nur intelligentere Systeme, sondern Systeme, die in der Lage sind, aufzuzeichnen, woher die Intelligenz stammt und wie der Wert zurück an die Mitwirkenden fließen sollte.
Wenn sich das abstrakt anhört, denken Sie an die Musikindustrie. Streaming-Plattformen haben Songs in kontinuierlich monetarisierte Vermögenswerte verwandelt, bei denen Tantiemen theoretisch an Künstler zurückfließen könnten, wann immer ihre Arbeit Engagement erzeugt. OpenLedger stellt sich etwas Ähnliches für KI vor. Datensätze, Modelle und Agenten werden zu lebendigen wirtschaftlichen Einheiten und nicht zu statischen digitalen Objekten. Statt einmaliger Extraktion nehmen die Mitwirkenden an der fortlaufenden Wertschöpfung teil.
Diese Idee könnte letztendlich die Art und Weise, wie Organisationen mit KI interagieren, komplett umformen. Ein Krankenhaus mit wertvollen medizinischen Daten könnte Informationen bereitstellen, um spezialisierte Gesundheitsmodelle zu trainieren, während es Sichtbarkeit und wirtschaftliche Teilhabe behält. Eine Forschungseinrichtung könnte wissenschaftliche Datensätze monetarisieren, ohne die vollständige Eigentümerschaft aufzugeben. Gemeinschaften mit einzigartigem sprachlichem oder kulturellem Wissen könnten helfen, lokal angepasste KI-Systeme zu trainieren, während sie einen Anteil am entstehenden Ökosystem behalten. In diesem Rahmen hört Intelligenz auf, ein geschlossenes Produkt zu sein, und verhält sich eher wie ein offener Markt für Beiträge.
Was das Timing signifikant macht, ist, dass die KI-Branche sich in einer Phase befindet, in der die Datenqualität mehr zählt als die rohe Quantität. Frühe Modelle profitierten davon, massive Teile des Internets abzuschöpfen, aber diese Strategie beginnt zu schwächeln. Urheberrechtsklagen nehmen zu. Verlage schränken den Zugang ein. Regierungen richten mehr Aufmerksamkeit darauf. Unternehmen werden schützerischer gegenüber proprietären Informationen. Die nächste Generation von KI-Systemen wird wahrscheinlich weniger auf endlosem öffentlichem Scraping basieren und mehr auf spezialisierten, hochsignalisierten, vertrauenswürdigen Datensätzen. Das schafft ein völlig anderes wirtschaftliches Umfeld.
OpenLedger scheint für diesen Übergang konzipiert zu sein.
Die Weltanschauung des Projekts geht davon aus, dass zukünftiger KI-Wettbewerb nicht einfach darum geht, wer die größten Modelle besitzt. Es wird darum gehen, wer die wertvollsten Ökosysteme von Daten, Mitwirkenden, Agenten und Anwendungen koordinieren kann. Das ist eine ganz andere Sichtweise auf die Zukunft der künstlichen Intelligenz. Es verlagert den Fokus von zentralisierten Laboren hin zu vernetzten Intelligenzökonomien.
Es gibt auch eine politische Dimension, die in dieser Architektur verborgen ist. KI konzentriert schnell kognitive Macht in einer Handvoll Unternehmen, die in der Lage sind, Modelle, Infrastruktur, Vertrieb und zunehmend sogar öffentliche Informationsflüsse zu kontrollieren. Je fortschrittlicher diese Systeme werden, desto mehr Einfluss akkumuliert sich um die Organisationen, die sie besitzen. OpenLedger stellt eine Reaktion gegen diese Konzentration dar. Seine Philosophie tendiert zur Dezentralisierung, nicht nur im technischen Sinn, sondern auch im wirtschaftlichen Sinn. Es stellt sich eine Welt vor, in der Intelligenz geteilt, zugeordnet, monetarisiert und breiter verteilt werden kann, anstatt in wenigen intransparenten Systemen absorbiert zu werden.
Das ist eine ehrgeizige Vision, und allein die Ambition garantiert keinen Erfolg.
Die technischen Herausforderungen sind enorm. Attribution innerhalb von KI-Systemen bleibt zutiefst schwierig. Modelle zeigen nicht von Natur aus klare Karten, die zeigen, welche Datenstücke spezifische Ausgaben beeinflusst haben. Den Beitrag im großen Maßstab zu messen, ist eines der schwierigsten ungelösten Probleme im maschinellen Lernen. Selbst wenn sich die Attributionstechniken verbessern, bringen Anreizsysteme neue Komplikationen mit sich. Wann immer wirtschaftliche Belohnungen existieren, versuchen die Teilnehmer, diese zu optimieren. Niedrigqualitative Daten, Manipulation, Spam-Beiträge und künstliches Engagement könnten zu großen Problemen innerhalb offener Intelligenzmärkte werden.
Dann gibt es die einfache Realität des Wettbewerbs. Zentralisierte KI-Firmen bewegen sich extrem schnell, weil sie massive Recheninfrastrukturen, Elite-Forschungsteams, proprietäre Datensätze und globale Vertriebskanäle kontrollieren. Dezentrale Systeme kämpfen oft mit Koordination, Governance und Ausführungsgeschwindigkeit. OpenLedger versucht effektiv, ein alternatives wirtschaftliches Framework zu schaffen, das stark genug ist, um mit vertikal integrierten KI-Imperien zu konkurrieren. Das ist keine kleine Herausforderung. Es ist eine strukturelle.
Dennoch berührt das Projekt einen Nerv, weil es ein wachsendes Unbehagen im Hinblick auf die aktuelle KI-Landschaft anspricht. Immer mehr Menschen beginnen zu erkennen, dass sich das alte Extraktionsmodell des Internets in viel größerem Maßstab wiederholt. Plattformen monetarisierten einst die menschliche Aufmerksamkeit, während sie nur Fragmente des Wertes an die Nutzer zurückgaben. KI riskiert, die menschliche Intelligenz selbst auf ähnliche Weise zu monetarisieren. OpenLedger gehört zu einer breiteren Bewegung, die versucht, zu verhindern, dass diese Zukunft dauerhaft wird.
Seine Bedeutung könnte letztendlich weniger mit Token-Preisen oder spekulativen Zyklen zu tun haben und mehr damit, ob die Welt beginnt, Verantwortung für die Produktion von Intelligenz zu verlangen. Regulierungsbehörden stellen bereits schwierige Fragen zu Trainingsdaten, Urheberrecht, Vorurteilen, Transparenz und Erklärbarkeit. Unternehmen wollen Nachvollziehbarkeit. Institutionen wollen Rückverfolgbarkeit. Regierungen wollen Aufsicht. Aktuelle KI-Systeme kämpfen oft damit, klare Antworten zu geben, weil sie nicht von Anfang an um Provenienz herum designed wurden. Die Architektur von OpenLedger scheint direkt auf diese Schwäche abzuzielen.
In diesem Sinne könnte das Projekt weniger um Krypto-Spekulation und mehr um die Vorbereitung der Infrastruktur für eine Zukunft gehen, in der Intelligenz selbst eine Asset-Klasse wird. Nicht Software im traditionellen Sinne, sondern etwas, das näher an produktivem digitalem Kapital ist. Modelle erzeugen Ausgaben. Agenten führen Aufgaben aus. Daten verbessern kontinuierlich Systeme. Wirtschaftliche Belohnungen zirkulieren über Netzwerke, anstatt innerhalb zentralisierter Plattformen zu enden.
Diese Möglichkeit verändert, wie KI verstanden werden sollte. Die nächste Phase der künstlichen Intelligenz könnte nicht einfach darin bestehen, intelligentere Systeme zu bauen. Es könnte darum gehen, Eigentumsstrukturen um diese Systeme herum zu gestalten, bevor sie zu tief in die Gesellschaft eingebettet sind, um herausgefordert zu werden.
OpenLedger versucht letztendlich, eine Frage zu beantworten, die die Technologiebranche seit Jahren umgeht: Wenn Maschinen enormen Wert aus menschlichem Wissen generieren, wer hat dann das Recht, an den Erträgen teilzuhaben?
Diese Frage wird nicht verschwinden. Wenn überhaupt, wird sie zur definierenden wirtschaftlichen Frage des KI-Zeitalters.
