
Three browser tabs open & i have opened search browser and search open topic . the Story Protocol partnership announcement on the left. the EU AI Act enforcement timeline in the center. OpenLedger's Proof of Attribution architecture on the right. been sitting with this combinati0n for four days and honestly? the intersection these three documents create is the most underdiscussed setup in AI infrastructure right now 😂
not because the technology is new. because the timing suddenly makes the technology necessary in a way it wasn't twelve months ago.
The room where this becomes real
Picture a legal team at a mid-sized enterprise in Frankfurt in late 2026.
They have been using a third party AI model for content generation for eighteen months.
Their compliance officer just received a formal inquiry under new EU AI accountability frameworks asking them to demonstrate the provenance of every training dataset their AI vendor used.
the vendor's answer is a PDF with aggregate statistics and a confidentiality clause.
that answer used to be acceptable. it is not anymore.
this is the quiet environmental shift that most OPEN price analysis completely ignores. the conversation around OpenLedger stays focused on throughput, staking yields, token price relative to ATH.
those are real numbers. the 0.215 dollar price sitting 88.2% below the 1.82 all time high set September 8 2025 is a real data point.
the 62.58 million dollar market cap against a 214 million dollar FDV is a real gap. but none of those numbers capture what happens to demand for verifiable AI attribution infrastructure when regulatory enforcement actually arrives.
what the Story Protocol mechanic actually does
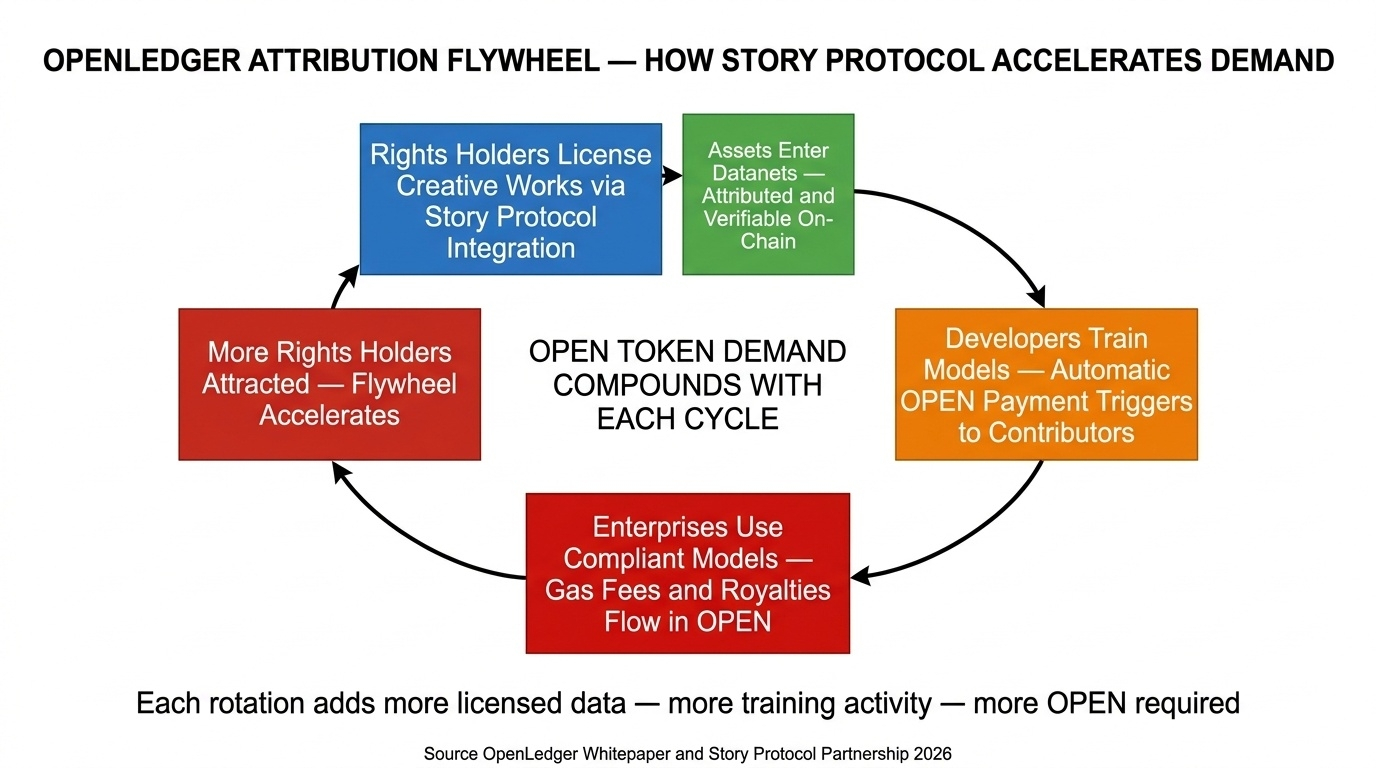
on January 30 2026 OpenLedger announced a partnership with Story Protocol establishing a new standard for legally licensing creative works for AI training with automatic payments to rights holders. most coverage treated this as a partnership announcement. i read it as an architecture decision with a compliance implication that compounds over time.
Here is the mechanic at its base level.
a developer wants to train a Specialized Language Model on a dataset that includes creative works writing , music, visual art, research papers.
previously thatdeveloperhad two options. use the data without permission and accept legal exposure.
OR negotiate individual licensing agreements with thousands of rights holders which is economically impossible at scale.
the Story Protocol integration creates a third option. license the entire dataset through OpenLedger's on-chain attribution layer. every rights holder whose work is included receives automatic $OPEN token payment through smart contract execution at the moment their data is accessed for training. the payment is not discretionary. it is not subject to platform pOlicy changes. it executes because the code says it executes. and the record of that payment the proof that attribution happened — is immutable on-chain. a compliance team can pull that record in seconds and present it to any regulatory body anywhere in the world.
that is not a feature competing with other features. that is infrastructure competing with legal exposure.
the tokenomics angle that connects to this directly
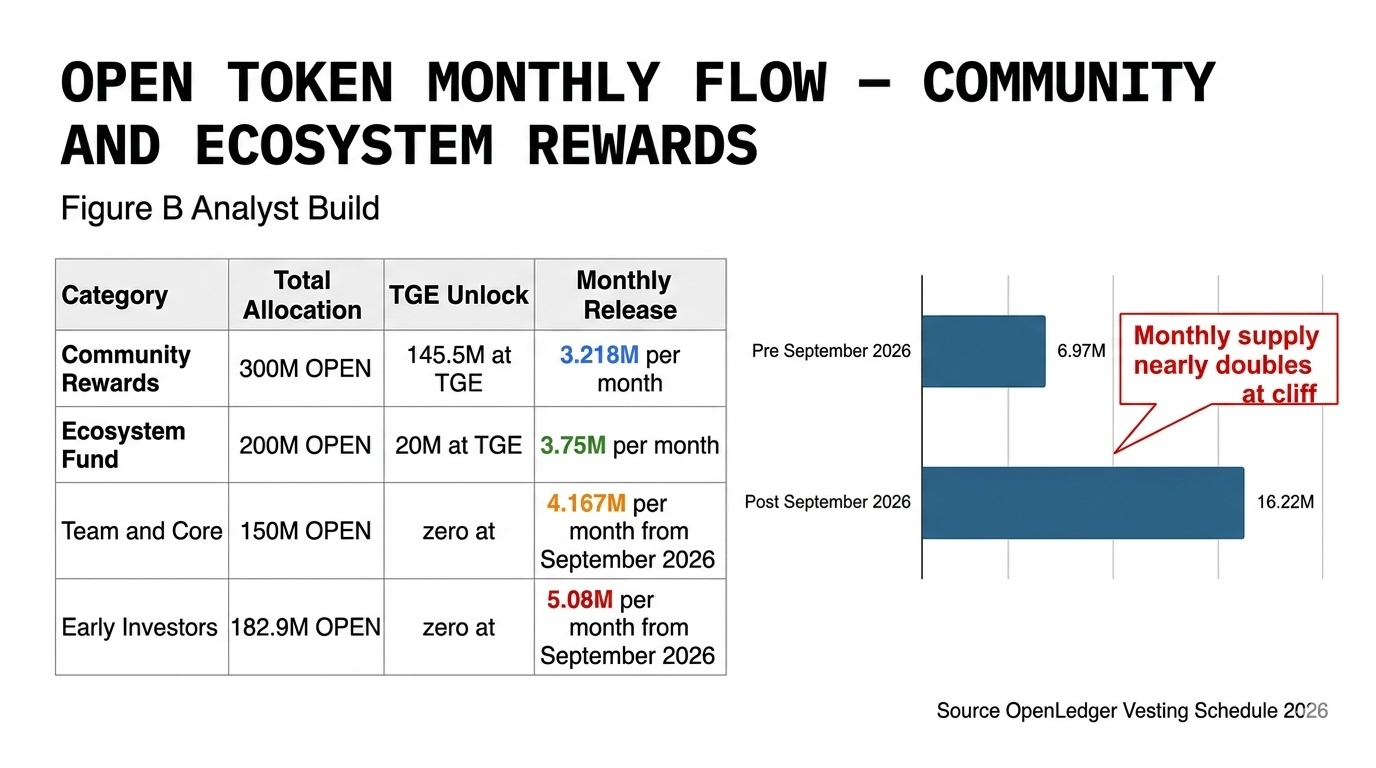
the community rewards allocation sits at 30% of total supply — 300 million OPEN tokens — the largest single categ0ry in the entire token table. 145.5 million of those tokens unlocked at TGE in August 2025 to bootstrap immediate participation. the remaining 154.5 million unlock linearly over 48 months at approximately 3.218 million OPEN per month.
those community rewards flow to data contributors, model trainers, node operators, and application developers. under the Story Protocol integration, rights holders who license their creative works for AI training become a new category of community reward recipient. every time a developer queries a model trained on licensed data, the attribution chain triggers reward distribution back through the Datanet layer to the original contributor.
this is the mechanic nobody is mod3ling in token demand forecasts. as the network attracts more rights holders licensing their data, more creative assets flow into Datanets. more assets in Datanets means more training activity. more training activity means more $OPEN used for gas fees, data access payments, and model royalties. the community rewards pool is not just an incentive mechanism. it is the fuel that makes the attribution flywheel accelerate.
the Ecosystem Fund at 2O% of supply 200 million OPEN — sits alongside this with 20 million unlocked at TGE and approximately 3.75 million per month releasing after that.
OpenCircle incubation grants funded from this pool are specifically targeting teams building Datanets and evaluation frameworks.
each new Datanet that launches through OpenCircle adds another layer of licensed attributable data to the network.
the ecosystem fund is essentially subsidizing the supply side of the attribution marketplace.
where the thesis gets stress tested
the 2 million OPeN Yapper Arena prize pool and the current 50,000 USDC Binance CreatorPad campaign represent mindshare investment before the deeper product layers are fully live. on-chain governance activation is still listed as in progress in the Phase 4 four roadmap. the agent economy launch — autonomous AI agents transacting on OpenLedger — is marked planned. cross-chain bridges remain planned.
these are not failed milestones. they are milestones that matter for the compliance thesis to fully mature. enterprise buyers d0not integrate infrastructure that lacks governance stability. Arisk committee evaluating whether to build their AI training pipeline on OpenLedger will ask about governance finality, bridgesecurity, and cross-chain accessibility before they ask about throughput numbers. every planned item on the roadmap that remains undelivered is a conversation that has not happened yet in those risk committee rooms.

the RSI reading of 74.88 as of late April 2026 signals the market may be temporarily overbought on short term momentum. the 200 day SMA projected to hit 0.1903 by late May suggests technical resistance in the near term. these are real signals that short term price does not cleanly reflect fundamental infrastructure development.
the deeper risk is timing. the Story Protocol partnership was announced January 30 2026.
mainnet launched November 18 2025. team and investor tokens cliff in September 2026 releasing 9.247 million OPEN per month for 36 months.
The compliance narrative needs enterprise adoption evidence before that supply event arrives or the market prices the unlock before the utility.
what the architecture genuinely gets right
the Proof of Attribution consensus mechanism is not a product feature that can be copied quickly.
it is built into the consensus layer meaning any competitor has to rebuild the chain not add a module. Polychain Capital and Borderless Capital backed the 8 million dollar seed round those are not firms that fund projects without technical due diligence on the core architecture. the Binance HODLer airdrop, the listings on Upbit, Bithumb, KuCoin, MEXC, and BingX, and the active CreatorPad campaign all represent distribution infrastructure that independently funded competitors cannot replicate cheaply.
OpenLoRA reducing inference costs by up to 99% is the economic argument that makes the compliance layer acc3ssible rather than exclusive. an enterprise that cannot afford to run large model inference can still build compliant AI pipelines on OpenLedger because the cost structure is fundamentally different from traditional deployment approaches.
honestly don't know if the regulatory tailwind arrives fast enough to absorb the September unlock or if enterprise adoption moves at its historically frustrating pace and the supply mechanics win the short term narrative 🤔
what's your take — compliance infrastructure becomes the dominant AI blockchain use case in 2026 or does the market keep treating OPEN as a speculative token until adoption metrics become impossible to ignore??