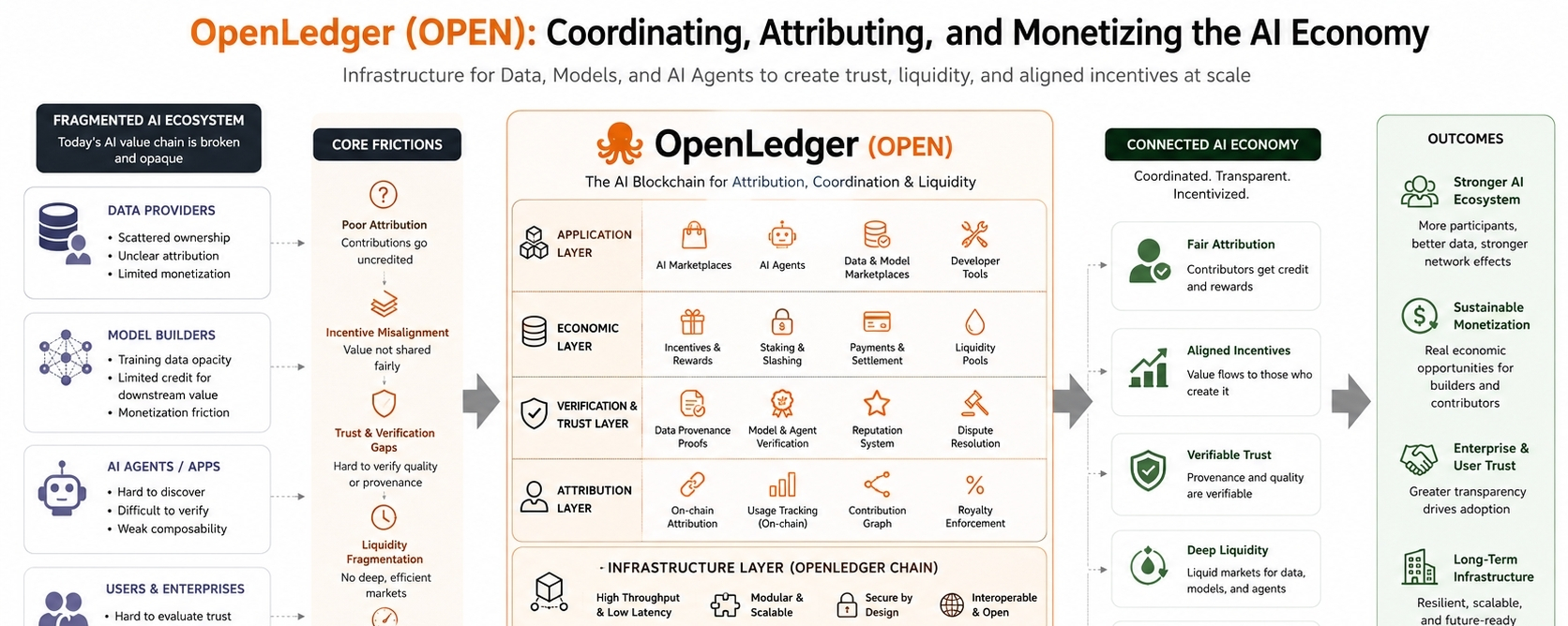

What makes OpenLedger interesting to me is that it treats AI less like magic and more like infrastructure. That sounds simple, but it changes the entire conversation.
A lot of AI discussion still revolves around intelligence itself — bigger models, smarter agents, faster outputs. But once you spend enough time watching these systems operate in the real world, another problem becomes impossible to ignore. Coordination starts breaking long before intelligence does.
The larger AI ecosystems become, the harder it gets to answer basic questions.
Who actually owns the data being used?
Who contributed value to a model?
Who gets paid when an AI agent produces something useful?
Who is responsible when outputs become unreliable?
In smaller systems, these questions stay hidden because one company controls everything internally. Data comes in through private pipelines, models are trained behind closed doors, and monetization happens inside a centralized platform. It works because authority is concentrated.
But once AI activity spreads across many independent participants, friction appears everywhere.
I’ve watched this happen in other systems too. Roads work fine until too many vehicles enter the network at once. Ports function smoothly until congestion builds. Electrical grids feel invisible until demand spikes during stress conditions. Infrastructure usually looks efficient when conditions are calm. Pressure is what exposes the weak points.
AI networks are starting to behave the same way.
You can already see how fragmented things are becoming. One group owns the data. Another trains the model. Another runs inference. Someone else builds agents on top. Then APIs, marketplaces, and external services get layered in between. Suddenly a single AI output may depend on dozens of invisible contributors.
That creates economic problems almost immediately.
If value moves through a system without clear attribution, trust slowly starts eroding. Data providers feel replaceable. Builders stop knowing whether their contributions are properly rewarded. Infrastructure operators optimize for extraction instead of reliability. Over time, coordination becomes harder because nobody fully understands how value is flowing underneath the surface.
This is the part OpenLedger seems focused on.
The project is trying to build infrastructure where datasets, models, and AI agents can interact inside a shared economic system with clearer attribution and coordination. The blockchain component matters less as ideology and more as a tracking layer. It creates persistent records around participation, usage, and transactions that would otherwise stay opaque.
That may sound technical, but the idea itself is pretty practical.
Imagine a city without accounting systems, property records, traffic management, or payment rails. Economic activity would still happen, but inefficiency and mistrust would grow quickly. OpenLedger feels like an attempt to build those coordination layers for decentralized AI ecosystems.
Because once AI becomes collaborative, somebody has to keep track of who contributed what.
Still, this is where I think realism matters.
Tracking activity is easier than verifying quality.
A blockchain can record that someone contributed data. It cannot automatically determine whether that data is accurate, useful, manipulated, duplicated, or intentionally misleading. The same applies to models and agents. Transparency helps, but transparency alone does not solve trust.
And honestly, incentives complicate things even further.
The moment datasets, models, or AI agents become monetized, behavior changes. People start optimizing around rewards. Some contributors genuinely improve the ecosystem. Others learn how to game measurement systems. That is not unique to crypto or AI. It happens in almost every economic network.
I’ve seen this pattern repeatedly online. Once incentives become visible, participants adapt around them very quickly.
That means OpenLedger’s long term challenge is not just scaling infrastructure. It is maintaining credibility inside an environment where participants may have very different motivations.
That becomes especially difficult in decentralized systems because no single authority fully controls enforcement. Governance slows things down. Verification becomes expensive. Disputes become harder to resolve cleanly. Even honest coordination takes time.
There is also the issue of dependency.
Open AI ecosystems rely heavily on external contributors continuing to participate productively. If high quality datasets stop entering the network, models degrade. If infrastructure operators lose incentives, reliability weakens. If liquidity dries up, economic activity slows. Open systems are resilient in some ways, but fragile in others.
That tradeoff is important.
Centralized AI systems move fast because decisions happen internally. Open systems distribute power more broadly, but they also distribute complexity. Every additional participant introduces another layer of coordination overhead.
Sometimes people frame decentralization as if it automatically removes trust problems. I don’t think reality works that way. Decentralization changes where trust sits. It does not eliminate the need for trust entirely.
Participants still need confidence that attribution is fair, governance is stable, incentives are aligned, and verification systems are functioning properly. If those layers weaken, the network becomes noisy very quickly.
What I find interesting about OpenLedger is that it seems to recognize this operational side of AI rather than only focusing on model capability. The project feels less concerned with abstract intelligence narratives and more concerned with how economic coordination around AI actually behaves under pressure.
Because eventually pressure arrives.
As more agents interact with each other, latency matters. As more datasets become monetized, provenance matters. As more value flows through AI systems, liquidity and verification start becoming infrastructure requirements rather than optional features.
That is why I tend to think about projects like OpenLedger more like utility networks than software applications.
Nobody thinks much about plumbing when it works. But once cities scale, plumbing becomes one of the most important systems underneath daily life. AI coordination infrastructure may evolve the same way. Most people will never care about attribution layers or coordination protocols directly, but those systems quietly determine whether large ecosystems remain functional or drift into mistrust and fragmentation.
Of course, OpenLedger cannot fully solve all of this.
No infrastructure layer can completely fix poor data quality, manipulation risks, governance friction, or human incentive problems. Some centralization pressures will probably reappear naturally over time because scale and reliability tend to concentrate influence. Verification inside AI systems will remain difficult because contribution chains are messy and interconnected.
But I think the more grounded way to view OpenLedger is not as a perfect solution. It is an attempt to reduce friction inside growing AI economies before coordination failures become too expensive to ignore.
And honestly, that may end up being one of the more important infrastructure problems AI faces over the next few years.