

A model gives an answer, and everyone looks at the answer.
Almost nobody looks at the trail behind it.
Behind one clean AI response, there may be thousands of invisible pieces of work. Someone wrote a useful code fix years ago. Someone labeled a dataset. Someone explained a difficult concept in a forum. Someone cleaned messy information until it became usable. Someone trained, corrected, tested, or improved a model until it stopped making obvious mistakes.
Then the model speaks.
And most of those people disappear from the story.
That is the space OpenLedger is trying to enter. Not with the usual loud promise that blockchain will fix everything, but with a more specific question: what if AI had to remember where its value came from?
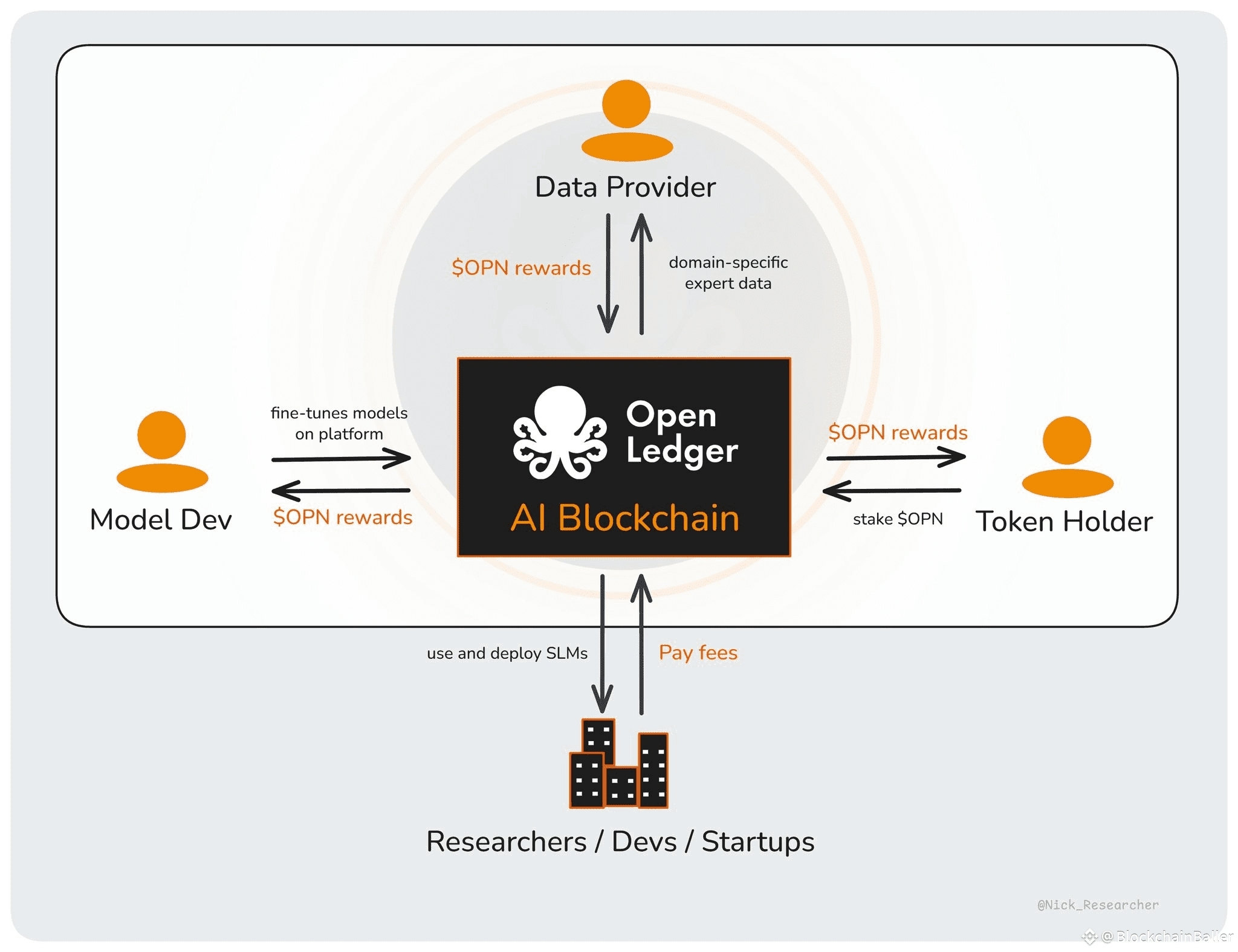
OpenLedger, also known by its token name OPEN, is building an AI-focused blockchain designed to help people monetize data, models, and agents. The idea is simple on the surface. If data helps train a model, and that model later creates value, the people behind that data should have a path to earn from it. If a model is useful, its creator should be able to track and monetize its usage. If an AI agent performs work, the system should know what powered it and how rewards should move.
That may sound obvious, but it is not how most of AI works right now.
Most AI systems are built on huge amounts of information gathered from many places. Some of it comes from public knowledge. Some comes from communities. Some comes from experts. Some comes from users who never imagined their words, examples, reviews, corrections, or documents could become part of a commercial machine. The final product becomes valuable, but the original sources are often blurred beyond recognition.
OpenLedger is trying to make that blur less convenient.
Its main idea is called Proof of Attribution. In plain words, this means the system tries to track which data, models, or contributors helped produce useful AI output. Once that contribution is visible, rewards can be shared more fairly.
This is where OpenLedger becomes more interesting than a normal AI token project. It is not only asking people to buy into a network. It is trying to build a payment system around contribution.
Imagine a group of smart contract auditors creating a dataset of real exploit patterns. That dataset could train a security model. The model could help developers catch vulnerabilities before launch. If companies pay to use that model, the people who helped build the dataset should not just be forgotten. OpenLedger’s system is designed to keep them connected to the value their work helped create.
The same idea could apply to trading data, healthcare knowledge, DePIN networks, research databases, coding assistants, legal tools, or highly specific business agents. The key is specialization.
That is one of OpenLedger’s strongest bets. The future of AI may not belong only to massive general models that try to answer everything. Those models are impressive, but they are not always deep enough for serious work. A general chatbot can explain a smart contract, but a model trained on thousands of real exploit cases may be better at spotting danger. A general AI can talk about markets, but a specialized agent trained on wallet behavior, liquidity movements, and liquidation patterns may give sharper insight.
OpenLedger seems to believe that AI will split into many smaller, more focused systems. Some will be built for finance. Some for security. Some for medicine. Some for code. Some for research. Some for enterprise workflows. These models will need good data, clear ownership, reliable payments, and trust.
That is where Datanets come in.
A Datanet is basically a community-owned data network built around a specific subject. Instead of one company quietly collecting data and locking it away, OpenLedger allows communities to build datasets together. People can contribute, improve, and organize data. That data can then be used to train specialized models. If those models earn, contributors can be rewarded.
This changes the role of data.
Normally, data is treated like raw material. It gets collected, cleaned, used, and forgotten. OpenLedger treats it more like an asset. Something with history. Something with ownership. Something that can keep producing value after it is used.
That is what “unlocking liquidity” really means here.
A dataset sitting on someone’s laptop has no market.
A useful fine-tuned model shared in a small group has limited reach.
An AI agent built by one developer may create value, but monetization can be messy.
Expert knowledge scattered across documents and examples is hard to price.
OpenLedger wants to turn these things into live economic assets.
The OPEN token is part of that system. It can be used for network activity, payments, fees, incentives, governance, and rewards. In theory, users pay to access models or agents, developers earn from what they build, and contributors receive rewards based on how useful their data becomes.
That is the attractive version.
The difficult version is where the real test begins.
Because paying people for data sounds fair until you ask a harder question: who decides what data is actually good?
A person can upload a huge amount of useless information. A dataset can look impressive and still produce weak models. A reward system can be gamed. People may try to farm tokens instead of contributing real value. And attribution itself is not easy. AI models do not work like simple machines where every output can be traced neatly to one input. They learn patterns across enormous amounts of information.
So OpenLedger’s biggest challenge is not creating a marketplace. Crypto already knows how to create marketplaces. Its real challenge is creating trust.
Trust that the data is useful.
Trust that the model performs well.
Trust that contributors are rewarded fairly.
Trust that the system cannot be easily manipulated.
Trust that the on-chain record represents real value, not just activity.
That last point matters a lot. A bad dataset on a blockchain is still a bad dataset. A weak model with transparent history is still weak. A project can show transactions, uploads, and rewards, but those numbers do not mean much unless people are actually using the models because they solve real problems.
This is where OpenLedger has to prove itself.
The idea is strong because the problem is real. AI has created a new kind of supply chain. In old software, it was easier to see who built what. A developer wrote code. A company sold the product. A customer used it. With AI, the chain is harder to see. A final answer may depend on training data, fine-tuning, user feedback, model adapters, infrastructure, and agents built by different people.
OpenLedger wants to give that supply chain a memory.
That could become especially important as AI agents become more common. A chatbot mostly answers. An agent acts. It can monitor markets, write reports, search databases, test code, manage workflows, compare documents, and make decisions inside software systems.
Once agents start creating real economic value, the payment question becomes more serious.
Suppose an AI agent helps a trader detect a market opportunity. That agent may rely on a specialized model. The model may rely on a Datanet. The Datanet may include contributions from hundreds of people. So who gets paid? Only the developer who built the agent? The person who trained the model? The data contributors? The infrastructure network?
OpenLedger’s answer is that the whole chain should be visible enough for value to move through it.
That is ambitious. It is also messy.
But messy does not mean useless. Most important infrastructure begins messy. Payments were messy. Cloud computing was messy. Open-source funding is still messy. AI attribution may be even harder, but the need for it is growing.
The internet trained people to give away pieces of themselves constantly. Posts, reviews, images, notes, code, opinions, examples, corrections, behavior — all of it became raw material. AI made that raw material more valuable. But the people behind it often stayed outside the reward system.
OpenLedger is trying to change that pattern.
It may find its first real users in Web3 because crypto communities already understand wallets, tokens, incentives, and public contribution. A Solidity security dataset makes more immediate sense than a heavily regulated medical dataset. A trading intelligence agent is easier to launch than a clinical AI system. That is probably where OpenLedger can prove the model first: in areas where specialized data is valuable, users are crypto-native, and payments can happen on-chain without too much friction.
From there, the bigger question is whether this system can move beyond crypto circles.
For that to happen, OpenLedger will need more than a token. It will need strong tools, simple developer experiences, serious data validation, and models that people actually want to use. It will need to show that attribution-based rewards are not just good marketing, but a working economic system.
Because the promise is not small.
If OpenLedger works, a person who contributes useful data does not disappear. A developer who builds a strong model has a clearer way to earn. A community that creates knowledge can turn that knowledge into an asset. An AI agent can carry a record of what powered it. The whole system becomes less like a black box and more like a living marketplace for intelligence.
That is the best version of OpenLedger.
Not a magic solution. Not a guaranteed winner. Not another shiny AI coin with a big slogan.
A serious attempt to answer one of AI’s most uncomfortable questions: when machines create value from human knowledge, should the humans remain invisible?
OpenLedger’s real bet is that the answer will eventually be no.
AI has already learned how to speak with borrowed memory. The next fight is over whether that memory has owners, whether those owners can be recognized, and whether recognition can become payment.
The smartest model may not be the one that knows everything.
