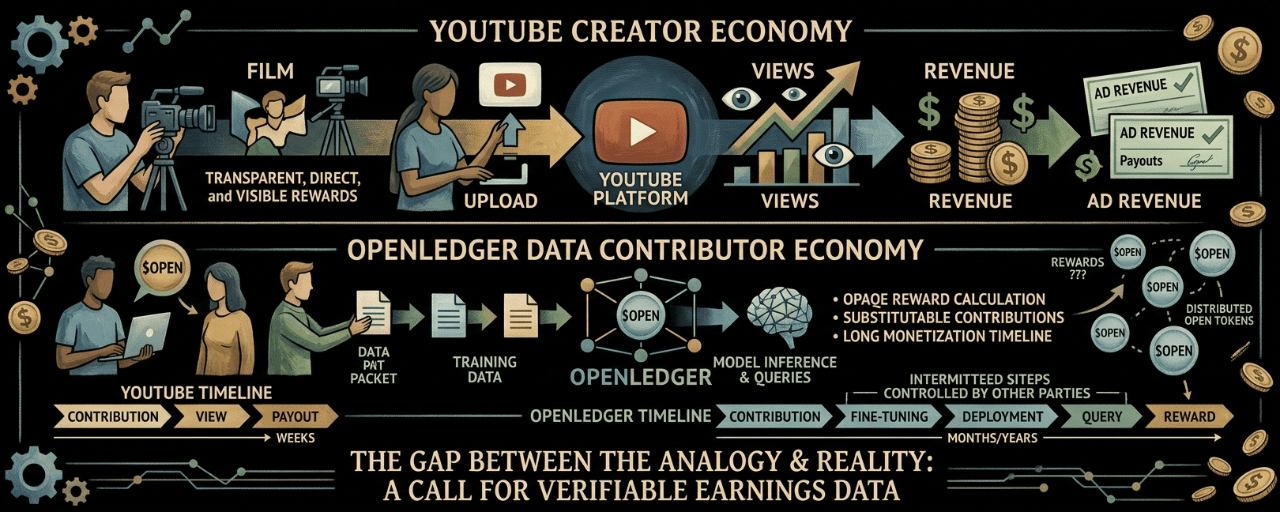
The YouTube creator economy comparison is the most effective narrative frame OpenLedger uses, and I've heard it in community discussions, ecosystem pitches, and casual crypto conversations more times than I can count. The pitch goes like this: just as YouTube built an economy where creators contribute content and earn revenue proportional to how many times that content is viewed, OpenLedger is building an economy where data contributors contribute training data and earn OPEN proportional to how many times models trained on that data are queried. It's a clean, intuitive analogy. It's immediately legible to non-technical audiences. And it breaks in three specific places that matter enough to name directly, because understanding where it breaks tells you more about OpenLedger's actual challenges than the analogy itself tells you about the opportunity.
The first place it breaks is transparency. YouTube's creator payout rates are imperfect but public enough to be broadly understood. Creators know approximately how much CPM their channel commands, which geographies pay better, how many views translate into what dollar range of revenue. OpenLedger's contributor reward rates are not public. The OPEN rewards a contributor earns for having their data queried during model inference have not been documented with any specific rates, example calculations, or real payout histories. A YouTube creator deciding whether to invest time in content creation can run a rough calculation based on publicly known averages. An OpenLedger data contributor deciding whether to upload their specialized dataset has no equivalent calculation available. The opacity is not intentional deception. The reward calculation depends on complex factors including contributor influence scores, total query volume, and the pool of eligible contributors per model. But complexity is not the same as transparency, and the analogy promises a legibility that the current system doesn't deliver.
The second break is content replaceability. YouTube's creator economy works in part because human attention is scarce and audience relationships with specific creators are personal and not easily substituted. If a viewer likes a particular cooking channel, they're not easily replaced by any other cooking channel. The preference is specific. This stickiness creates long-term creator value that justifies sustained contribution. OpenLedger's data contributor economy faces a different dynamic. Most training data, even specialized training data, has some degree of substitutability. A clinical dataset from one hospital may be substitutable with a clinical dataset from another hospital if both cover the same diagnostic categories with similar annotation quality. This means data contributors on OpenLedger are in a more directly competitive position with each other than YouTube creators typically are, and competition among contributors for the same model's reward distribution reduces individual earnings.
The third break is the monetization timeline. YouTube creators can monetize relatively quickly once they reach certain threshold metrics, and the feedback loop between content performance and earnings is fast enough to be motivating. A creator can post a video on Monday and see revenue data by the following week. OpenLedger's data contribution timeline is fundamentally different. A contributor uploads a dataset today. A model builder decides, sometime in the future, to fine-tune on that dataset. The model gets deployed through OpenLoRA. Enterprise or API users begin querying the model. Only then does the contributor begin receiving inference-linked rewards. That timeline could be months or years from the initial contribution, and it depends on decisions made by parties other than the contributor at each step. The passive income narrative is architecturally accurate. The timeline implied by "passive income" in the YouTube creator analogy sense is significantly more compressed than what OpenLedger's actual economic cycle produces.
None of these breaks means the OpenLedger economic model is broken. They mean the YouTube analogy is a useful starting point that oversimplifies in ways that matter for contributors and investors trying to model their expected experience. OpenLedger's actual value proposition is probably better articulated as a long-horizon data rights infrastructure play. Contribute your specialized knowledge today, establish on-chain provenance for your contribution, and participate in an economy where your contribution's value is recognized and compensated as AI deployment scales. That's a real and important vision. It's just less immediately gratifying than "earn passive income like a YouTuber" implies.
What OpenLedger would need to do to close the gap between the analogy and the reality is publish real contributor earnings data. Not projections. Not architectural descriptions of how rewards flow. Actual, on-chain verifiable numbers showing what specific contributors earned during specific periods, what query volumes drove those earnings, and what the dollar-denominated value of those earnings was at payout time. That data would either validate the YouTube creator analogy at meaningful scale or it would force a more honest conversation about what the OpenLedger contributor economy actually delivers in its current state. The absence of that data is the gap the analogy papers over most effectively, and it's the gap that matters most for anyone deciding whether to contribute their valuable specialized data to OpenLedger's Datanets.
