I’ll be honest I didn’t expect OpenLedger to hold my attention for very long.
At this point, I’ve read through enough AI and blockchain projects to recognize the usual pattern almost immediately. Big language about infrastructure, decentralized intelligence, autonomous systems, machine learning economies. Then you look closer and realize most of it still depends on the same fragile structure underneath: centralized data, disconnected tooling, unclear incentives, and users doing half the coordination work themselves.
That’s probably why I approached OpenLedger with a bit of skepticism at first. The phrase “AI blockchain” sounds ambitious on paper, but it also feels like the kind of branding that gets repeated so often that it loses meaning. I’ve seen too many projects promise seamless AI integration while the actual product feels stitched together from separate systems that barely communicate properly.
But after spending more time digging into how OpenLedger is structured, especially around Datanets and on chain AI operations, I started paying closer attention. Not because it suddenly looked perfect, but because the project seems to be solving problems that actually exist instead of inventing narratives around them.
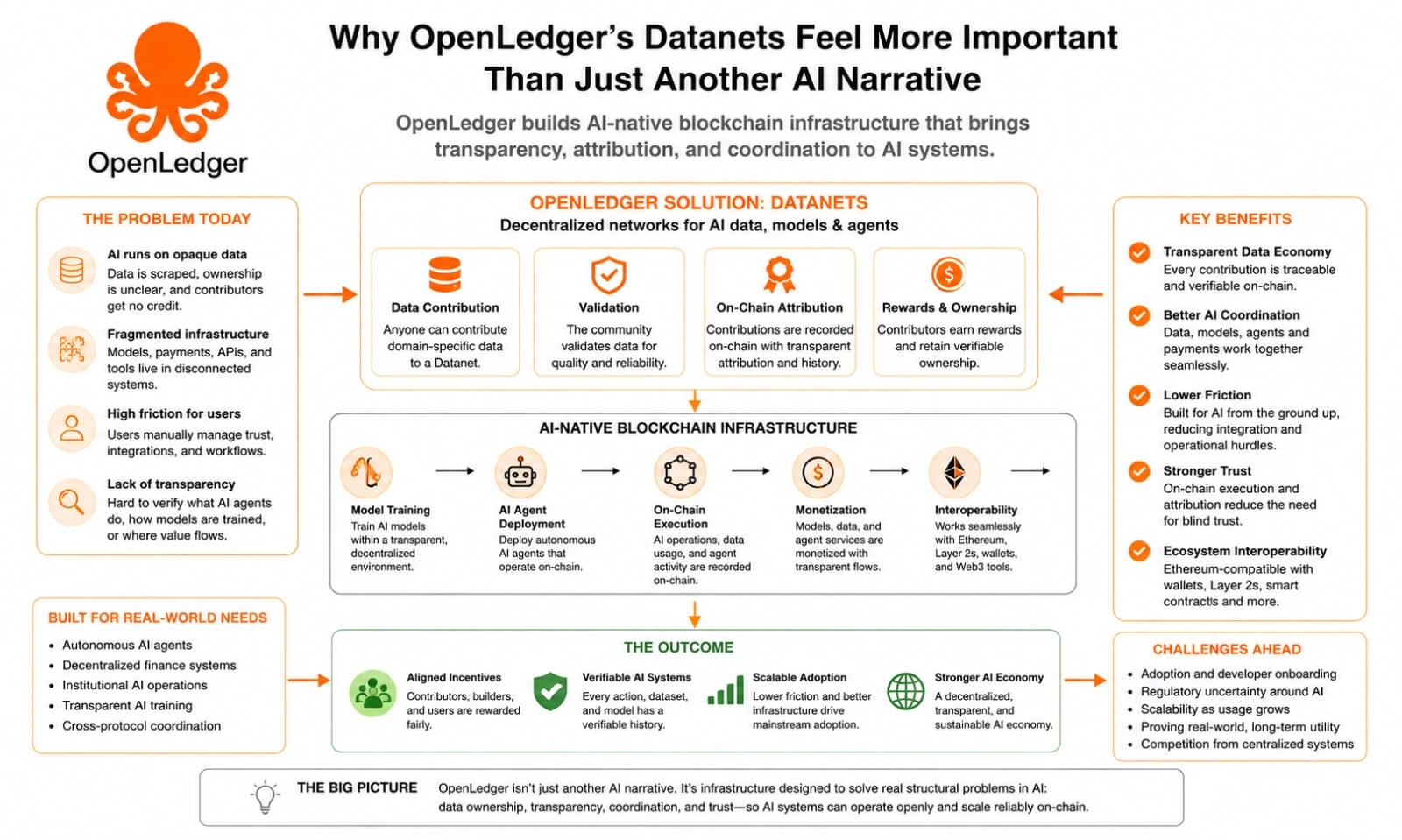
One thing I think people underestimate in AI discussions is how messy the data layer really is. Everyone focuses on the output side smarter models, AI agents, automation but very few talk seriously about where the underlying data comes from, how it’s validated, who owns it, or who gets rewarded for contributing it. In most systems, that process is still surprisingly opaque.
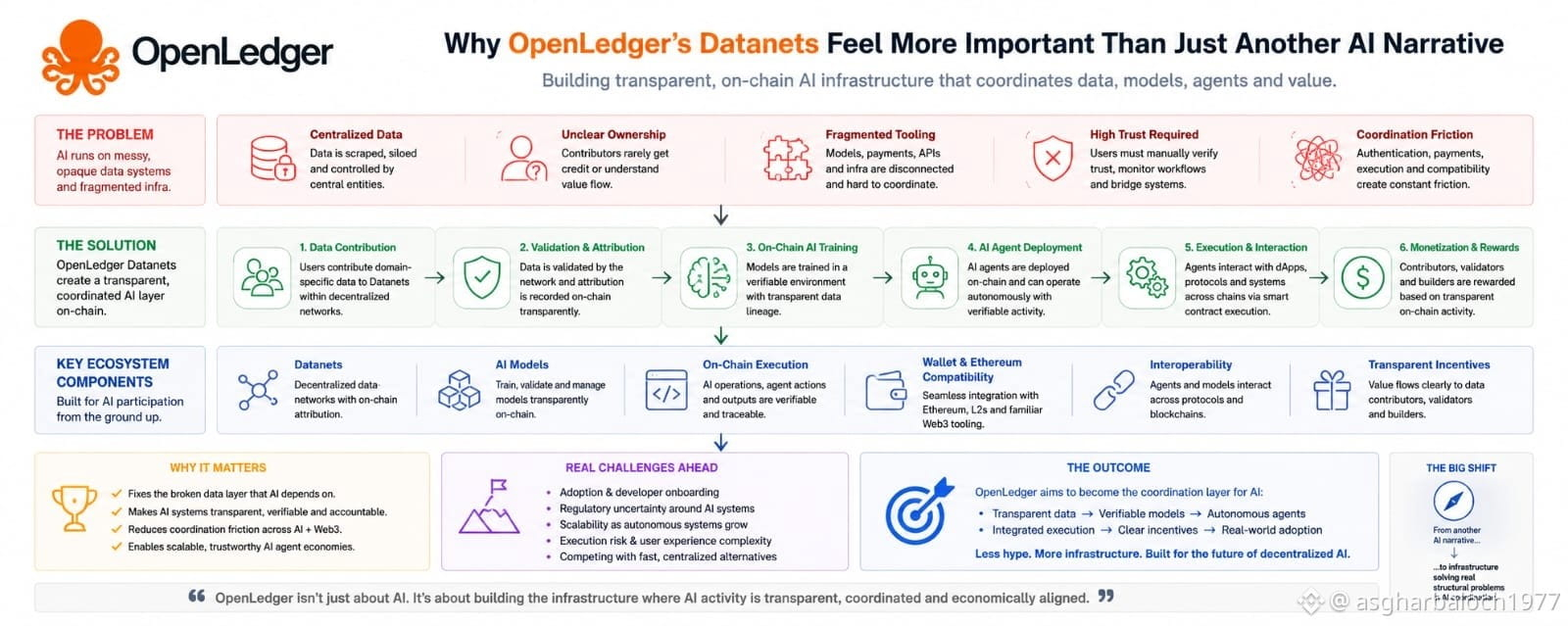
OpenLedger’s idea of Datanets feels important because it directly addresses that missing layer. Instead of treating data as something hidden inside private systems, Datanets create decentralized networks where contributors can provide, validate, and organize domain specific datasets for AI training. And because attribution happens on-chain, there’s at least an attempt to make contribution history transparent instead of invisible.
That may sound like a small detail, but I honestly don’t think it is.
Right now, a huge part of the AI economy runs on unclear ownership structures. Data gets scraped, models get trained, platforms monetize outputs, and contributors rarely understand where value actually flows. OpenLedger seems to be trying to restructure that relationship by making datasets, models, and AI activity part of a verifiable blockchain environment instead of isolated backend infrastructure.
The more I thought about it, the more I realized this is less about AI hype and more about coordination.
A lot of current AI tooling feels fragmented. You might have models running in one environment, payments somewhere else, APIs sitting behind centralized gateways, and wallet connectivity treated as an afterthought. Even when projects claim to be decentralized, there’s often a surprising amount of trust still required between users, developers, platforms, and infrastructure providers.
What caught my attention with OpenLedger is that the system appears designed specifically for AI participation from the start, not retrofitted later. The blockchain infrastructure itself is built around AI operations model training, agent deployment, data contribution, execution, and monetization happening directly on-chain instead of across disconnected services.
And honestly, that matters more than flashy demos to me.
When people talk about autonomous AI agents, the conversation usually stays abstract. But operationally, deploying AI systems across fragmented environments becomes difficult very quickly. You run into authentication issues, payment coordination, execution verification, compatibility problems between chains, and constant uncertainty around whether systems are behaving the way they claim to.
OpenLedger’s approach seems to reduce some of that friction by embedding execution directly into the infrastructure layer itself. AI models can be trained within a transparent system. Agents can operate on-chain with verifiable activity. Data attribution becomes traceable instead of hidden. Wallet integration and Ethereum compatibility make interaction easier without forcing users into completely isolated ecosystems.
That last part actually matters a lot more than people think.
I’ve noticed many blockchain projects unintentionally create closed environments that require users to abandon familiar tooling just to participate. OpenLedger going in the Ethereum-compatible direction feels practical because it lowers the barrier between AI infrastructure and existing Web3 ecosystems. Wallets, Layer 2 systems, smart contracts those integrations sound technical on paper, but in practice they reduce operational friction for developers and users trying to coordinate real activity.
And friction is usually where adoption quietly fails.
The more I explored OpenLedger, the less it felt like a project obsessed with narratives and the more it felt like infrastructure trying to make execution smoother. That difference is subtle, but important. A lot of blockchain systems still leave coordination problems entirely to the user. You’re expected to manually verify trust, manage integrations, monitor workflows, and bridge disconnected services yourself.
OpenLedger seems more focused on embedding coordination directly into the environment where the AI activity happens.
That doesn’t automatically guarantee success, obviously.
I still think there are real challenges ahead, and pretending otherwise would feel dishonest. Infrastructure alone cannot solve every problem surrounding decentralized AI. Adoption is still difficult. Regulatory pressure around AI systems is evolving constantly. Scalability becomes a serious issue once autonomous systems begin interacting at higher volume. And decentralized coordination sounds cleaner in theory than it often feels in practice.
There’s also the question of whether developers and institutions will genuinely move meaningful AI operations on-chain or continue relying on centralized systems because they’re simpler and faster in the short term. A lot of projects underestimate how resistant existing infrastructure can be to change, especially when businesses already operate within familiar cloud environments.
And then there’s the execution risk itself.
Building AI-native blockchain infrastructure is one thing. Getting developers to consistently build useful systems on top of it is another challenge entirely. If the user experience becomes complicated, if integrations break down, or if AI workflows feel slower than centralized alternatives, adoption friction appears very quickly.
So I’m not looking at OpenLedger as some guaranteed outcome. I see it more as an infrastructure experiment that happens to be tackling problems I already think exist.
Because realistically, there is a growing need for environments where AI systems can coordinate transparently across decentralized networks without relying entirely on centralized intermediaries. That matters more in institutional environments, automated financial systems, decentralized agent economies, and applications where verification actually matters.
In those situations, transparency is not just a philosophical feature. It becomes operationally important.
If an autonomous AI agent is interacting with liquidity systems, executing transactions, coordinating across protocols, or training models using community provided datasets, people eventually need visibility into what’s happening underneath. They need attribution, traceability, execution history, and interoperability that works across existing blockchain infrastructure instead of isolated ecosystems.
That’s where OpenLedger starts making more sense to me.
Not as a futuristic AI fantasy, but as infrastructure attempting to organize AI activity in a way that’s actually observable and economically coordinated.
I’m still approaching it carefully though. I’ve learned over time that the real test for infrastructure projects is never branding. It’s usability. It’s whether systems continue functioning smoothly once real participants begin interacting at scale.
So when I look at OpenLedger now, I’m less interested in announcements and more interested in behavior. I want to see how the ecosystem handles integrations, whether AI workflows actually operate smoothly on-chain, how agents behave under real conditions, and whether developers can build without constantly fighting the infrastructure itself.
That’s usually where strong ideas separate from durable systems.
And to be fair, meaningful adoption rarely arrives with dramatic moments anyway. Most important infrastructure becomes valuable quietly. People start using it because it removes friction, simplifies coordination, or makes existing processes work better than before.
That’s probably the biggest shift in perspective I had while looking deeper into OpenLedger.
At first, I thought it was another AI narrative attached to blockchain language because that’s what the industry has trained people to expect. But after spending time understanding how the system approaches data ownership, on chain execution, agent deployment, and AI coordination, it started feeling less like marketing and more like an attempt to solve structural problems that AI systems are eventually going to face anyway.
Whether OpenLedger fully succeeds or not is still an open question. But I do think the direction itself makes sense. And right now, that already puts it ahead of a lot of projects that still seem more focused on attention than actual infrastructure.