I used to think AI licensing would become a cleaner version of what we already know. A company owns data, another company wants to use it, both sides agree on terms, and somewhere in the middle there is a contract, an API key, a payment layer, or maybe an on-chain record showing who has permission to access what. That version felt simple enough to understand. Not simple to execute, but at least simple as an idea. But the more I think about OpenLedger, the more that old picture feels incomplete. AI does not treat data like a normal product sitting in one place. It absorbs it, reshapes it, mixes it with other signals, and sometimes creates value much later in ways that are difficult to trace back cleanly. So maybe the real future of AI licensing is not just about who gives permission once. Maybe it is about how different machine systems keep negotiating claims as value moves through the network.
That is the part that makes OpenLedger interesting to me. It does not feel like this is only about access. Access is the easy story. Can this model use this dataset? Can this agent call this resource? Can this application train on this content? Those sound like yes-or-no questions, but real AI systems do not behave in yes-or-no ways. A dataset can influence a model without showing up directly in the output. A model can use retrieved context for one task, then create something that becomes commercially useful somewhere else. An agent can call a tool, reuse information, chain it with other inputs, and produce a result where the original source still mattered, but not in a way that is easy to measure. Once that happens, the real issue is not permission anymore. The real issue is uncertainty. Who contributed value? How much did they contribute? Was the usage temporary or ongoing? Does the original data provider deserve a one-time payment, recurring compensation, attribution, revenue share, or nothing at all?
This is where normal ownership language starts to feel weak. Ownership works best when the object is clear. A song, a file, a database, a piece of content, a license agreement. But AI turns clean objects into blurred influence. Data becomes training signal. Training signal becomes model behavior. Model behavior becomes an output. That output becomes a product feature, a business decision, a recommendation, or even another input for another system. Somewhere in that chain, economic value appears, but it is not always obvious where the value started or who should have standing to make a claim. That is why attribution alone may not be enough. People talk about attribution as if every source can eventually be traced with perfect accuracy, but maybe that is not how this market will actually work. Maybe the practical solution is not perfect truth. Maybe it is creating enough shared evidence for machines and markets to negotiate around imperfect truth.
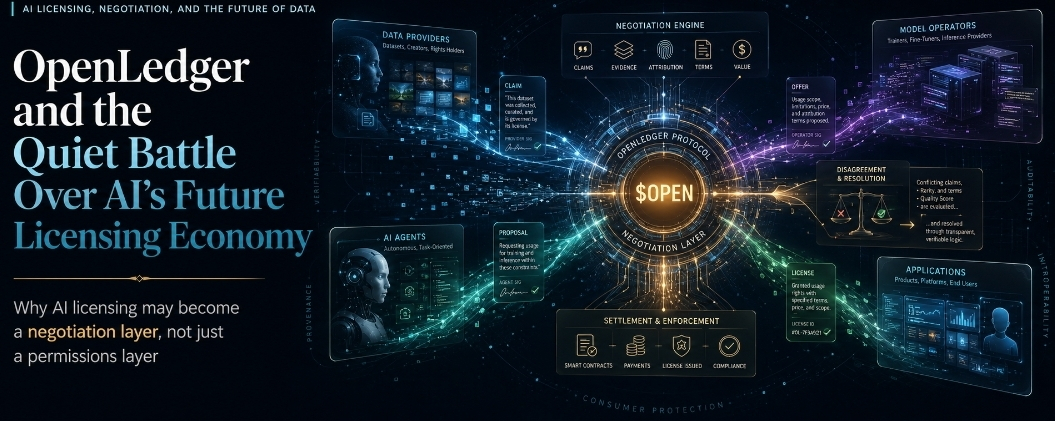
That is the idea I keep coming back to with OpenLedger. Maybe it is less about building a beautiful ownership layer and more about building a negotiation layer. A place where claims about data usage, contribution, access, influence, and compensation become structured enough to be recognized. Not perfectly proven. Not morally complete. Just legible enough to work with. Because markets usually do not require everyone to agree on the full truth. They require a shared format where disagreement can be priced. Buyers and sellers disagree, so exchanges exist. Traders do not fully trust each other, so clearing systems exist. Trade creates friction, so ports and settlement networks become valuable. AI licensing may develop the same shape. Not because the legal language gets prettier, but because machine economies will produce too many unclear usage events for humans to manually review every time.
In that kind of world, $OPEN starts to look different. It may not simply be a token connected to AI data access in the obvious way. It could become part of the coordination layer around unresolved licensing ambiguity. That is a much stranger demand model than “AI grows, token grows.” The more interesting version is that demand comes from disagreement density. The more agents, model builders, data providers, inference networks, and applications interact, the more unclear claims appear. Someone says their data mattered. Someone else says the impact cannot be isolated. One system wants temporary access. Another wants conditional compensation if outputs keep creating value. Another wants proof before paying. Another wants access to continue only if certain restrictions are respected. These are not simple transactions. They are ongoing negotiations around uncertain value.
And that is why the negotiation layer may become more important than people expect. The dataset matters, of course, but the real economic pressure may build around the surface where claims are made, checked, challenged, priced, and settled. That sounds backward at first, but it is not. The world often rewards the infrastructure around friction. Exchanges are not valuable because disagreement disappears there. They are valuable because disagreement becomes usable there. If OpenLedger can create a system where AI-related licensing disputes do not freeze activity but become structured enough to move, then it may be building something much bigger than a data coordination tool. It may be building a market interface for machine uncertainty.
The uncomfortable part is that whoever defines the interface also shapes the reality that gets recognized. This is where infrastructure quietly becomes governance. If a protocol decides what kind of evidence counts, then it also decides what kind of contribution can be ignored. A claim that fits the schema can be seen, scored, priced, challenged, or settled. A claim that does not fit may become economically invisible, even if it mattered in reality. A creator may have influenced a model but fail to leave the right kind of proof. A dataset may have shaped behavior but not in a way the system can capture. A licensing claim may be valid in human terms but useless in machine terms because it never became formatted evidence. That is a powerful and slightly unsettling thing. The system does not judge everything that happened. It judges what survived being made visible.
That may be the hidden power in this whole discussion. OpenLedger might not just be helping AI systems access data. It may be helping decide which version of AI’s messy data economy becomes readable enough to negotiate. And once machines start treating protocol-visible evidence as the usable version of reality, absence becomes powerful. Not because something was disproven, but because it was never seen. That is where the stakes become bigger than simple licensing. The future may not be about proving every contribution with perfect certainty. It may be about deciding which claims become visible enough to matter economically.
So when I look at OpenLedger, I do not see only a data ownership story anymore. I see a possible settlement layer for a future where AI systems constantly run into blurry rights, delayed value, unclear attribution, and competing claims. A future where licensing is not a one-time agreement but an ongoing negotiation between machines, data providers, model operators, and applications. In that future, the most valuable infrastructure may not be the place where data simply sits. It may be the place where uncertainty becomes structured enough for the system to keep moving. And maybe that is the real reason OpenLedger feels worth watching. Not because it solves the mess completely, but because it may be building the layer where the mess becomes tradable.
