@OpenLedger $OPEN #OpenLedger
I've been sitting with this for weeks and I still can't fully shake it.
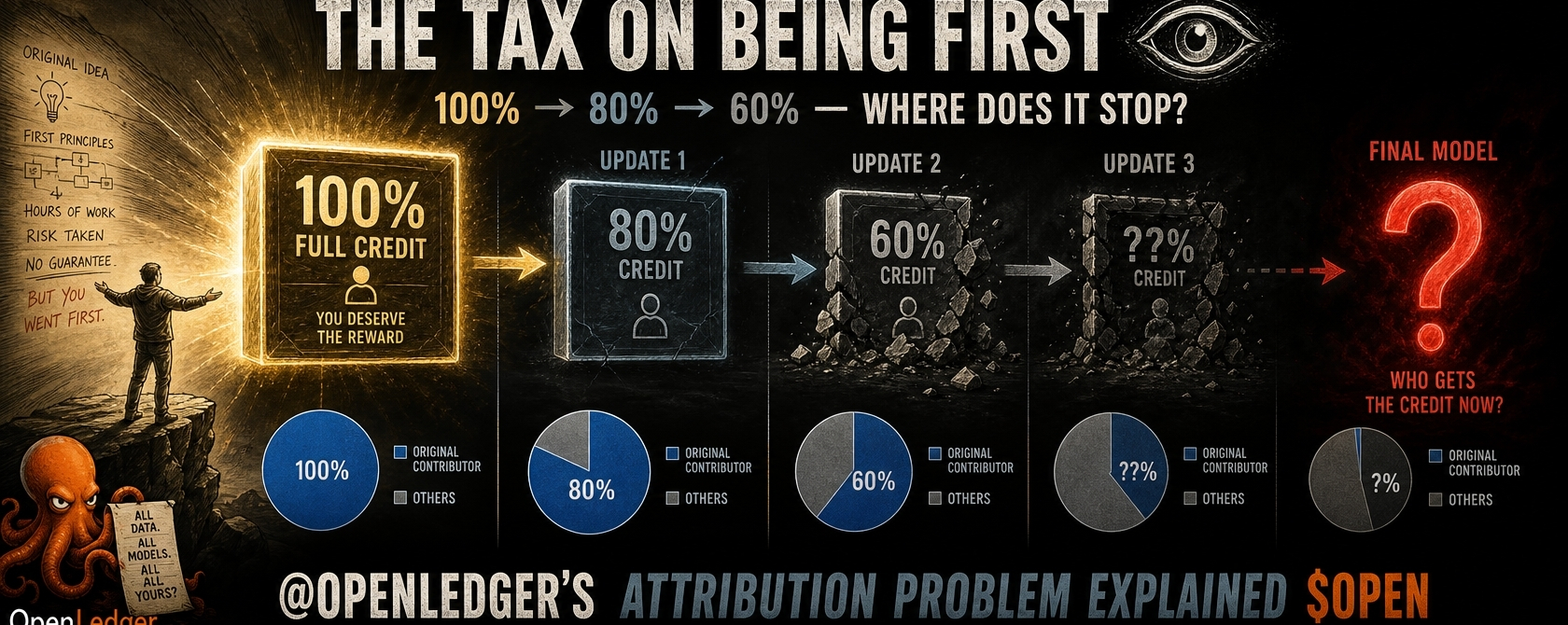
January 2026. @OpenLedger updated its Proof of Attribution system to keep data-output links intact as AI models get fine-tuned over time. On paper, straightforward progress. The kind of infrastructure fix that actually matters.
But the more I thought about the mechanics underneath it, the more uncomfortable I got.
Here's the specific thing bothering me.
Attribution works by tracing which training data shaped which model output. Contributor A's data moves the model in a measurable direction. Inference happens. Attribution calculates. Reward flows back. Clean loop — when the model stays static.
Models don't stay static.
They get fine-tuned. Updated. Layered. Each cycle shifts behavior incrementally away from what the original training data produced. So what actually happens to Contributor A's attribution score after the model has been fine-tuned three times by contributors B, C, and D?
The January update says the links are "maintained." But maintained how, exactly.
If the model has drifted 40% from its original training distribution through successive updates, is A still getting credited for 100% of their original influence? Or is their share being quietly diluted by each improvement that came after them?
I couldn't find a clear answer anywhere in the documentation. And it matters more than it sounds. 👀
Think about what that incentive structure actually looks like if attribution dilution is real.
You contribute high-quality domain data early. Attribution score looks strong. Then developers start fine-tuning. Each update shifts the output distribution a little further. Your original contribution's influence on current outputs decreases — not because your data got worse, but because the model got better around it. Your reward flow shrinks. Quietly. Consistently.
That's the opposite of what this system is supposed to do.
It's supposed to create compounding returns for early, high-quality contributors. If fine-tuning dilutes attribution instead, it punishes exactly the people it should be rewarding. You contributed before the model was valuable enough to generate real inference demand. By the time demand arrives, your share has been eroded by everyone who improved the model after you.
I watched something similar happen in DeFi summer.
Early LPs provided liquidity before the pools had volume. They took the most risk. Got the worst execution. Then volume arrived, fees started flowing, and later LPs entered at better prices with less impermanent loss risk — and captured a disproportionate share of fee revenue. Being early wasn't rewarded. It was diluted by the people who showed up after the hard part was done.
This has the same shape. If my reading of the mechanics is right.
Here's the thing though — the January update existing at all is actually a signal I find genuinely encouraging.
You don't build infrastructure for a problem you don't think is real. The team clearly identified model evolution tracking as something worth engineering around. That matters.
What I can't tell from the update description is whether they solved the dilution problem or just tracked it more precisely. Those are completely different outcomes. One means early contributors are protected. The other means the system now has better visibility into exactly how much they're being diluted.
I genuinely don't know which one shipped.
The honest risk here is specific and slow.
If attribution dilution compounds over time, @OpenLedger won't face a sudden crisis. The datanets will fill up. Contribution volume will look healthy on-chain. Everything will appear fine.
Underneath that, the earliest and highest-quality contributors — the ones whose data actually shaped the model's foundational capabilities — will be quietly earning less and less for work that mattered most. That's not a catastrophic failure. It's a structural one. The kind that doesn't show up in metrics until the contributors who noticed it have already quietly stopped contributing.
What I'd actually want to see — and haven't seen yet — is a transparent breakdown of how attribution shares evolve across a model's fine-tuning history. Not a whitepaper description of the mechanism. Actual on-chain data from a live datanet. What happened to early contributor rewards after the model was updated. That specific disclosure would tell me whether the January engine update solved the problem or just named it more precisely.
Until that data exists publicly, I'm watching fine-tuning activity on active datanets more carefully than anything else about this protocol.
The diagram says it plainly: 100% credit. Then 80%. Then 60%.
The question @OpenLedger still needs to answer is whether that's a feature or a flaw. 🔍
@OpenLedger | $OPEN | #OpenLedger
⚠️ Personal analysis only. Not financial advice. DYOR.