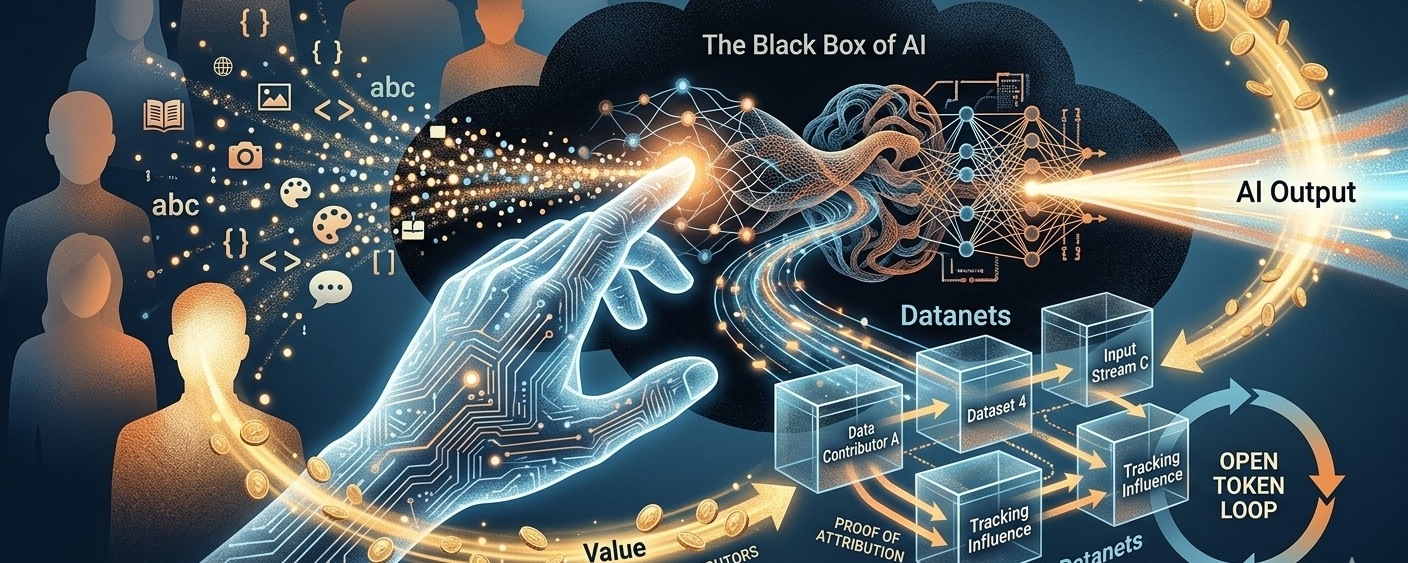
There’s something off about the way AI systems are built right now. They pull in everything—text, images, code, conversations—and turn it into something insanely powerful. But the people feeding that system? They’re basically invisible once the output shows up.
That’s the tension OpenLedger is trying to mess with.
Look, the core idea isn’t complicated. If a model gets better because of certain data, that contribution shouldn’t just disappear into a black box. Right now it does. Everything gets blended together, and no one can really say what mattered and what didn’t.
OpenLedger is trying to break that blur.
They call one part of this “Proof of Attribution,” which sounds heavy, but the idea is pretty simple: track what actually influenced what. Which data helped the model behave differently. Which inputs moved the needle. Not in a vague “this dataset was useful” way, but something closer to cause and effect.
The catch is, doing that inside modern AI systems is messy. These models aren’t exactly transparent machines. So instead of dumping everything into one giant pool like usual, they split things into these structured environments—Datanets. Think of them like smaller, focused data ecosystems where you can actually see what’s coming in and what impact it has.
That alone doesn’t solve the incentive problem though.
So there’s also the token side—OPEN. It’s meant to connect the whole loop: people contribute data, systems use it, models improve, and value gets pushed back into the same loop instead of just flowing upward to whoever owns the infrastructure. In theory, at least.
Here’s the reality: most of today’s AI economy doesn’t care where value comes from. It just consumes and scales. OpenLedger is basically trying to force memory into that system. To make it remember who contributed what.
I’ll be honest, parts of this are still very early. Attribution in AI is notoriously hard, and anyone pretending it’s already solved is overselling it. But the direction is interesting. Because once you start thinking in terms of “who influenced the model,” you can’t really go back to treating data as this free, anonymous resource.
And that’s the bigger shift here. Not the token, not the branding, not even the architecture. It’s the idea that contribution inside AI systems might eventually stop being invisible.
