Daten sind die Grundlage der modernen künstlichen Intelligenz.
Jedes Modell, jeder Empfehlungsalgorithmus, jeder KI-Assistent und autonome Agent basiert auf riesigen Mengen an Informationen, um zu lernen, sich zu verbessern und Ergebnisse zu generieren. Trotz dieser Realität bleibt eine der größten Herausforderungen der KI-Branche weitgehend ungelöst: die wirtschaftliche Struktur, die sich um die Daten selbst bildet.
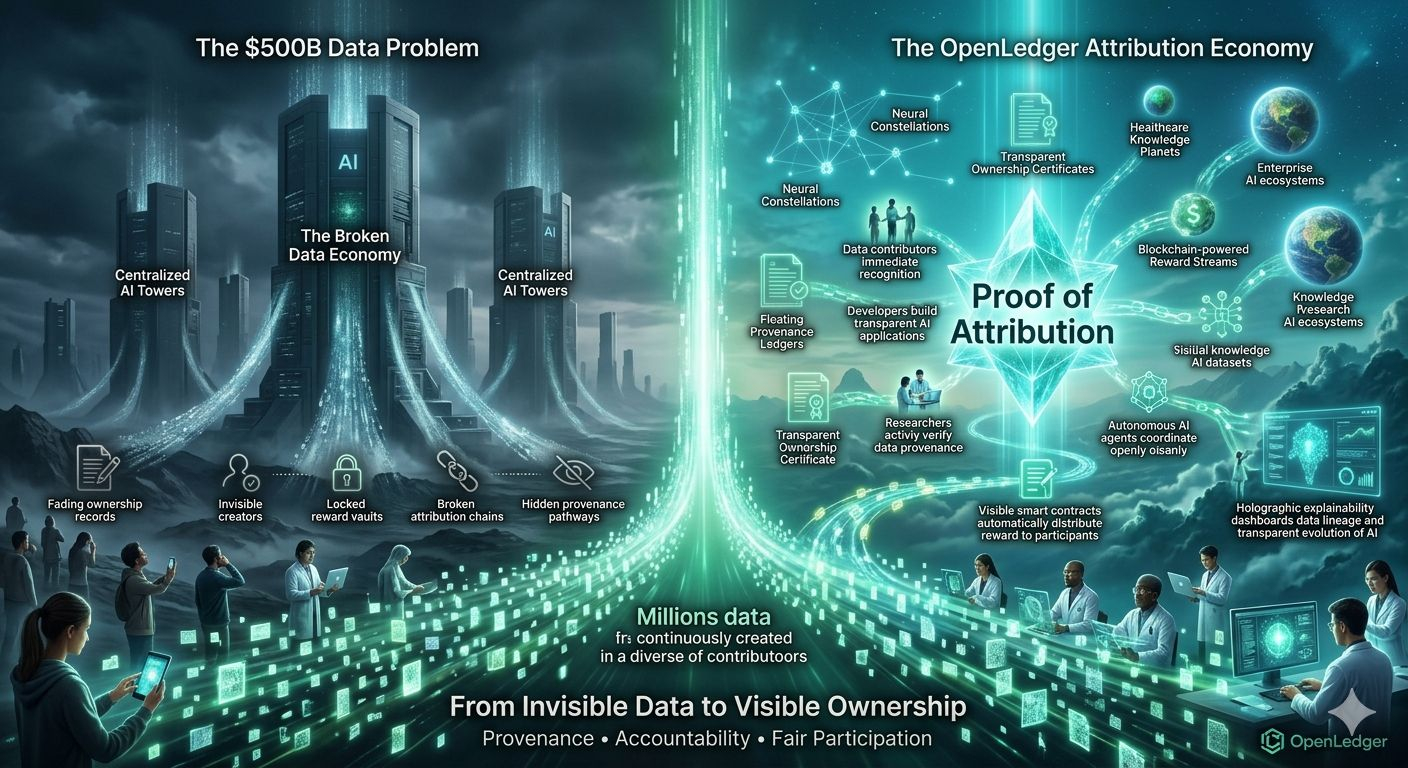
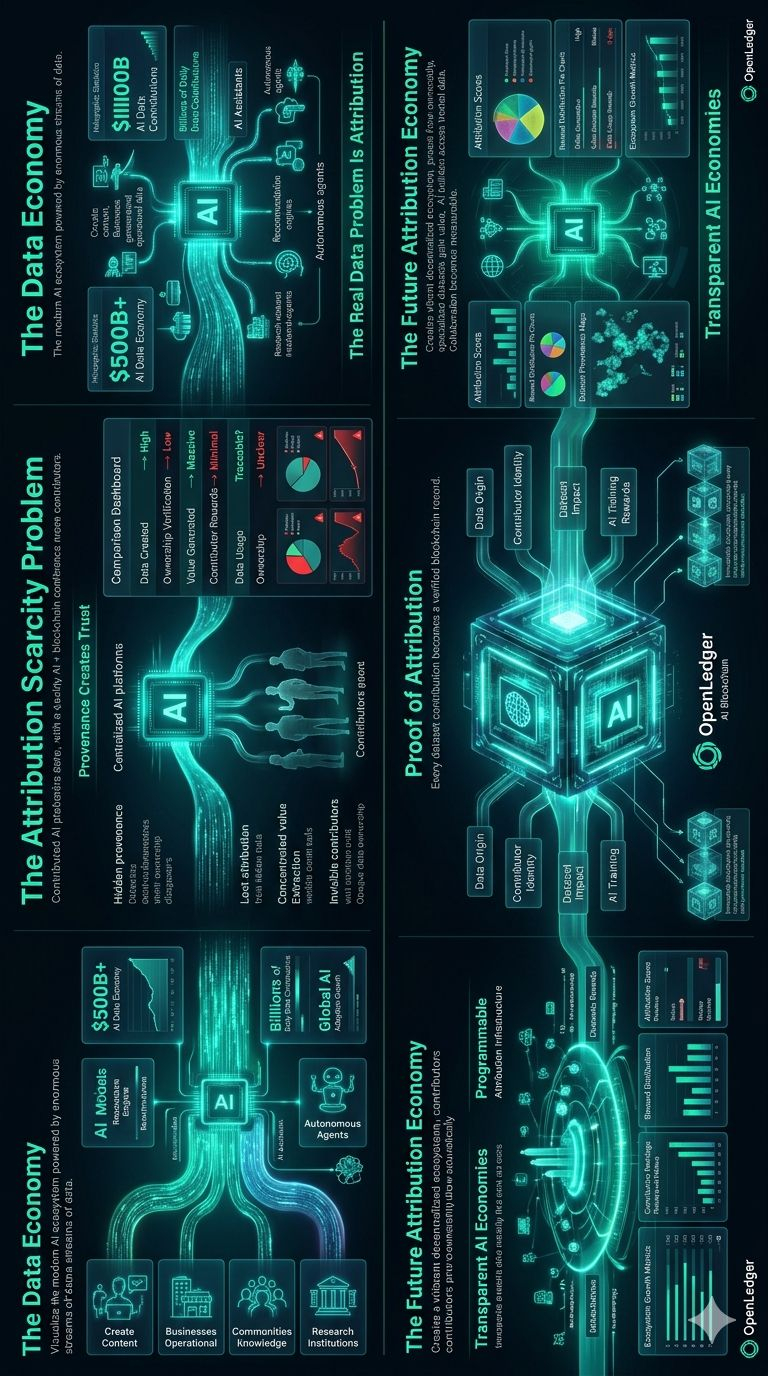
Weltweit werden kontinuierlich wertvolle Datensätze von Einzelpersonen, Gemeinschaften, Unternehmen und Institutionen erstellt. Diese Datensätze treiben Innovationen voran, verbessern die Modellleistung und schaffen kommerzielle Werte im Wert von Hunderten von Milliarden Dollar.
Doch die Mitwirkenden, die für die Generierung dieses Wertes verantwortlich sind, bleiben oft unsichtbar.
Die meisten bestehenden KI-Systeme bieten nur begrenzte Transparenz darüber, woher die Daten stammen, wie sie das Verhalten des Modells beeinflussen oder wer für seine Beiträge belohnt werden sollte. Daten fließen durch zentralisierte Plattformen, wo die Zuschreibung schwer zu überprüfen ist und die wirtschaftliche Teilnahme sich auf eine kleine Anzahl von Stakeholdern konzentriert.
Das schafft, was OpenLedger als das $500B-Datenproblem beschreibt.
Das Problem ist nicht der Mangel an Daten.
Das Problem ist die Knappheit der Zuschreibung.
Ohne transparente Zuschreibung können Mitwirkende kein Eigentum nachweisen. Ohne Eigentum schwächen sich die Anreizstrukturen. Ohne Anreize wird es zunehmend schwierig, qualitativ hochwertige spezialisierte Datensätze aufrechtzuerhalten.
Die vorgeschlagene Lösung von OpenLedger ist die KI-Blockchain.
Anstatt Daten als unsichtbaren Input zu behandeln, zeichnet OpenLedger Beiträge direkt on-chain durch sein Proof of Attribution-Framework auf. Jeder Beitrag kann mit seinem Ursprung verknüpft, auf seinen Einfluss gemessen und in ein transparentes System der Anerkennung und Belohnungen integriert werden.
Dieser Ansatz bringt mehrere wichtige Vorteile mit sich.
Zuerst verbessert es die Herkunft. Datenquellen werden nachvollziehbar, was stärkeren Vertrauen und Verantwortlichkeit während des gesamten KI-Lebenszyklus schafft.
Zweitens richtet es die Anreize aus. Mitwirkende erhalten einen Mechanismus, um an dem Wert teilzuhaben, den sie helfen zu schaffen, anstatt passive Anbieter zu bleiben.
Drittens unterstützt es die spezialisierte KI-Entwicklung. Da Branchen zunehmend nach domänenspezifischen Modellen verlangen, wird der nachhaltige Zugang zu qualitativ hochwertigen Datensätzen zu einem Wettbewerbsvorteil.
Vielleicht am wichtigsten ist, dass OpenLedger die Zuschreibung in eine Infrastruktur verwandelt, anstatt nur ein Nachgedanke zu sein.
In traditionellen Systemen ist die Zuschreibung oft manuell, unvollständig oder gänzlich abwesend. In einer KI-nativen Blockchain-Umgebung wird die Zuschreibung programmierbar, überprüfbar und wirtschaftlich sinnvoll.
Die breitere Implikation reicht über einzelne Datensätze hinaus.
Es deutet auf eine KI-Wirtschaft hin, in der Zusammenarbeit transparent ist, Beiträge messbar sind und der Wert fairer durch das gesamte Ökosystem fließt.
Während die künstliche Intelligenz weiterhin in jeden Sektor der Gesellschaft expandiert, könnte die Lösung des Datenproblems ebenso wichtig werden wie die Verbesserung der Modelle selbst.
OpenLedger baut auf dem Glauben auf, dass die Zukunft der KI nicht nur Intelligenz, sondern auch Verantwortung, Herkunft und faire Teilnahme erfordert.
\u003cc-54/\u003e \u003ct-56/\u003e \u003cm-58/\u003e