OpenLedger started as a fairly practical response to something that kept showing up in its AI infrastructure tests: not model quality, not prompt design, but the way requests were being retried, rerouted, and quietly reshaped under load. When traffic spiked, the same request would not behave the same way twice. Sometimes it hit a fast model path, sometimes it got pushed into a fallback cluster, and sometimes it simply waited long enough that the user gave up and resent it, which created its own duplicate load loop. That repetition, more than anything else, is what pushed the team toward Ethereum and the OP Stack.
The decision was not framed as ideology inside the system. It was more like trying to stop retry behavior from becoming a hidden form of privilege.
In early internal notes, someone wrote a line that kept resurfacing in discussions:
In distributed AI systems, the real scarcity is not compute but clean retries.
That line started showing up in design reviews because it matched what was actually breaking under pressure. OpenLedger’s routing layer was handling inference requests across multiple model providers, but every retry introduced drift. A request that should have been identical in logic would end up with different routing outcomes depending on timing, congestion, and prior failures. In practice, two users asking the same thing could get different levels of “effort” from the system, not because of intent, but because retry windows were unevenly distributed.
One early experiment made this visible. A batch of 10,000 inference requests was sent through a multi-model router with a retry budget capped at 3 attempts per request. Under load, about 14 percent of those requests exhausted their retry budget before reaching the “best” model tier, landing instead on cheaper fallback inference paths. When the retry budget was expanded to 7, latency increased by roughly 220 milliseconds per request on average, but fallback usage dropped by nearly 40 percent. The uncomfortable part was not the numbers, it was the realization that user experience was being silently priced by retry capacity rather than intent.
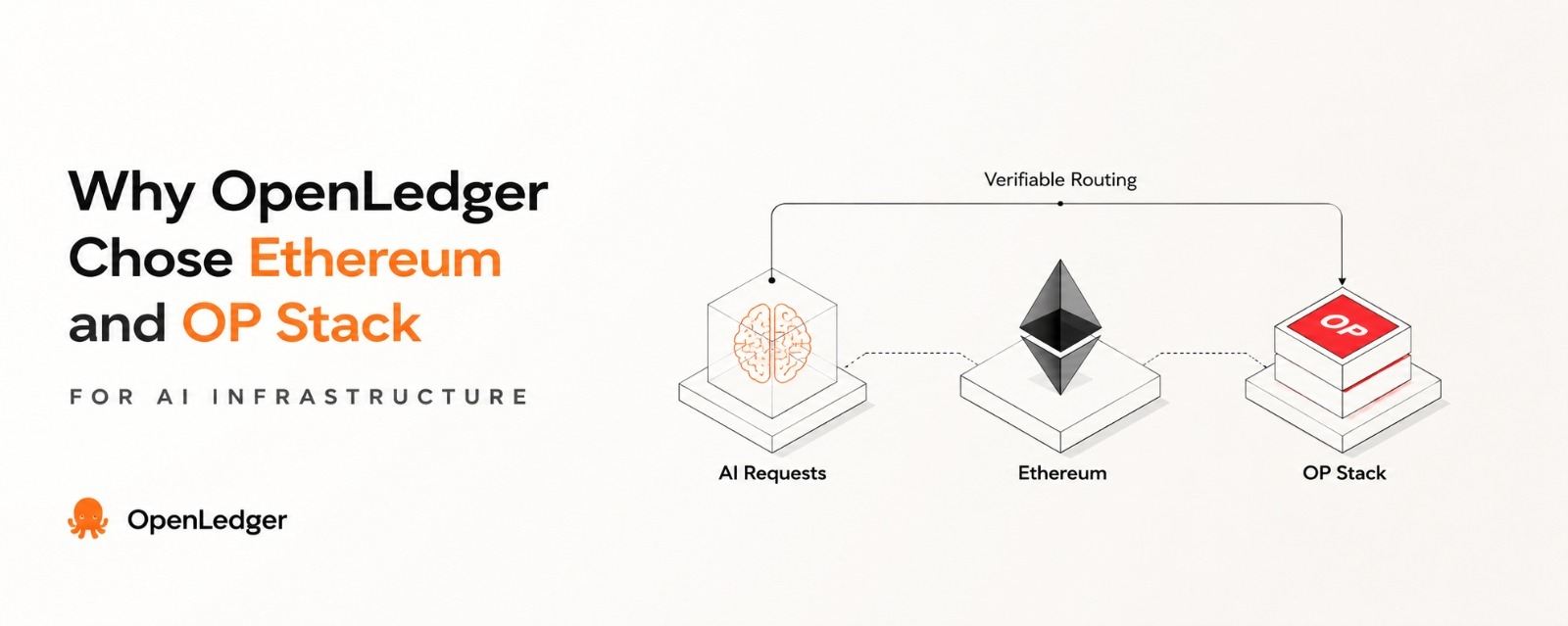
Ethereum entered the design conversation at this point not as a compute layer but as an accountability layer for routing outcomes. If OpenLedger was going to treat inference as something that needed verifiable routing decisions, then those decisions needed a place where they could not be rewritten by transient load conditions alone. OP Stack gave them a sequencing model where batches of routing decisions could be committed, observed, and replayed under consistent rules without rebuilding a full L1 dependency every time.
A second mechanical test made this clearer. OpenLedger simulated a sequencing layer built on OP Stack where 1,200 inference routing decisions were bundled into a single batch. Each batch carried metadata about model selection, retry count, and fallback triggers. Under a naive routing system, about 11 percent of requests in peak load conditions were re-routed mid-flight due to congestion shifts. With OP Stack sequencing, that mid-flight rerouting dropped to under 3 percent, but the system introduced a consistent delay of 300 to 450 milliseconds before final routing confirmation was available. That delay was not a bug. It was the cost of making routing outcomes stable enough to audit.
The tradeoff became hard to ignore. Lower variance in routing meant fewer surprises in model quality, but it also meant the system felt slightly less “instant” during peak demand. Engineers described it as a tension between perceived responsiveness and structural fairness. You could make the system feel faster by allowing local reroutes, but that speed came from letting retry behavior silently decide quality tiers.
Halfway through this shift, a debate surfaced internally that never fully settled. If routing fairness depends on slowing down confirmation, is that still a user-facing improvement or just infrastructure discipline masquerading as UX design. Some argued that the delay was unacceptable at scale, especially for interactive workloads. Others pointed out that without it, the system was effectively allowing network congestion to decide which users got better model paths.
There was also skepticism about Ethereum’s overhead itself. Not everyone was convinced that anchoring routing integrity to a blockchain layer was justified. One engineer described it as “introducing ceremony into something that used to be just a function call,” and that criticism never really disappeared, even after benchmarks improved consistency.
The token layer only appeared later, and even then it did not feel like a centerpiece. It was tied to routing stakes, not speculation. Validators and routing participants needed something at risk when they influenced fallback decisions or prioritized certain inference paths. In one internal scenario, a misrouted batch during congestion could be traced back and penalized through staked routing commitments, which reduced malicious or lazy fallback selection by a measurable margin, around 6 to 9 percent depending on load simulation. But even that mechanism created friction, because now participation in routing quality had a cost barrier that did not exist before.
That is where doubt lingers. If correctness depends on economic friction, then “open” starts to feel slightly negotiated.
A question that keeps coming back in design reviews is simple but uncomfortable: what happens when retry budgets hit zero during peak load and no one is sure whether the system is slow or just being selective?
And another one that no one fully answers yet: would you accept a slower first response if it guaranteed that every retry was treated identically, regardless of timing or congestion?
Sometimes the system feels like it is moving toward clarity. Other times it just feels like it is making failure more consistent rather than less frequent.
And then there is the deeper uncertainty that sits under all of it, still unresolved in practice, still debated quietly after deployments: where does fairness actually live in this stack, the model, the router, or the settlement layer that remembers what the router chose when everything was under pressure.
