Market's been slow this week. Not crash slow, just that weird in between phase where nothing's really moving and everyone's pretending they have a strategy.
I ended up falling down a rabbit hole instead of watching charts.
I was looking at @OpenLedger . Specifically their incentive model how they're trying to get people to contribute data and validate it. And somewhere around the third time re reading their contributor flow, something stopped me.
The framing around OpenLedger is mostly: AI needs better data, blockchain makes data verifiable, contributors get rewarded. Clean pitch. People nod along. But I kept getting stuck on a question nobody really asks out loud.
Who decides what good data actually looks like?
Because here's the thing. Validator based systems usually carry an assumption that feels obvious but isn't: that validators are a neutral layer. They confirm or reject. They're the checks. But in a data marketplace especially one feeding AI models validators aren't just verifying existence of data.
They're making judgment calls about quality. And quality is not neutral. Quality is opinionated.
So the incentive model isn't just rewarding contribution. It's rewarding whatever validators decide is worth rewarding.
I sat with that for a bit.
Most contributor systems I've watched play out follow a pretty predictable arc. Early phase: genuine contributors come in, motivated by the upside, the mission, whatever. Middle phase: people figure out what the system rewards and start optimizing for that specifically.
Late phase: the metric becomes the product, not the underlying thing the metric was supposed to measure. Data quality decouples from reward signal.
OpenLedger's design seems aware of this there's reputation stacking, there are slashing mechanics for bad validation, there's layered accountability. The structure is more thoughtful than most. That's genuinely worth acknowledging.
But here's the part that bothers me.
Slashing works when bad behavior is legible. When a validator signs off on obviously corrupted data, the system can catch it. But what about the slow drift? The gradual convergence toward whatever data type is cheapest to produce and easiest to validate? Nobody gets slashed for that. The incentives just quietly reshape what contributors bother submitting and over months, the dataset starts reflecting the incentive structure more than the actual world.
I'm not fully convinced this holds under sustained extraction pressure. When token prices move and the economics get interesting, contributor behavior changes in ways that are hard to anticipate and slow to show up in on chain signals.
There's also something I initially misread. I thought the validator role was mostly passive review, confirm, move on. It's actually more active than that, with validators taking positions on data quality that affect their own stake.
Which is interesting design. It means validators have skin in the game on quality judgment, not just participation. That's meaningfully different from most systems.
Whether that's enough to prevent the drift I'm describing, I genuinely don't know.
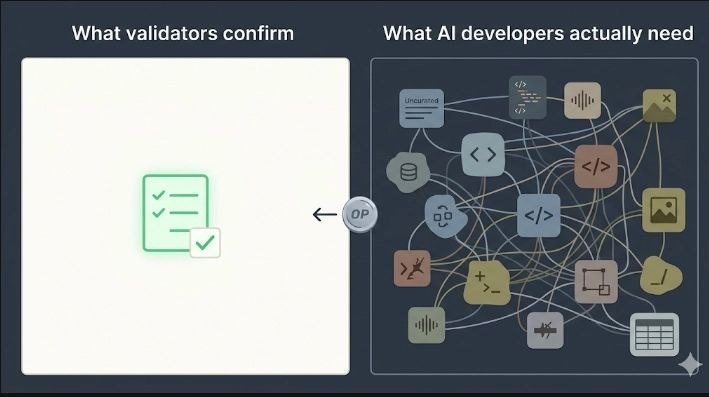
What I do know is that the people this actually affects most aren't the early contributors or the founding validators. It's the AI developers downstream, consuming the data.
They're the end customer in this whole structure, and they're mostly invisible in the incentive design. They don't have a direct mechanism to pull the dataset toward what they actually need. They consume what the incentive model produced.
That gap between what contributors are rewarded to produce and what AI developers actually want feels like the slow tension nobody's talking about yet. It might not matter in the first cycle. It usually doesn't. It tends to matter in the second one.
Anyway. Still watching how the token distribution end of this plays out. That piece usually tells you more than the whitepaper does.
Market still looks like it's deciding something. Could go either way.