Ehrliche Überlegung... Ich nahm immer an, dass kryptografische Integrität und Skalierbarkeit nur zwei Punkte auf demselben Schieberegler sind. Schiebe den einen hoch, der andere geht runter. Diese Annahme hielt, bis ich anfing zu lesen, wie OpenLedger tatsächlich seine Transaktionsschicht strukturiert. Rollups, die den Durchsatz handhaben, während kryptografische Zustandsübergänge jede Zuschreibungsaufzeichnung dauerhaft sperren. Es ist kein Schieberegler..... Es sind zwei separate Systeme, die zwei separate Aufgaben erledigen, und die Architektur funktioniert nur, weil keines von beiden gebeten wird, die Arbeit des anderen zu erledigen.
Es gibt eine bestimmte Art von Müdigkeit, die sich aufbaut, wenn du genug Blockchain-Projekte beobachtet hast, die dasselbe Versprechen in verschiedenen Schriftarten machen. "Wir haben das Trilemma gelöst." "Unendlich skalierbar und vollständig dezentralisiert." Ich habe diese Zeilen so oft gelesen..... dass ich aufgehört habe, sie als technische Behauptungen zu lesen, und angefangen habe, sie als Marketinghaltung zu lesen. Als ich also auf die Architektur von OpenLedger stieß, war mein erster Instinkt dasselbe Skepsis, die ich in alles hineintrage. Aber irgendetwas brachte mich dazu, langsamer zu werden und tatsächlich die Struktur zu lesen, anstatt nur die Überschrift.
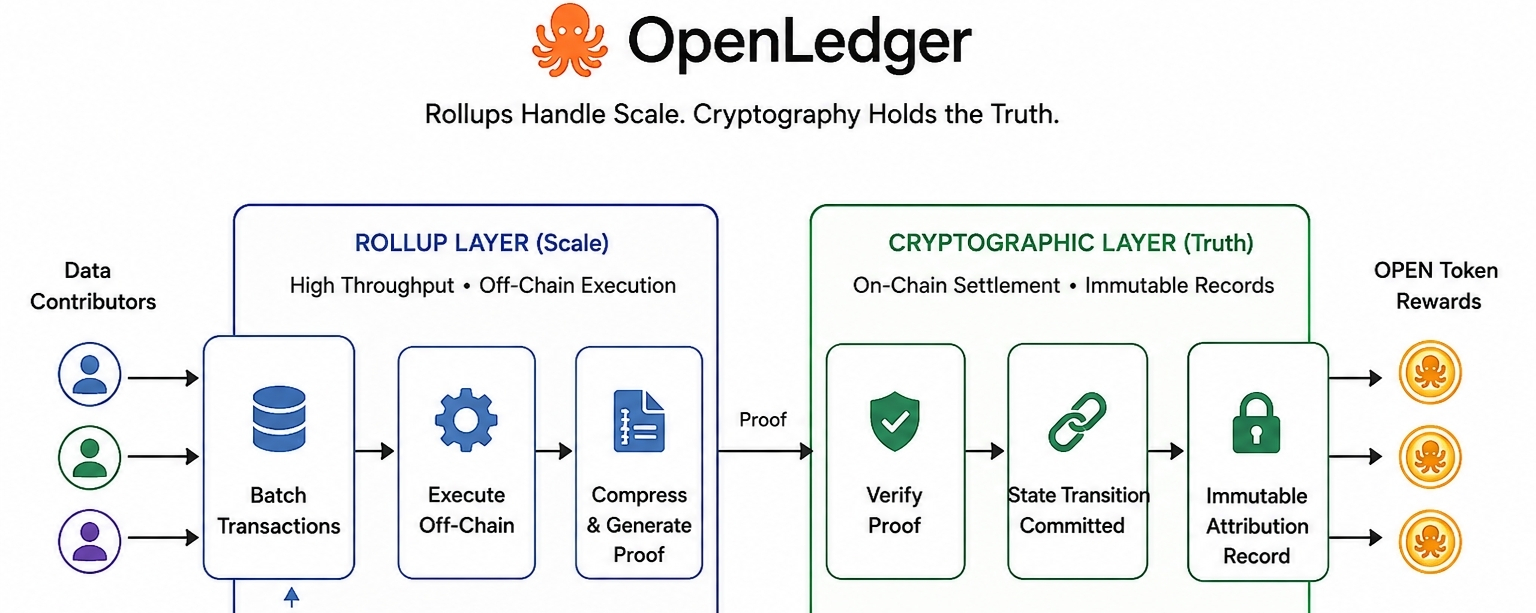
Die zentrale Spannung, die OpenLedger navigiert, ist real. Sie wurde nicht für ein Whitepaper erfunden. Jedes System, das AI-Trainingsdatenbeiträge in großem Maßstab aufzeichnen will, stößt auf die gleiche Wand, an die jede Hochdurchsatz-Blockchain stößt. Wenn du versuchst, jede einzelne Mikro-Zuschreibung in Echtzeit kryptografisch on-chain zu verifizieren, bekommst du kein leistungsfähiges System. Du bekommst einen Flaschenhals, der als Infrastruktur verkleidet ist. Die meisten Projekte lösen das, indem sie heimlich die kryptografischen Garantien lockern. OpenLedger löst es, indem es die beiden Anliegen vollständig trennt.
Rollups bündeln die Ausführung von Transaktionen außerhalb der Primärkette und komprimieren die Ausgabe in einen verifizierbaren Beweis. Dieser Beweis wird on-chain abgerechnet. Der Durchsatz lebt in der Rollup-Ebene. Die Wahrheit lebt im kryptografischen Zustandsübergang. Keines der Systeme macht doppelte Arbeit. Das ist der Teil, der mich tatsächlich zum Nachdenken gebracht hat, denn es beantwortet eine Frage, die die meisten Projekte nicht einmal anerkennen...... Wie gehst du mit Millionen von Datenbeitragsaufzeichnungen um, ohne entweder die Kette zu ersticken oder stillschweigend deine Integritätsstandards zu senken?
Das Zuschreibungsmodell ist der Punkt, an dem es spezifisch genug wird, um wichtig zu sein. Wenn ein Datensatz zu einer Trainingsdurchführung eines AI-Modells beiträgt, zeichnet OpenLedger diesen Beitrag als Zustandsänderung auf, und diese Zustandsänderung wird durch die kryptografische Schicht gesperrt. Der Rollup kümmert sich um das Volumen. Der kryptografische Datensatz kümmert sich um die Permanenz. Ein kleines Beispiel, mit dem man sich beschäftigen sollte... stelle dir vor, ein Beitragender liefert 10.000 annotierte Bilder. Jede Batch-Abrechnung wird komprimiert, verifiziert und verankert. Der Datensatz des Beitragenden hängt nicht davon ab, dass sich jemand daran erinnert. Er hängt von Mathematik ab, die später nicht leise revidiert werden kann. Diese Unterscheidung ist nicht klein, wenn man über OPEN-Token-Belohnungen spricht, die an diese Aufzeichnungen gebunden sind.
Hier ist die Frage.... Ich bin immer wieder darauf zurückgekommen. Rollup-basierte Systeme sind nur so vertrauenswürdig wie die Gültigkeitsbeweise, die sie verwenden. Optimistische Rollups gehen von Korrektheit aus und verlassen sich auf ein Herausforderungsfenster. ZK-Rollups erzeugen Beweise, die rechnerisch verifiziert werden. Das sind wirklich unterschiedliche Vertrauensmodelle, und die praktischen Implikationen für ein Zuschreibungs-Register sind erheblich. Ein optimistisches System bedeutet, dass es ein Fenster gibt, in dem eine betrügerische Beitragscharge theoretisch existieren könnte, bevor sie angefochten wird.👀 Ein ZK-System schließt dieses Fenster... trägt aber schwerere rechnerische Kosten. Die Architektur von OpenLedger tendiert zur ZK-Seite, die der schwierigere Weg ist, aber der ehrlichere für ein System, bei dem die Permanenz der Zuschreibung das gesamte Wertangebot ist.
Was ich interessant finde, ist, ob die kryptografischen Garantien unter realer Last halten, anstatt unter Testnet-Bedingungen. Jede Architektur klingt in der Dokumentation kohärent. Der Stresstest ist, ob die Beweisgenerierung Schritt hält, wenn das Datenvolumen kein kontrolliertes Demo, sondern eine tatsächliche Trainingspipeline ist, die gleichzeitig von Tausenden von Quellen Beiträge zieht.😤 Das ist keine Kritik am Design. Das ist nur die ehrliche Frage, die jede ernsthafte Infrastrukturbehauptung irgendwann beantworten muss.
Der Grund, warum ich OpenLedger genauer beobachte als die meisten Projekte, liegt nicht daran, dass die Roadmap poliert ist. Es liegt daran, dass das Problem, das sie lösen, wirklich schwierig ist... und ihre architektonische Antwort die Schwierigkeit anerkennt, anstatt sie zu kaschieren. Rollups für Skalierung, kryptografische Zustandsübergänge für Wahrheit. Zwei Systeme, zwei Aufgaben, ein Ledger. Ob das unter Druck standhält, ist weiterhin eine offene Frage.... Aber zumindest ist es die richtige Frage.
#OpenLedger #CryptoVibes #analysis 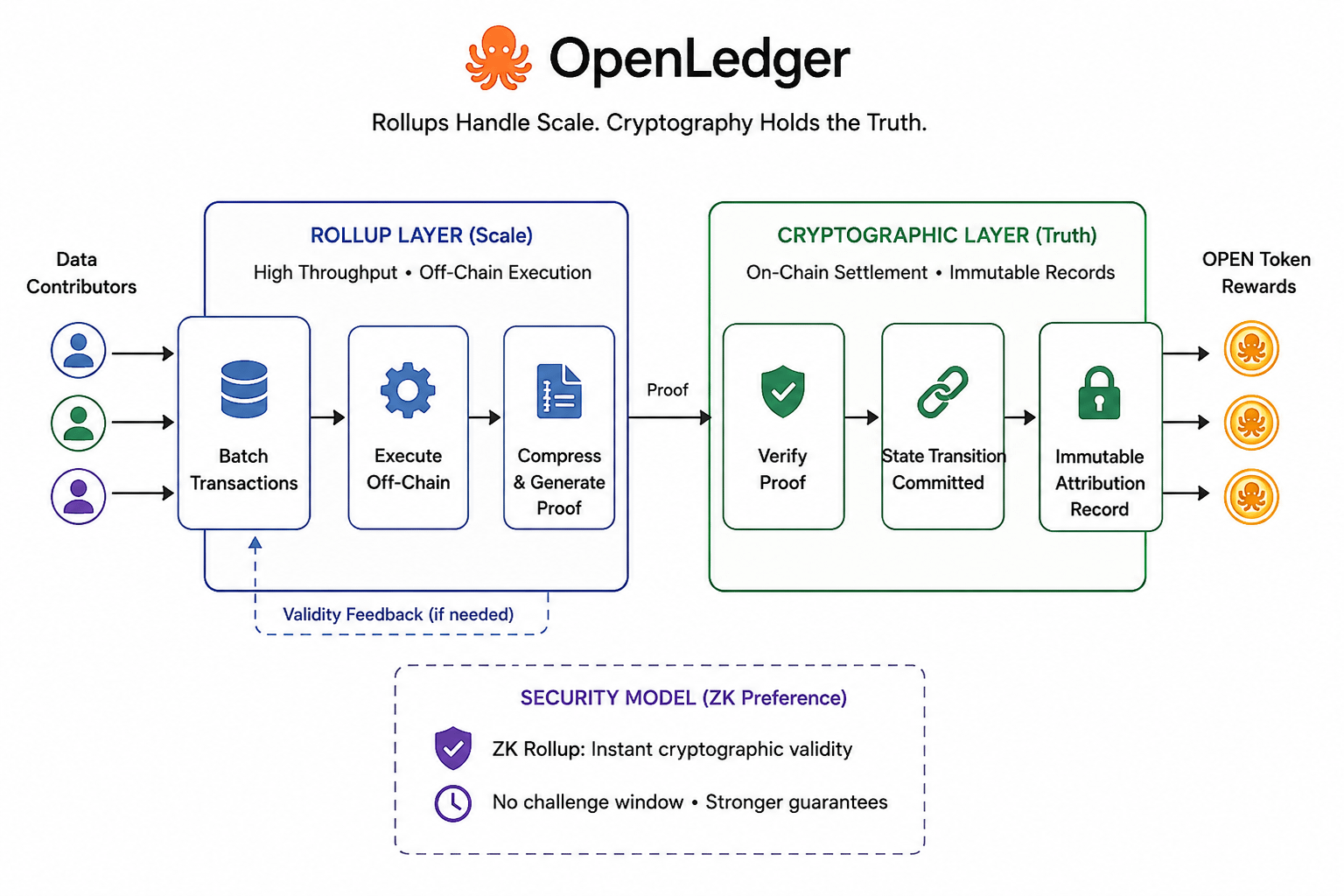
$GENIUS


