Most people use artificial intelligence without ever thinking about the invisible layer beneath it. A chatbot answers questions instantly, an AI tool writes code, or an image generator creates artwork in seconds. The experience feels smooth and almost effortless. But behind every AI system sits an enormous amount of human-created information collected over many years from writers, developers, researchers, artists, online communities, and ordinary internet users. The strange part is that most of those contributors never really know how their data was used or whether they benefited from it at all.
For a long time, this issue was ignored because the AI industry moved so quickly. Companies focused on building larger models, gathering more data, and improving performance. Investors cared about growth, users cared about convenience, and developers cared about capability. Questions around ownership and attribution stayed somewhere in the background because there was no simple way to solve them.
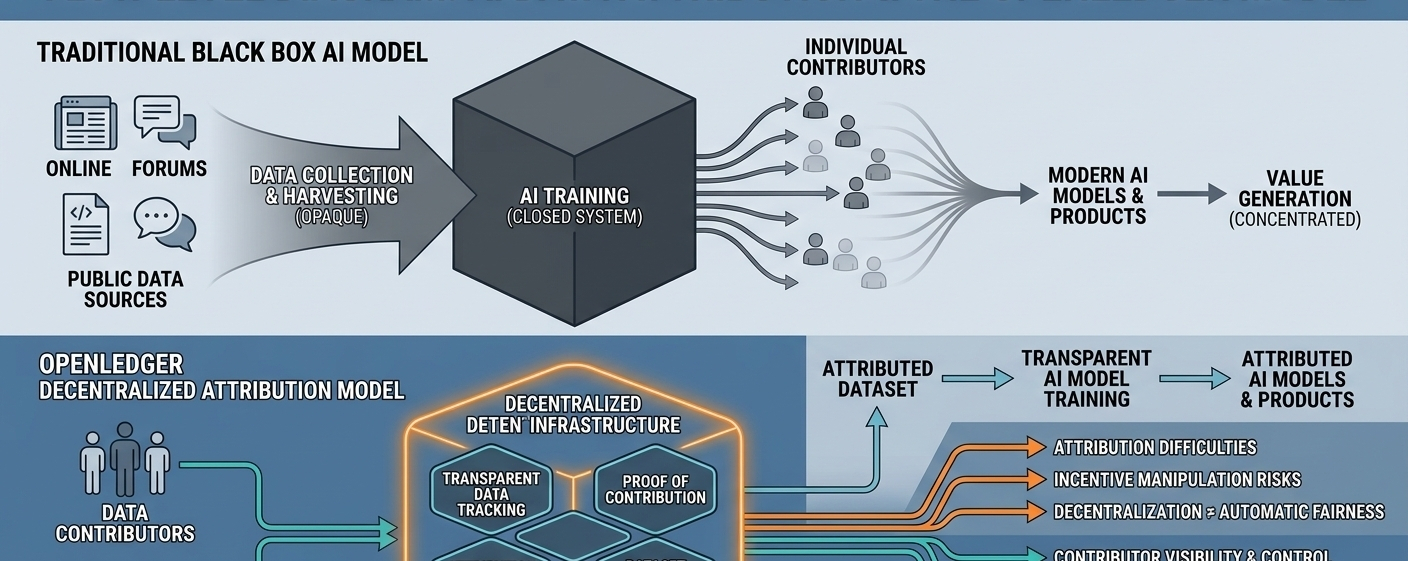
The deeper problem is that modern AI systems are extremely difficult to trace. Once data enters a neural network, it becomes part of a much larger structure where information blends together. Unlike traditional databases, AI models do not store knowledge in neat, visible folders. They learn patterns from massive amounts of information at once. That makes it hard to identify which specific dataset or contributor influenced a final output.
Earlier attempts to address this problem usually focused on only one part of the process. Some projects tried decentralized storage systems. Others explored blockchain-based AI marketplaces or federated learning. Researchers also experimented with watermarking datasets and creating transparent training systems. But most of these ideas struggled when moving from theory into real-world usage. The technical challenge turned out to be much bigger than expected.
This is the space where OpenLedger is trying to position itself. Instead of building another AI chatbot or competing directly with large model providers, the project focuses on the infrastructure around AI itself. Its broader argument is simple: if human-generated data plays such an important role in AI development, there should be better systems for tracking contributions and understanding how value moves through the network.
One of the main ideas behind OpenLedger is something called “Proof of Attribution.” In simple language, it is an attempt to connect data contributors with the way AI systems use information later. The project wants to create a structure where datasets, model activity, and outputs can be linked more transparently instead of disappearing into a black box.
At first, this idea sounds reasonable because other digital industries already rely on attribution systems. Music platforms track streams and royalties. Software communities monitor code contributions. Content creators on social platforms increasingly expect ownership and monetization tools. Compared to those industries, AI still operates with surprisingly weak systems for acknowledging contribution.
OpenLedger also introduces the concept of “Datanets,” which are designed as organized environments for collecting specialized datasets. Rather than relying entirely on huge centralized pools of internet data, the project suggests that communities and contributors could build more focused data ecosystems for specific industries or use cases.
This matters because AI is gradually moving away from simply collecting massive amounts of generic online content. Specialized AI systems now require more accurate and curated information. Healthcare models need reliable medical knowledge. Legal AI systems depend on structured legal documents. Enterprise AI tools often require private operational data. In these situations, quality matters more than quantity.
Another interesting part of OpenLedger is its focus on attribution during inference, not just training. Most AI users never know which external information sources influenced the answers they receive. OpenLedger attempts to make those relationships more visible. The goal is not only transparency, but also the possibility that contributors could eventually benefit when their data is actively used.
The project also explores efficiency through systems like OpenLoRA, which focuses on lightweight AI model adapters instead of training entirely separate models repeatedly. The thinking behind this approach is practical. AI infrastructure is becoming increasingly expensive, and modular systems may offer a more flexible way to support specialized AI applications without constantly rebuilding everything from scratch.
Still, there are clear limitations to this vision. Attribution inside AI systems remains one of the hardest technical problems in the industry. Neural networks do not work like simple mathematical equations where every output has one obvious source. Knowledge inside these systems is distributed across billions of parameters, making perfect attribution extremely difficult.
There is also the issue of incentives. Any open network that rewards contributions eventually faces spam, manipulation, and low-quality submissions. Some participants will naturally try to exploit the system for rewards rather than contribute meaningful data. Maintaining quality while keeping participation open is much harder in practice than it sounds in theory.
Governance creates another challenge. Many decentralized projects begin with promises of fairness and community participation, but influence often becomes concentrated among early insiders or technically advanced participants. OpenLedger may face similar issues over time because decentralized systems do not automatically eliminate power imbalances.
Privacy concerns also remain unresolved. Full transparency may sound appealing in theory, but many organizations are uncomfortable exposing sensitive training data or internal workflows. Industries like finance, healthcare, and enterprise security often prioritize privacy and operational control over openness. Finding a balance between transparency and confidentiality will not be easy.
Even with these concerns, OpenLedger reflects a broader shift happening across the AI industry. Conversations are slowly moving beyond model performance alone and toward deeper questions about ownership, accountability, and data relationships. As AI systems become more integrated into everyday life, those questions are becoming harder to ignore.
The people who could benefit most from systems like this are smaller contributors who currently receive little recognition in the AI economy. Independent researchers, niche communities, and specialized experts often create valuable information without any visibility into how their work is later used. A transparent attribution layer could potentially give those contributors more participation in the ecosystem.
At the same time, there is no guarantee that decentralized infrastructure automatically creates fairness. Participants with better resources, larger datasets, or stronger technical knowledge may still dominate the system. Open networks can redistribute power differently without necessarily making access equal for everyone involved.
What makes OpenLedger interesting is not that it claims to solve every problem around AI ownership. The more important point is that it highlights a weakness that already exists beneath the surface of the industry. Modern AI systems depend heavily on human-generated knowledge, yet the mechanisms for attribution and participation still feel incomplete.
As artificial intelligence continues evolving, the biggest debate may eventually move beyond which company builds the smartest model. The harder question could become whether the people contributing knowledge to these systems will remain invisible, or whether future AI infrastructure will finally begin treating data contribution as something worth recognizing in a meaningful way.
