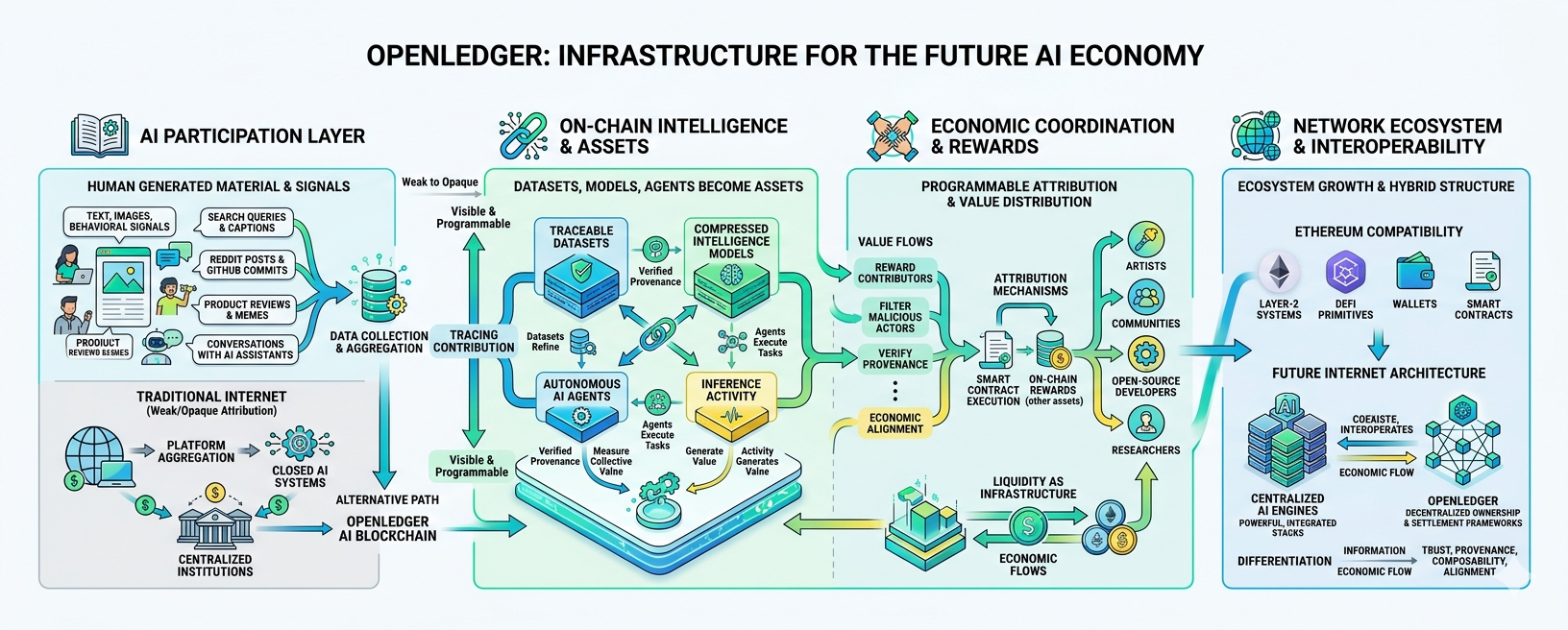
Every day, billions of people generate text, images, behavioral signals, conversations, preferences, annotations, reactions, corrections, and cultural context. Most of this activity feels casual and disposable while it is happening. A search query. A caption. A Reddit post. A support ticket. A GitHub commit. A product review. A meme. A conversation with an AI assistant late at night.
But underneath the surface, these fragments are becoming raw material for machine intelligence.
Large AI systems absorb human knowledge at planetary scale, compressing enormous amounts of social, linguistic, emotional, and technical information into models that eventually become products worth billions of dollars. The process feels both miraculous and oddly asymmetrical. Humanity continuously feeds the machine, but ownership of the resulting intelligence often consolidates into a remarkably small number of institutions.
That imbalance is where projects like OpenLedger begin to matter.
Not because they have solved the problem already. They have not. And honestly, the harder questions may only be starting.
But OpenLedger represents a serious attempt to rethink the infrastructure layer beneath AI economies themselves — particularly the problem of attribution, participation, and economic coordination in a world increasingly shaped by autonomous systems.
Most people still underestimate this shift.
The conversation around AI is still dominated by model performance, GPUs, benchmarks, and consumer applications. Yet beneath the visible competition between chatbots and model providers sits a deeper unresolved issue: who owns intelligence production in an AI-native internet?
That question becomes economically explosive very quickly.
Modern AI systems are trained on oceans of human-generated material, but the mechanisms for tracing contribution are weak, opaque, or nonexistent. Artists rarely know when their styles influence outputs. Communities cannot easily measure how much value their collective knowledge created. Researchers contribute discoveries that are integrated into broader systems without direct participation in downstream economics. Even open-source developers often watch billion-dollar ecosystems emerge around work they released freely.
The current structure resembles extraction more than participation.
And that is where OpenLedger’s thesis starts becoming interesting.
The project positions itself not simply as another blockchain, but as an “AI Blockchain” — infrastructure designed specifically for AI participation. That wording matters because it implies a different assumption about what blockchains are for. Traditional Layer-1 narratives often revolve around payments, decentralized finance, or generalized smart contract execution. OpenLedger instead treats AI itself as the primary economic actor.
Datasets become assets.
Models become assets.
Agents become assets.
Inference activity becomes economic activity.
Coordination becomes programmable.
The infrastructure layer usually matters more than people realize.
Historically, the systems that quietly standardized ownership and settlement often reshaped entire economies. The internet itself was not valuable merely because websites existed. It became transformative because protocols allowed information exchange at global scale. Financial markets expanded because settlement systems became standardized and interoperable. Intellectual property frameworks altered industrial incentives because attribution could be formalized and monetized.
AI appears to be entering a similar phase.
Right now, the relationship between AI systems and value creation remains blurry. Companies scrape, train, deploy, monetize, and optimize inside largely closed ecosystems. Attribution is weak because tracing how individual data points influence outputs is computationally and philosophically difficult. Human contribution dissolves into statistical abstraction.
OpenLedger is attempting to build infrastructure where those relationships become economically visible.
At least in theory.
The idea is deceptively simple: if data, models, and autonomous agents are participating in economic production, then perhaps they should exist as traceable on-chain entities capable of generating, receiving, and distributing value.
That sounds almost obvious once stated clearly.
Yet modern internet architecture was never really designed for this. Existing web systems excel at content distribution and platform aggregation, but they struggle with granular ownership accounting at AI scale. Traditional databases can track transactions, but they do not inherently create open economic coordination layers. Closed AI systems can optimize performance, but they rarely expose transparent reward mechanisms for contributors.
OpenLedger’s attempt to place AI participation directly on-chain reflects a belief that future intelligence economies require native economic infrastructure, not merely APIs attached to centralized platforms.
That distinction may become increasingly important.
Consider what happens as autonomous AI agents become more capable over the next decade. Not science fiction robots — simply software entities continuously performing economic tasks online. Agents managing liquidity. Agents analyzing research. Agents negotiating services. Agents generating media. Agents coordinating logistics. Agents training smaller models specialized for niche domains.
If these systems begin interacting continuously across digital markets, questions of identity, ownership, compensation, and verification become unavoidable.
Who owns an autonomous agent’s output?
Who gets paid when a model improves from community data?
How are contributors rewarded?
How are malicious actors filtered out?
How do agents transact with each other?
How do systems verify provenance?
How does trust emerge in machine-native economies?
These are not merely technical questions anymore. They are institutional questions.
And honestly, that may become the real economic battle.
OpenLedger’s emphasis on monetizing datasets, models, and agents reflects recognition that future AI economies may revolve less around static software ownership and more around continuously operating intelligence systems. In that environment, liquidity itself becomes infrastructure. Assets are no longer passive files sitting on servers. They become productive entities generating outputs, interacting with networks, and potentially earning ongoing economic flows.
That changes the meaning of digital ownership.
Today, ownership online is often shallow. Users technically “own” accounts, tokens, or content, but most value accrues to platforms coordinating attention and computation. OpenLedger’s broader philosophical direction suggests a different model where contributors participate more directly in intelligence production itself.
Whether that vision succeeds is another question entirely.
Because the difficulties here are enormous.
Attribution inside AI systems is one of the hardest coordination problems in modern computing. Neural networks do not naturally expose clean causal maps between specific data contributions and final outputs. Human creativity itself is deeply derivative and interconnected. The boundaries between inspiration, contribution, transformation, and replication are often ambiguous even before machines enter the equation.
Trying to formalize attribution at scale could become computationally expensive, socially contentious, and vulnerable to manipulation.
That’s where things start becoming uncomfortable.
Open systems attract spam.
Economic incentives distort behavior.
Low-quality data farming could overwhelm meaningful contributions. Speculators may chase token rewards without creating genuine utility. Contributors might optimize for measurable attribution metrics rather than actual knowledge quality. Governance structures could become politicized. Economic extraction could simply reappear in new forms under decentralized branding.
Blockchain history offers many warnings here.
Narratives around decentralization often collide with realities of concentration, poor incentives, weak governance participation, and speculative excess. Infrastructure alone does not guarantee equitable outcomes. Sometimes it merely changes who captures value.
OpenLedger therefore faces a challenge larger than technology itself: building credible coordination mechanisms that produce genuine long-term utility rather than temporary financial activity.
Execution matters more than narrative.
And infrastructure projects are notoriously difficult because their success depends on ecosystems emerging around them. The market rarely rewards infrastructure immediately. Early internet protocols looked boring compared to consumer applications. Cloud infrastructure initially seemed less exciting than social platforms. Payment rails mattered profoundly despite being mostly invisible to users.
If OpenLedger succeeds in any meaningful sense, it will likely happen quietly at first.
Developers integrating attribution systems.
AI agents using standardized economic rails.
Data providers participating in reward structures.
Models interoperating across ecosystems.
Communities experimenting with shared ownership structures.
These are slow-moving coordination processes, not viral moments.
The project’s Ethereum compatibility is also strategically significant. Rather than isolating itself as a completely separate ecosystem, OpenLedger appears to recognize that future AI economies will likely require interoperability with existing crypto infrastructure. Wallets, smart contracts, Layer-2 systems, and decentralized financial primitives already form an emerging coordination layer for programmable assets.
Reducing friction matters because infrastructure adoption often depends less on theoretical superiority and more on integration simplicity.
Systems survive when they plug into existing behavior patterns.
That may sound mundane compared to grand visions about decentralized AI, but historically it is exactly how foundational technologies spread.
Still, skepticism remains necessary.
One of the uncomfortable realities of AI development is that centralized systems currently possess enormous structural advantages. Frontier model training requires vast compute resources, elite research talent, proprietary optimization techniques, and massive capital expenditures. Open ecosystems may struggle to compete directly with tightly integrated corporate AI stacks optimized at industrial scale.
Decentralized AI infrastructure therefore may not replace centralized AI so much as complement or constrain it.
That distinction matters.
OpenLedger may ultimately become valuable not because it outperforms centralized providers in raw intelligence generation, but because it offers alternative ownership and coordination mechanisms around AI activity itself. In other words, the ownership layer may become more important than the compute layer over time.
This possibility is frequently overlooked.
As AI capabilities commoditize, differentiation may increasingly shift toward trust, provenance, economic participation, and interoperability. Users may care less about marginal benchmark improvements and more about whether systems are transparent, composable, and economically aligned with contributors.
The future internet could evolve into a hybrid structure where centralized intelligence engines coexist with decentralized ownership and settlement frameworks.
OpenLedger seems positioned around that possibility.
And there is a deeper philosophical dimension underneath all of this.
For decades, the internet primarily monetized attention. Platforms competed to capture engagement, aggregate user behavior, and sell targeted access. AI changes the equation because human activity itself becomes training substrate for machine cognition. The economy is no longer just harvesting clicks. It is harvesting intelligence signals.
That transformation alters the relationship between people and digital systems.
Human expression becomes economically productive in new ways.
Communities become training environments.
Behavior becomes model refinement.
Knowledge becomes infrastructure.
At some point, societies may demand systems that account for these contributions more transparently.
Not necessarily out of idealism, but because the scale of AI-driven value extraction could become politically and economically difficult to ignore.
OpenLedger exists inside that emerging tension.
It is attempting to create infrastructure where intelligence production becomes economically legible — where participation, attribution, and ownership are programmable rather than invisible. Whether blockchain technology is ultimately the correct substrate for this remains uncertain. Whether decentralized governance can effectively coordinate such systems remains uncertain. Whether contributors truly receive fairer outcomes remains uncertain.
There are many ways this could fail.
But the questions being asked are increasingly unavoidable.
Who owns machine-generated value?
Who participates in AI economies?
How should attribution work?
What does digital labor mean when humans and machines continuously collaborate?
What becomes of ownership when intelligence itself becomes modular, programmable, and autonomous?
These are no longer fringe crypto questions. They are emerging economic questions for the internet itself.
And perhaps that is the most important way to understand OpenLedger.
Not as a token.
Not as another speculative Layer-1.
Not even primarily as an AI product.
But as part of a broader attempt to redesign the invisible accounting systems beneath future intelligence economies.
Because eventually, AI will not just generate content or automate workflows. It will participate continuously in markets, governance systems, financial coordination, research, media production, and online labor structures. The internet may slowly evolve from a network of websites into a network of interacting intelligences.
If that happens, the infrastructure governing attribution and ownership could become extraordinarily important.
The systems built now may quietly determine who captures value later.
Most people still underestimate this shift.
And honestly, nobody fully knows where it leads.
