

I spent more time than I expected untangling these two concepts because the surface level similarity between them made it easy to assume they were solving the same problem.
They're not. And understanding why they're not is probably the clearest way into what OpenLedger is actually trying to build at its technical core.
Retrieval Augmented Generation, RAG, is a technique for improving AI model outputs by pulling relevant information from external sources at inference time. Instead of relying purely on what the model learned during training, a RAG system retrieves documents, data points, or context from a knowledge base and hands them to the model alongside the user's query. The attribution part refers to tracking which retrieved sources influenced which parts of the output. If the model says something, RAG attribution can tell you which document it pulled that from.
That's useful. It's also a fundamentally different problem from what OpenLedger's Proof of Attribution is designed to address.
OpenLedger's PoA isn't concerned with what sources influenced a model's output at inference time. It's concerned with what data was used to train the model in the first place. These two questions sound related because they both involve the word attribution, but they operate at completely different points in the AI pipeline and require completely different technical solutions.

Training attribution is harder than inference attribution in almost every meaningful way. At inference time, the retrieval step is explicit and observable. You can log what was retrieved because the retrieval happens as part of the process you're running. At training time, the relationship between a specific piece of training data and the model's eventual behavior is statistical, distributed across millions of parameters, and deeply non-linear. A model trained on a particular dataset doesn't contain that dataset. It contains a compressed, transformed representation of patterns the dataset contributed to, mixed inseparably with patterns from every other piece of training data.
Proving that a specific contributor's data influenced a specific model capability in a way that's verifiable on a blockchain is not a solved problem. I want to be direct about that because the framing around Proof of Attribution can imply more technical certainty than the current state of the research supports. The cryptographic and statistical methods for establishing training data provenance are active areas of research, not settled infrastructure. Projects working in this space are making real progress, but they're also making claims that run ahead of what's been formally verified.
What OpenLedger's PoA is attempting is a practical approximation rather than a mathematically perfect proof. The system tracks data contributions, records them on chain, and creates an auditable history of what entered the training pipeline. Whether that history can be reliably connected to specific model behaviors is the harder question, and one that the architecture addresses with varying degrees of rigor depending on which part of the system you're looking at.
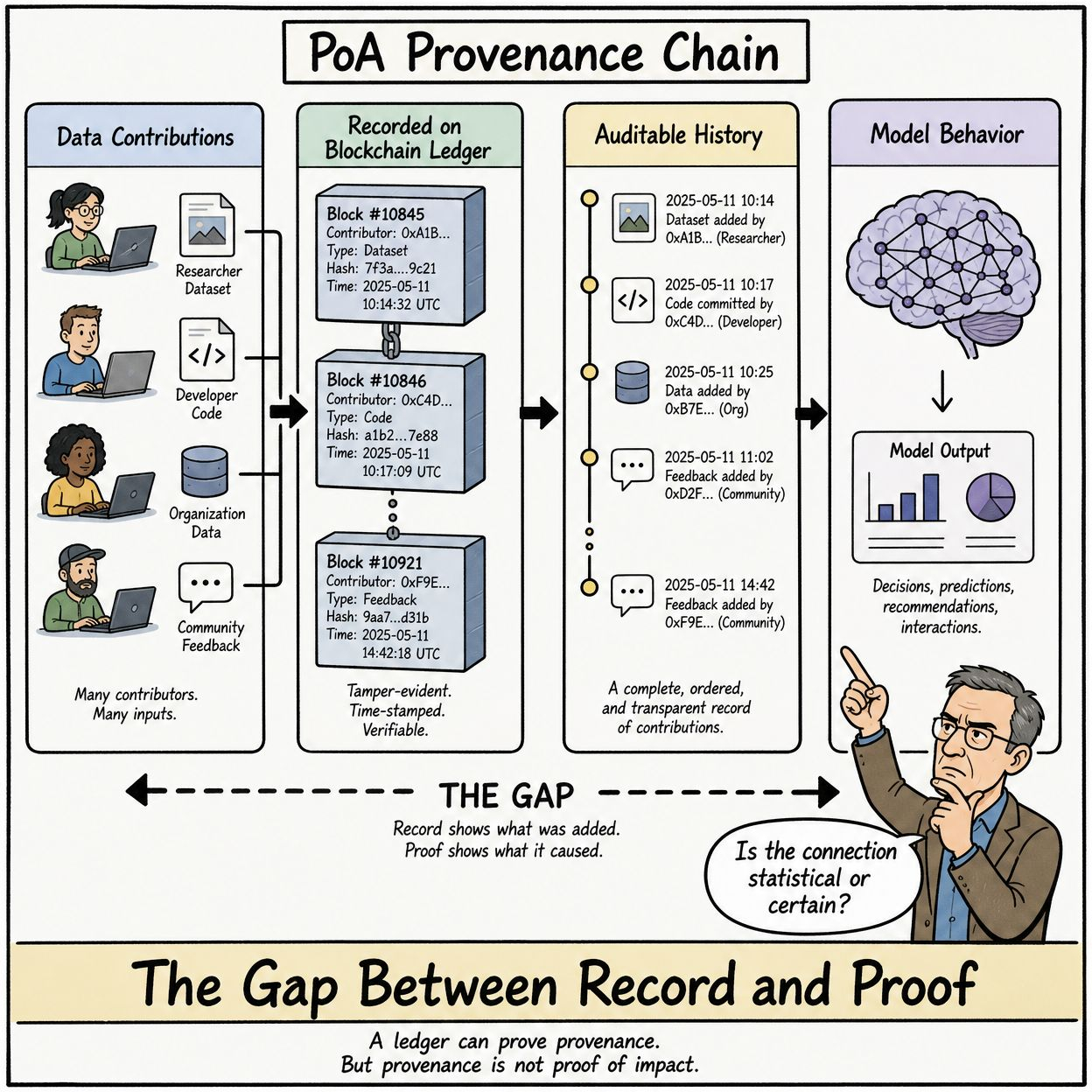
The RAG attribution comparison matters because it sets expectations. If someone comes to OpenLedger expecting the same kind of clear source-to-output traceability that a RAG system provides, they're going to find the PoA system less precise than they anticipated. The provenance chain for training data is inherently murkier than the retrieval chain for inference context. That's not a failure of OpenLedger's design. It's a property of the underlying problem.
What PoA does well is create accountability at the data contribution layer. Contributors have a verifiable record of what they provided and when. Compensation can be tied to that record in ways that don't require trusting the platform's word. That's genuinely valuable even if the connection between contribution and model outcome is probabilistic rather than deterministic.
I find the distinction between what PoA claims and what it can currently prove more interesting than most coverage suggests.
The gap between those two things is where the real technical work is happening. And where the most important questions still don't have clean answers.

