
前几天我表哥收到一封邮件。
一家医疗平台通知她:为了优化 AI 健康服务,他说的体检记录、问诊内容、用药历史,会共享给其他 AI 训练平台。
最离谱的是下面还有一句小字:
“如无异议,14 天后默认同意。”
他气到直接打电话骂我:“现在连我的病历都能随便拿去喂 AI 了?”
但更现实的是他根本没办法阻止。因为在现在的大部分互联网平台里,数据一旦交出去,基本就不算你的了。平台赚钱。AI 模型变强。用户承担隐私风险。最后真正提供数据的人,什么都没有。
这也是我最近开始认真研究 OpenLedger(OPEN)的原因。
因为它做的事情,其实挺直接:
既然 AI 这么需要数据,为什么数据提供者不能赚钱?
OPEN 想干的事,其实就一句话:
把“被平台白拿的数据”,变成“用户自己的资产”
现在很多 AI 项目天天喊“数据很重要”。
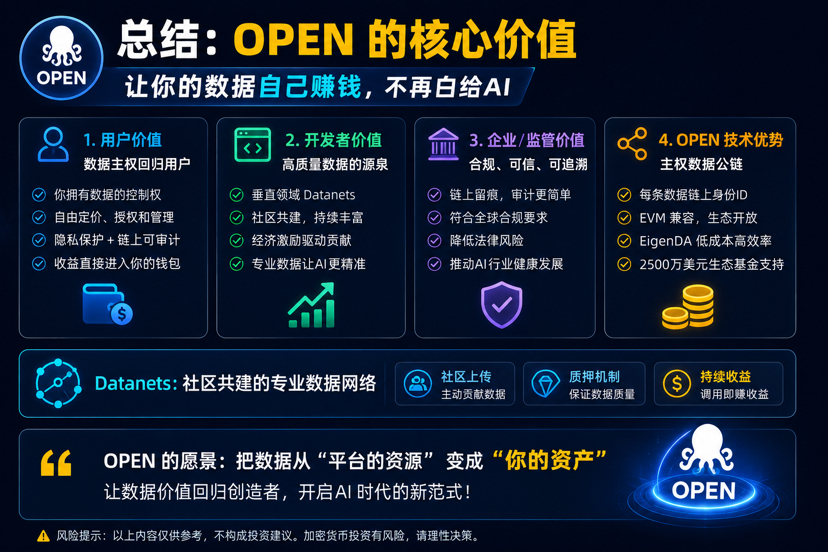
但问题是:数据到底是谁提供的?是普通用户。是医生。是程序员。是创作者。是每天在互联网留下行为的人。结果 AI 公司越来越值钱,真正提供数据的人却一直免费打工。OPEN 想改这个规则。它本质上是一条“主权数据公链”。
什么意思?
简单说:你的数据不再默认属于平台。而是属于你自己。谁能调用、调用多久、付多少钱,全部由你决定。每一次数据被 AI 使用,链上都会留下记录,收益直接进钱包。
以前互联网的逻辑是:
用户贡献数据 → 平台垄断数据 → AI 公司赚钱
OPEN 想改成:
用户拥有数据 → AI 付费调用 → 收益回到数据提供者
这其实不是“小改良”。而是想重新定义 AI 时代的数据归属。
为什么最近这个方向突然开始变重要了?
因为 AI 发展太快了。但数据合规的问题,也开始越来越吓人。
V神前段时间就专门提醒过:
未来最大的风险之一,可能不是 AI 不够强,而是 AI 拿了太多用户隐私。欧盟 AI 法案今年也开始推进,很多企业现在已经不敢像以前那样随便抓数据训练模型了。
因为接下来最麻烦的问题会变成:
“这些数据到底从哪里来的?”
如果来源不清楚,授权不清楚,未来 AI 出问题,企业可能真的会吃官司。
所以现在很多项目开始意识到:
未来最值钱的,不一定是模型。
而是:
“合法、可追溯、可授权的数据来源。”
OPEN 卡的就是这个位置。
我觉得 OPEN 最有意思的,其实是 Datanets
这是它里面最核心的设计之一。
你可以把 Datanets 理解成:
“社区一起搭建的专业数据网络”
比如 Solidity 安全审计这个方向。社区已经整理了超过 15 万个漏洞样本,还做了分类、版本标注。
重点是:
这些数据不是公司花钱硬收集的。而是开发者自己主动上传。因为上传数据,可以持续赚钱。
有人分享过:
上传 DeFi 清算历史数据后,三个月被动收入超过 1 万美元。我看到这里的时候其实挺震撼的。
因为这意味着:
程序员第一次开始真正拥有“数据版权收益”。
以前开发者分享经验,平台赚流量。现在是别人调用你的数据,你持续拿钱。这个逻辑变化,其实很大。
那数据质量怎么保证?
OPEN 的做法挺 Web3。上传数据之前,要先质押 OPEN。如果数据质量差,被社区标记,或者审核不过,质押可能直接没了。
说白了:
想灌水?先赌自己的钱。
这个机制反而比很多传统平台更狠。
因为传统互联网审核烂数据,很多时候平台自己也懒得管。
但在 OPEN 这里:
数据垃圾 = 你自己亏钱。
我为什么会继续关注 OPEN?
因为我越来越觉得:
AI 下一阶段拼的,可能已经不是“谁模型更大”。
而是:
谁拥有真正高质量、合法、可持续的数据。
过去互联网最大的商业模式之一,就是:
免费拿用户数据,然后平台独占收益。但 AI 出现以后,这件事开始越来越敏感了。因为现在的数据价值,比以前高太多了。
而 OPEN 想做的事情,本质上就是:
把数据收益权重新还给用户。
当然,它也不是没风险。数据所有权、法律认定、链上证据这些问题,未来一定还会继续争议。但至少它切中的,是一个越来越真实的问题:
AI 公司越来越赚钱。
可真正“喂养 AI”的那群人,为什么一直拿不到钱?
这件事,我觉得值得继续看下去。
@OpenLedger $OPEN ##OpenLedger
(以上内容仅为个人研究与观点分享,不构成投资建议。)