while scanning the attribution layer last night
While pulling up the OpenLedger explorer just to cross-check something minor, I ended up staying much longer than intended. That happens sometimes — you go in for one number and come out an hour later holding a different question. #OpenLedger , $OPEN, @OpenLedger _AI — the project markets itself around something that genuinely matters: making AI data attribution real, on-chain, and economically meaningful. The pitch is clean. Proof of Attribution, Datanets, a full lineage trail for every dataset that touches a model. In an environment where AI training is increasingly litigated and regulated, the structural case almost writes itself.
But the piece that stayed with me wasn't the architecture.
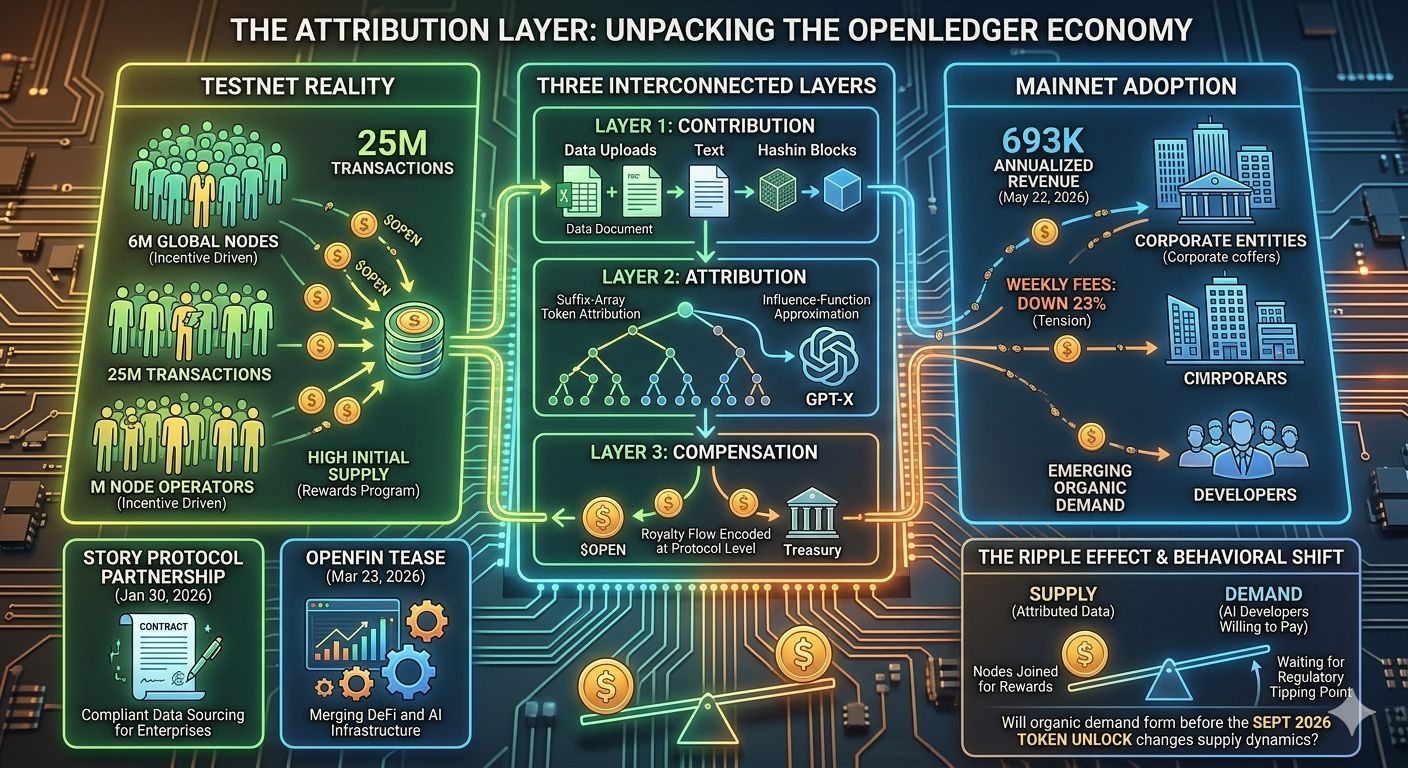
It was two numbers sitting next to each other on DefiLlama. Annualized protocol revenue: $693K. Weekly fees: down 23%. Verifiable at defillama.com/protocol/openledger, checked May 22, 2026. Not catastrophic. Not even surprising — the mainnet only launched in November 2025. But those numbers sit in uncomfortable tension with the testnet's headline figures: 25 million transactions, 6 million nodes, 20,000+ models deployed during the incentivized period. Two very different signal types. That contrast is what I couldn't let go.
the contrast that didn't leave quietly
I remember the first time I mapped out how the incentive structure was supposed to work. Data contributor uploads a dataset. It gets hashed, attributed, logged on-chain. A model developer pulls it during training. The Proof of Attribution mechanism traces that influence — suffix-array token attribution for LLMs, influence-function approximations for smaller models — and routes $OPEN back to the original contributor automatically. It's actually elegant. Think of it like a royalty flow encoded at protocol level, except instead of music rights it's the training signal behind an AI response.
That's the framework. Three interconnected layers: contribution, attribution, compensation. Theoretically self-sustaining once demand is consistent.
The practical observation, though, is that testnet participation was largely incentive-driven. Nodes joined because there were rewards, not because an AI developer urgently needed their dataset. That's a categorically different kind of activity. And the transition from "who shows up for rewards" to "who shows up because the market needs their data" is exactly where attribution-based models find their hardest stretch. It's not a flaw in the design. It's just the nature of building a two-sided market on a chain.
hmm... the demand-side problem
Two market examples I kept thinking about. First, the Story Protocol partnership from January 30, 2026 — OpenLedger and Story created a joint standard enabling legal AI training with automatic payments to rights holders. That's a real use case with real urgency. AI training data lawsuits are mounting globally, and enterprises are actively looking for compliant data sourcing solutions. The demand case isn't theoretical here.
Second, the OpenFin tease from March 23, 2026 — the team described it as bringing "DeFAI" closer, merging decentralized finance logic with AI infrastructure. Details were scarce, but it suggests a demand expansion beyond the current contributor base. If OpenFin materializes with meaningful on-chain activity, the token's utility footprint grows considerably.
But here's where my skepticism doesn't stay quiet. Revenue at $693K annualized, fees falling 23% in the most recent tracked week — this tells me the demand side of the attribution economy is still forming. The supply of attributed data is growing. The proven pull from AI developers willing to pay in OPEN for verified, lineage-tracked datasets is harder to see clearly in the numbers. That might be timeline. Or it might be a structural question about whether AI developers prioritize legal attribution enough to actually change sourcing behavior at the protocol level. Actually — I'm not sure which of those it is. That uncertainty feels honest to sit with.
still sitting with the ripple
The deeper thing here is what reshaping AI data economics actually requires. It's not just a provenance layer going live. It's a behavioral shift in how AI developers source, pay for, and account for training data. OpenLedger has built the rails. The attribution system is live on mainnet. The lineage logging is real. But reshaping an economic system requires both sides of a market to move — and right now, the supply side is considerably further along than the demand side.
I keep thinking about how long comparable attribution models took to reach traction in adjacent spaces. Music royalty infrastructure, API marketplaces, open-source bounty systems — all had the plumbing before the behavioral adoption. The rails get built quietly, then something regulatory, or a high-profile lawsuit settlement, or a single large enterprise procurement decision tips the balance and demand floods in.
The economic model being proposed — data as a traceable, compensated input rather than silently consumed raw material — is directionally correct for where AI regulation is heading. That part I feel more settled on than I expected after this session. The question isn't whether that future exists. It's whether OpenLedger is the infrastructure running beneath it, or one of several early attempts that informed whatever ultimately wins.
That distinction doesn't live in the whitepaper. It lives in whether AI developers start paying meaningfully for attributed datasets before the September 2026 team unlock changes the supply dynamics of $OPEN — and whether $693K in annualized revenue starts moving before the narrative needs it to.
What does organic demand for attributed AI data actually look like on-chain, and how far are we from being able to measure it clearly?