The AI industry has spent the last few years acting like a hedge fund with a GPU addiction. Bigger models. Bigger clusters. Bigger burn rates. Every quarterly milestone reduced to parameter counts and benchmark screenshots posted like flex culture for infrastructure nerds. And for a while, fair enough, brute force actually worked. Throw enough compute at the wall and the systems got smarter.
But underneath all that noise, there was a problem nobody wanted to touch because it was messy, expensive, and politically radioactive: nobody built a functioning accounting system for the data feeding these models.
That’s starting to look less like an oversight and more like the original sin of the entire AI stack.
Look at how modern models are actually made. They are stitched together from an absurd amount of human output: research papers, GitHub repos, support tickets, medical annotations, niche forum discussions, internal enterprise documents, moderation feedback, edge-case corrections, labeling work, behavioral telemetry, and millions of tiny invisible human interventions spread across the internet. Entire industries are quietly embedded inside these systems.
Then the training run happens and all of that labor gets liquefied into weights.
The model company captures the upside. The contributors disappear into the fog.
That arrangement was easy to ignore when AI still felt experimental — a glorified research project with venture capital underneath it. Harder to justify once these systems start replacing workflows, generating enterprise revenue, and becoming infrastructure companies disguised as model labs.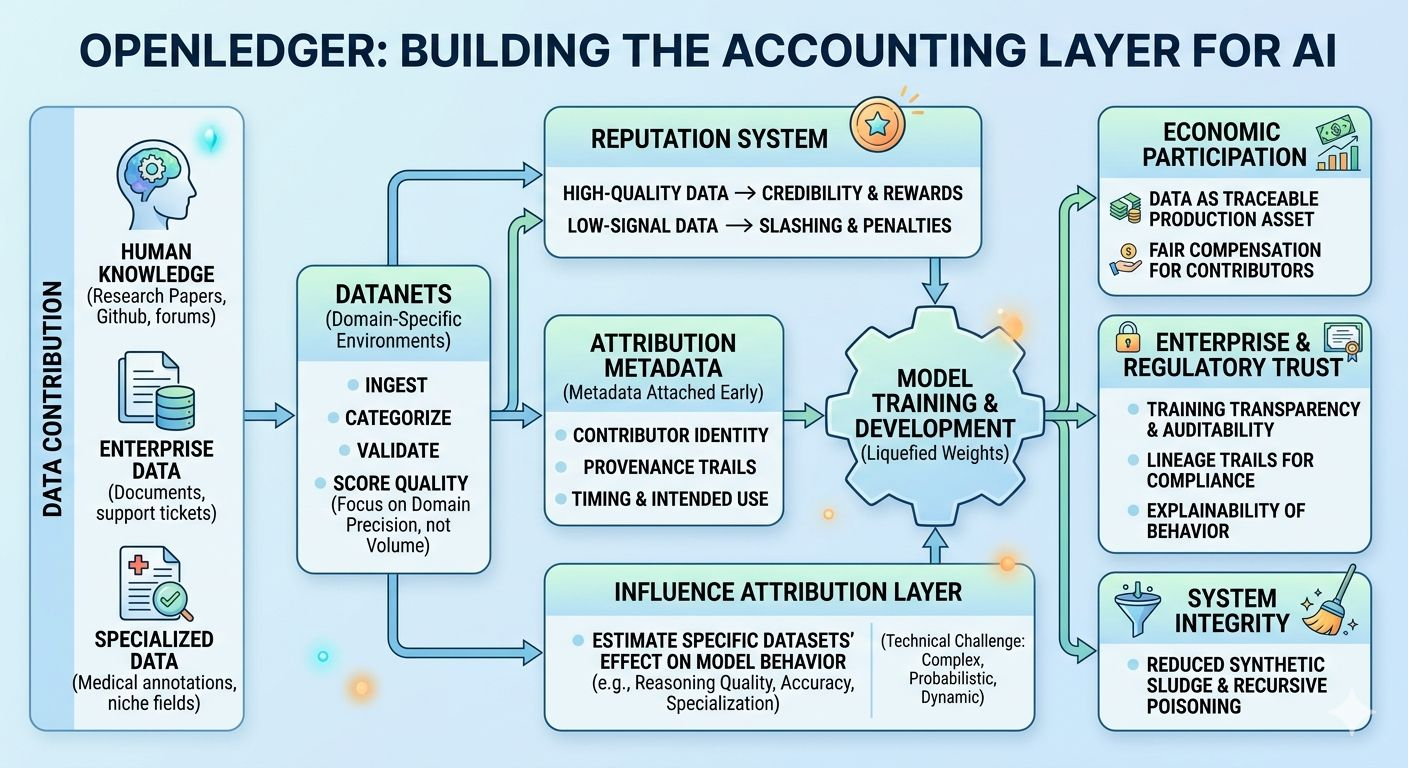
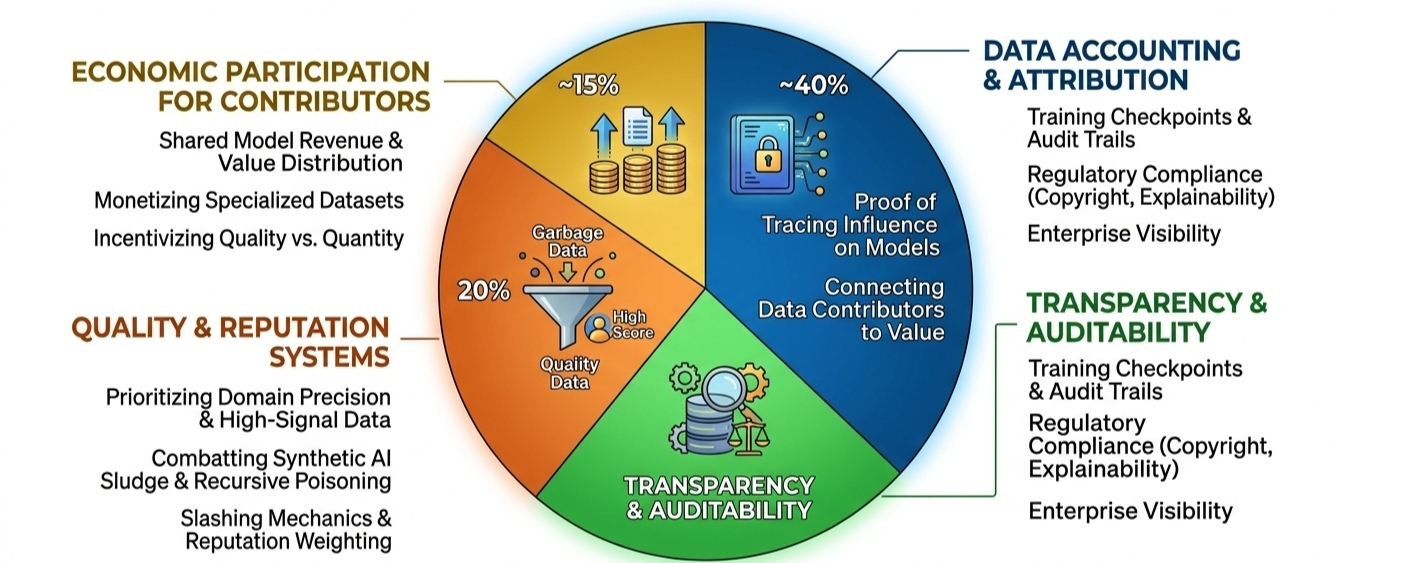
Most “AI x crypto” projects are basically wrappers. GPU marketplaces with a governance token attached. Inference APIs pretending to be decentralized because they pushed a hash on-chain somewhere. Cosmetic decentralization. OpenLedger is aiming at something much uglier and much harder — figuring out how to measure who actually contributed value to a model in the first place.
That’s the real fight.
The industry talks endlessly about scaling laws, inference efficiency, synthetic data, agent frameworks. Fine. But the economic layer underneath all of this is still incredibly primitive. AI currently behaves like a giant extraction engine with almost no visibility into where intelligence came from or who materially improved it.
OpenLedger’s answer is its Proof of Attribution framework, which sounds like standard crypto branding until you look closer at what it’s trying to solve.
The hard part isn’t putting records on-chain. Any competent engineer can store hashes. The nightmare is attribution granularity. Once datasets get blended into massive distributed training runs, tracing influence becomes brutal. Model behavior emerges from probabilistic relationships spread across billions of parameters. There’s no neat one-to-one mapping where Dataset A produced Capability B.
Which is exactly why most companies avoid the problem entirely.
It’s computationally ugly. Economically inconvenient too.
Because the second you can reliably measure contribution, you also create pressure around compensation, ownership, licensing, and auditability. Suddenly the black box starts generating receipts.
OpenLedger’s architecture starts earlier in the pipeline with something called Datanets — domain-specific environments where datasets are ingested, categorized, validated, benchmarked, and scored according to usefulness inside a particular training context.
That distinction matters more than people think.
Anyone who has spent time around production AI systems already knows the dirty secret here: volume is overrated. The internet is full of garbage data. Duplicate text. SEO sludge. Low-signal synthetic filler. Bad labeling. Contaminated outputs. Redundant corpora masquerading as scale.
A narrow, high-quality dataset with strong domain precision can improve a system more than another few terabytes of scraped internet waste. Especially in enterprise copilots, retrieval systems, legal workflows, or vertical-specific agents where accuracy matters more than internet-scale breadth.
Most real bottlenecks in AI aren’t “not enough data.” They’re bad data. Or irrelevant data. Or polluted data.
OpenLedger seems to understand that. Which already puts it ahead of a surprising amount of the market.
Once information enters the system, attribution metadata gets attached immediately — contributor identity, timing, dataset type, intended use case, provenance trails. Basically an attempt to stop lineage from disintegrating the second data moves through preprocessing and training pipelines.
And honestly, the timing here makes sense.
Regulators are already circling around training transparency, copyright exposure, explainability, and synthetic contamination. Enterprises are asking harder questions too. Where did this model learn this behavior? What datasets touched it? Can the outputs be audited? Was copyrighted material involved? Was the training environment poisoned with recursive AI garbage?
Most current systems have terrible answers for that because they were optimized for speed, not traceability.
The influence attribution layer is where things get genuinely ambitious.
This is the part where OpenLedger tries to estimate how much specific datasets actually affected downstream model behavior — reasoning quality, contextual accuracy, reliability, specialization, output consistency, that sort of thing.
Easy to describe. Horrible to implement.
Influence attribution in machine learning turns into a systems nightmare the second you leave whitepaper territory. Distributed training dynamics are messy. Statistical relationships overlap. Gradient interactions become opaque fast. And once you’re operating at production scale, the complexity explodes.
So this is the fork in the road for the project.
Either they crack a meaningful piece of the attribution problem and become genuinely important infrastructure — or the whole thing collapses under the weight of computational reality. There probably isn’t much middle ground.
Still, the direction itself feels inevitable.
AI systems already rely heavily on ranking systems, reinforcement loops, evaluation frameworks, confidence scoring, and retrieval weighting. Extending that logic toward contributor accounting isn’t some alien concept. It’s a natural progression of the stack.
The reputation system layered on top is arguably even more important.
Because decentralized data ecosystems rot fast when incentives are tied purely to throughput. We’ve already watched this movie with SEO spam, engagement farming, fake traffic, clickbait arbitrage, and content mills. The second rewards scale with quantity instead of signal quality, the system fills with trash.
AI makes this worse because synthetic generation lowers the cost of spam to near zero.
The internet is already flooding with recursive AI-generated content — models training on outputs generated by earlier models, feedback loops amplifying statistical noise into synthetic sludge. Without aggressive filtering and reputation weighting, future training environments risk becoming self-referential garbage heaps where systems slowly poison themselves.
OpenLedger’s slashing and reputation mechanics look designed specifically around that threat model. High-quality contributors accumulate credibility and stronger economic participation over time. Low-signal or manipulative contributions get penalized.
Which, frankly, feels less like optional governance theater and more like survival infrastructure.
Another overlooked piece is training transparency. The framework records checkpoints, validation states, attribution metrics, and audit trails during development.
That probably sounds boring until you realize how much of the current AI economy runs on pure trust.
Most enterprises using frontier models have very little visibility into how those systems were trained or what influenced them. Regulators know even less. And as these systems move deeper into healthcare, finance, legal automation, defense, and public infrastructure, that opacity becomes a serious liability.
Explainability stops being an academic discussion once decisions start carrying legal or economic consequences.
At that point attribution systems stop looking like crypto experiments and start looking like compliance infrastructure.
The economic implications are where things get especially interesting though.
OpenLedger is effectively trying to turn data into a traceable production asset instead of invisible raw material. The goal is straightforward: contributors whose datasets materially improve models should participate economically in the value those systems generate.
If that works even partially, the incentives around AI development shift pretty dramatically.
Specialized researchers could monetize niche datasets without disappearing behind platform walls. Enterprises could contribute proprietary information into permissioned systems while maintaining attribution trails. Domain-specific communities could collectively train models with transparent contribution accounting attached to them.
And maybe most importantly, quality suddenly matters economically.
Right now the AI industry behaves like intelligence magically emerges from compute expenditure alone. But that story gets weaker the closer you inspect the supply chain. These systems are built on distributed human knowledge at massive scale. Eventually the people supplying that knowledge are going to demand visibility into where the value went.
That pressure is coming whether the industry likes it or not.
The market is still obsessed with model rankings because leaderboards are easy. People understand benchmarks. They understand parameter counts. They understand demos.
The harder question sits underneath all of it:
Who owns the economic graph behind machine intelligence?
That’s the layer OpenLedger is trying to build. Not another chatbot. Not another inference wrapper pretending to be infrastructure. An accounting and settlement layer for the data economy underneath AI itself.
Whether they can actually execute is still unresolved. The technical challenges here are brutal — attribution scaling, verification integrity, adversarial manipulation, computational overhead, incentive design. None of this is solved.
But the direction is probably right.
Because at some point AI stops being just a model problem.
It becomes a provenance problem.


