

been thinking about OpenLedger’s “transparent AI” angle, and honestly, the interesting part is not just that it puts AI onchain.
That line is too easy.
A lot of projects say “AI + blockchain” and then the actual design turns into a token layer around something mostly normal. A marketplace. A compute wrapper. A reward campaign. Maybe a dashboard with some model activity. Useful sometimes, but not really a new accountability layer.
OpenLedger’s more interesting claim is different: it wants attribution to sit inside the AI lifecycle itself.
That matters because machine learning has a quiet ownership problem. Models do not appear from nowhere.
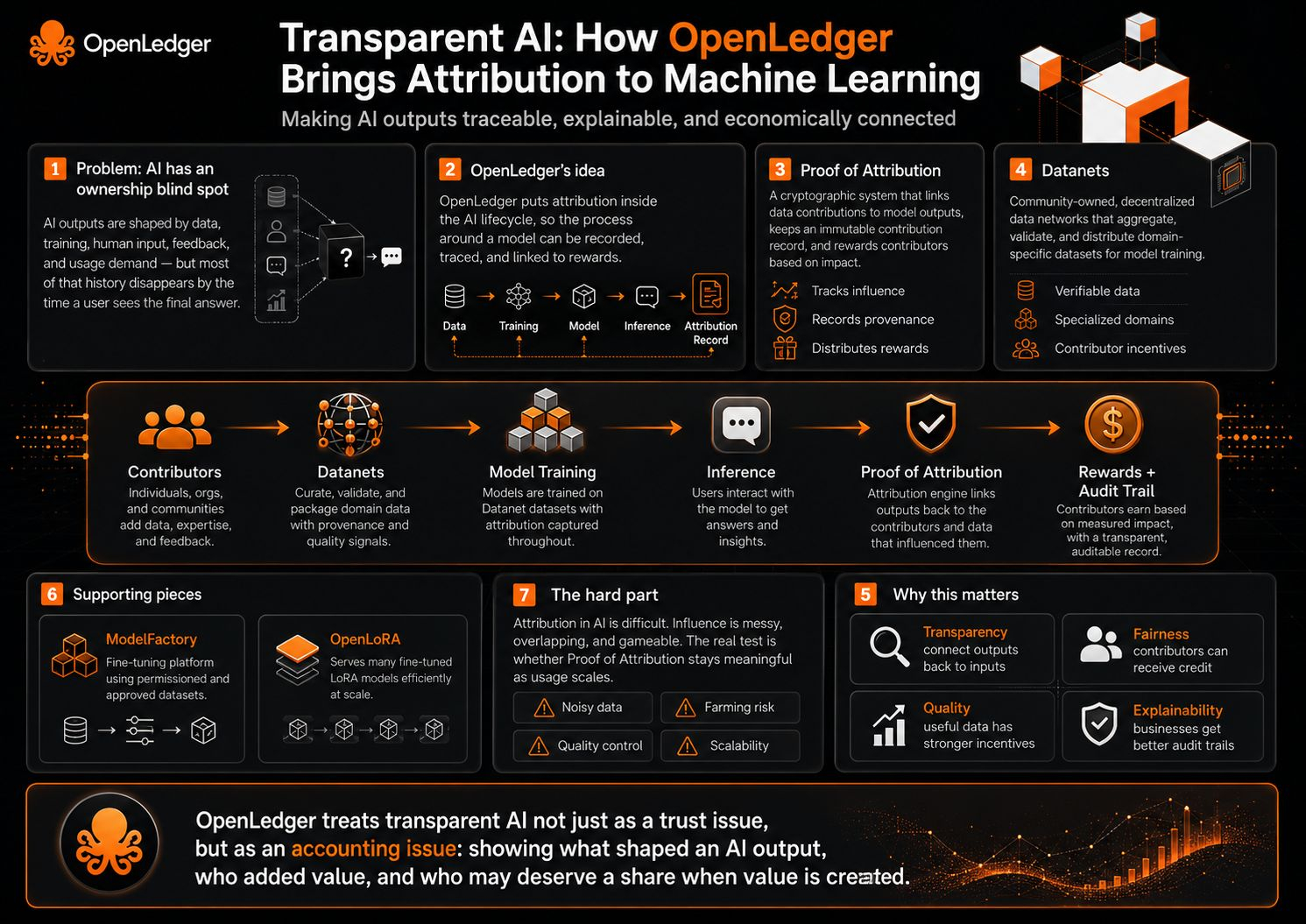
AI responses are shaped by many things — data, training, human input, feedback, and demand from users. The problem is, when someone sees the final result, they usually do not know who or what helped create it.The output arrives clean. The trail behind it disappears.
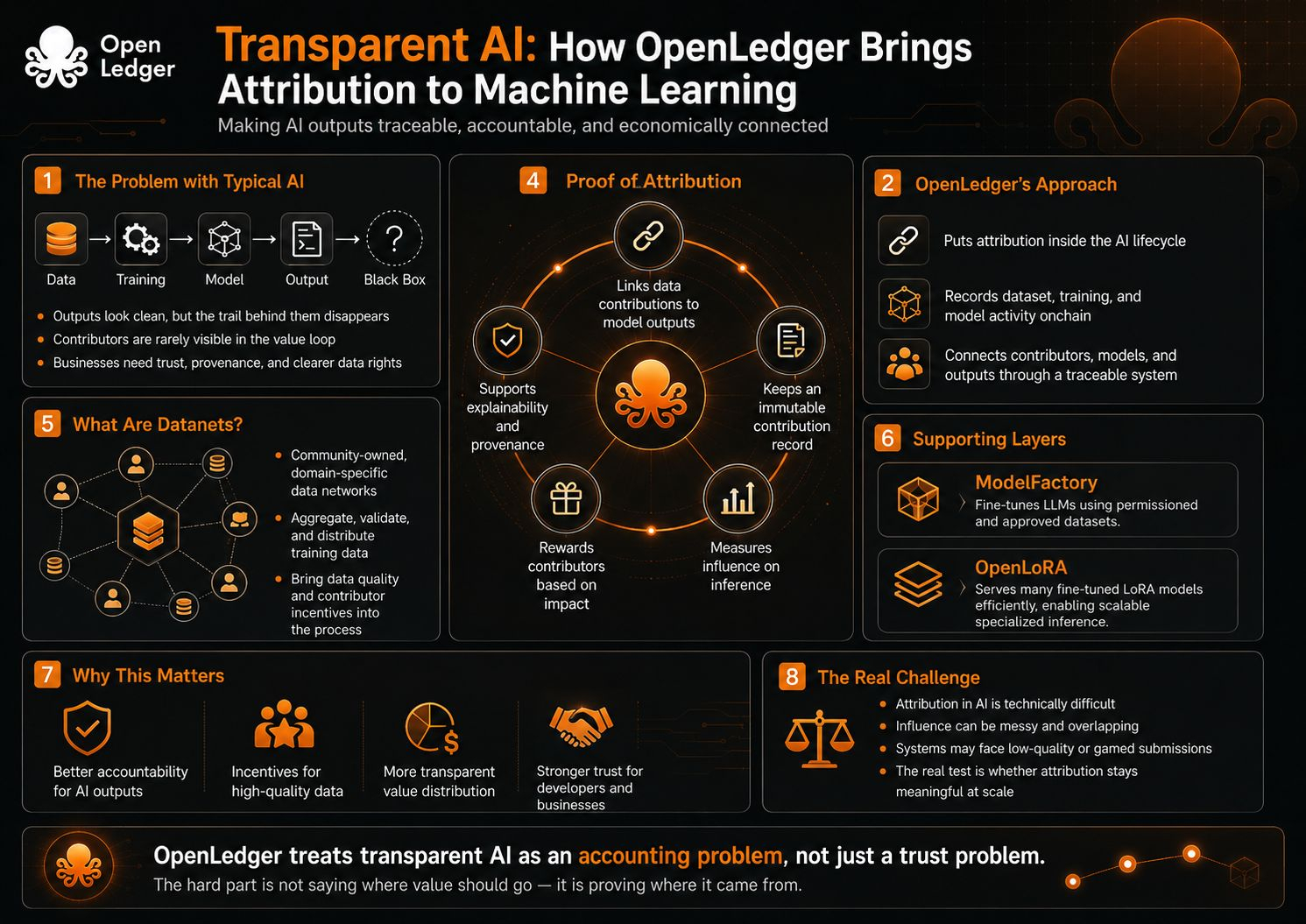
OpenLedger is trying to make that trail visible.
Its docs describe OpenLedger as AI-blockchain infrastructure for training and deploying specialized models using community-owned Datanets, with dataset uploads, model training, reward credits, and governance participation executed onchain. That framing is important because it is not only saying “use our AI model.” It is saying the process around the model should be recorded, traced, and economically connected.
what caught my attention:
Proof of Attribution is the core mechanism here. OpenLedger’s docs describe it as a cryptographic system that links data contributions to AI model outputs, keeps an immutable record of contributions, and rewards contributors based on the impact of their data. In plain words, the model does not just answer. The system tries to show which inputs helped shape that answer, and who should receive credit for that influence.
That sounds simple until you compare it to how AI usually works.
In the normal AI economy, value flows upward. Data gets collected. Models are trained. Products are built. Users pay. Contributors, if they are even visible, usually sit outside the money loop. Their work becomes part of the machine, but the machine does not remember them in any useful economic way.
OpenLedger is basically asking: what if the machine had memory?
Not emotional memory. Attribution memory.
The Datanets piece makes this clearer. OpenLedger describes Datanets as decentralized data networks that aggregate, validate, and distribute domain-specific datasets for AI model training. Contributors provide high-quality data with verifiable attribution, and the system is meant to make data credibility and contributor incentives part of the training process rather than an afterthought.
That is where “transparent AI” becomes more than a slogan.
Transparency here is not only about telling users that a model exists. It is about connecting the output back to the ingredients. Which dataset mattered? Which contributor added value? Which model or adapter was used? Was the data useful, redundant, biased, or low quality? OpenLedger’s attribution pipeline even describes influence scoring, training logs, reward distribution based on impact, and penalties for malicious or low-quality contributions.
the part I keep coming back to:
This is not just a fairness mechanism. It is also a quality mechanism.
If contributors can be rewarded when their data improves inference, then useful data has a reason to surface. If weak or adversarial data can be penalized, then the system has at least some pressure against garbage inputs. That does not magically solve AI quality. Nothing does. But it creates a different incentive map from the usual “scrape everything, hide the sources, monetize the output” model.
Binance Research describes OpenLedger’s Proof of Attribution as a system that identifies the data points shaping a model’s output and rewards contributors, while also supporting explainability and provenance across the AI lifecycle. That wording is doing a lot of work. Attribution is not only about payment. It is also about being able to inspect where an answer came from
This may be the best reason why OpenLedger matters. AI is growing fast, but most of it feels like a black box. Users see the final answer, but not the data behind it. For businesses, that is a big issue because they need trust, proof, and clean data rights. Developers want better datasets, but good contributors need a reason to participate. OpenLedger’s answer is to turn inference into a traceable economic event, where data influence can be measured and rewarded instead of disappearing into the black box.
ModelFactory fits into this same direction. The docs describe it as a fine-tuning platform for LLMs under the OpenLedger ecosystem, using datasets that have been permissioned and approved through OpenLedger. That suggests the project is not only thinking about attribution after the model is built, but also about the controlled path from dataset to model creation.
OpenLoRA adds another layer. It is described as a framework for serving thousands of fine-tuned LoRA models on a single GPU, with dynamic adapter loading and efficient inference. That matters because attribution is more useful when specialized models can actually be deployed and used at scale. Otherwise, the attribution layer stays theoretical.
my concern though:
Attribution in AI is hard. Very hard.
Saying “this data influenced this output” is not the same as proving it in a way everyone will accept. Model behavior is messy. Training influence is not always obvious. Similar data points can overlap. A contribution can matter indirectly. Bad actors may try to game influence scores. And once money enters the loop, people will optimize for rewards, not purity.
So the real test for OpenLedger is not whether the idea sounds fair. It does.
The real test is whether Proof of Attribution can stay meaningful when the system gets noisy: more Datanets, more contributors, more models, more low-quality submissions, more inference demand, and more people trying to farm attribution rather than create value.
That is where I think OpenLedger becomes interesting to watch.
Because if it works, even partially, it gives AI something it badly lacks right now: a memory of contribution. Not just who built the model. Not just who owns the app. But who supplied the knowledge, who improved the output, and who deserves a share when that output creates value.
Transparent AI is usually discussed like a trust issue.
OpenLedger is treating it more like an accounting issue.
And maybe that is the more serious version. Not “trust us, this AI is transparent,” but “here is the record of what shaped it.”
watching: whether attribution stays accurate under real usage, whether contributors actually earn meaningful rewards, whether Datanets attract high-quality specialized data, and whether OpenLedger can avoid becoming another system where transparency sounds good until incentives get crowded.
because the idea is strong.
But in AI, the hard part is never saying where value should go.
The hard part is proving where it came from.
@OpenLedger #OpenLedger $OPEN $BLUAI
