
I sometimes pause and think about something that bothers me more than it probably should.
When an AI system learns something… where does that knowledge actually live ?
I don't mean technically. I mean economically. Practically. In terms of who owns it, who benefits from it, who is responsible for it when something goes wrong.
Because right now the honest answer is — nobody really knows. And the more I think about that, the more uncomfortable it becomes.
Here is where I start....
We talk about AI training like it is a clean process. Data goes in. Model improves. Better outputs come out. But that description skips over something enormous. The data that goes in came from somewhere. Someone created it. Someone owns it. Someone's labor, creativity, research, or experience is sitting inside that model producing value for someone else.
And in almost every case — they received nothing.
This is not a small problem. It is the foundational tension of the entire AI economy. And it gets worse the more capable these systems become. Because a more capable model extracts more value from its training data. Which means the gap between what contributors gave and what they received keeps widening.
I stop here and think....
Is this actually solvable ? Or is this just the nature of how information works — once shared it cannot be unshared, once learned it cannot be unlearned ?
This is exactly where OpenLedger starts looking different to me. Not because they are claiming to solve the whole problem. But because they are at least trying to make the problem visible in a way that creates economic consequences.
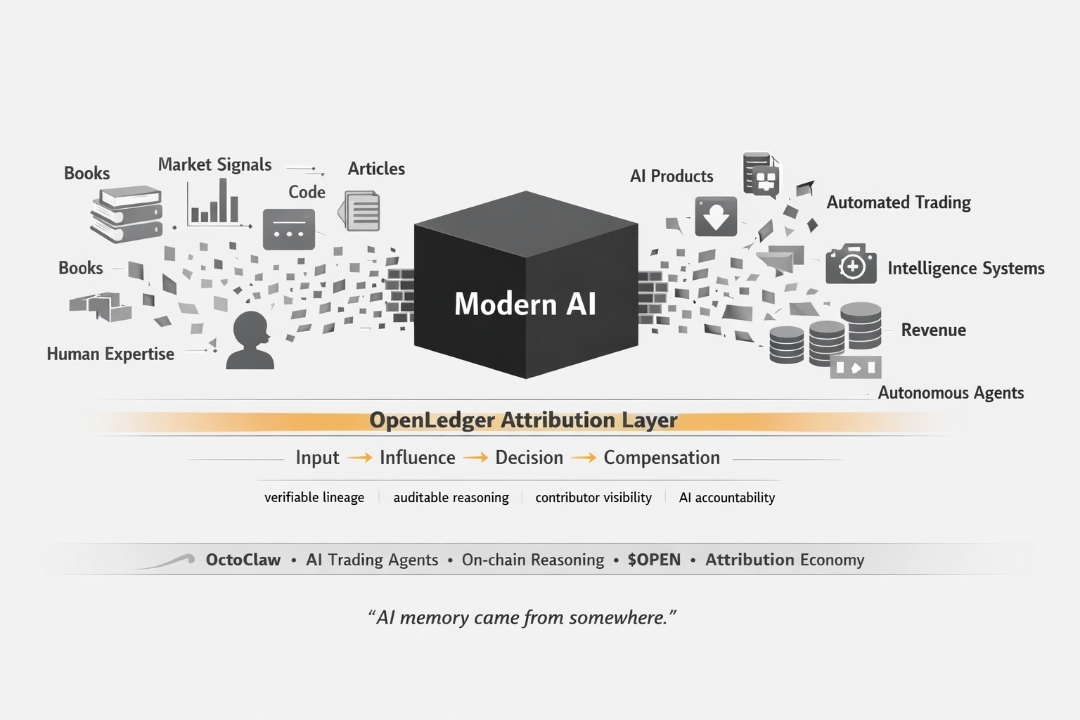
Their Proof of Attribution system — and I want to be careful here because I think people misread what this actually is — is not primarily a payment mechanism. It is a tracking mechanism. It is trying to answer a question that nobody in AI has seriously attempted to answer at the infrastructure level.
Which specific data contributed to which specific output ? And by how much ?
I find this genuinely interesting. And genuinely difficult.
Because measuring data influence in a trained model is not straightforward at all. Models don't keep ingredient lists. Training effects are diffuse. A single piece of data might influence thousands of outputs in small ways that compound over time. Trying to quantify that influence precisely enough to base economic compensation on it — that is a very hard engineering problem that I don't think is fully solved anywhere.
So I get a little stuck here....
If the attribution measurement is approximate — and it almost certainly is — then the compensation flowing from it is also approximate. Which means contributors might be systematically over or under compensated in ways that are invisible to them. And if that happens at scale, does the system actually deliver on its promise ? Or does it just create a more sophisticated version of the same extraction problem with better branding ?
I don't have a clean answer to that.
But then I look at the trading agent functionality and something shifts in how I think about this.
Because the trading agent is where attribution stops being philosophical and starts being operational. A trading agent using OpenLedger's infrastructure is making decisions based on data with a verifiable lineage. The market signals informing each trade can be traced to their contributors. The model's reasoning is on-chain rather than hidden inside a black box.
That changes the accountability structure for AI-driven finance in a way that matters right now — not in some future regulatory environment but today, as algorithmic systems manage increasingly large positions in real markets.
If a trading decision goes wrong and someone asks why the agent made that call — the answer exists. Not because someone reconstructed it after the fact. Because the infrastructure was designed to record it as it happened.

That is a genuinely different capability than anything currently available in AI-driven trading.
And the OctoClaw agent is where this becomes concrete for individual users rather than just institutional ones. Research, automation, execution — running together in one system, on-chain, in real time. Not switching between tools. Not losing the chain of custody between what data informed a decision and what the decision was.
I find myself going back and forth on this....
On one hand the infrastructure logic is clean. Attribution creates accountability. Accountability creates trust. Trust enables adoption in high-stakes environments that current AI systems cannot access because they cannot be audited.
On the other hand — and this is the part I cannot dismiss — building infrastructure that theoretically solves a problem is very different from building infrastructure that actually gets used to solve it. Enterprise adoption moves slowly. Regulatory frameworks are still forming. The organizations most likely to need verified AI attribution are also the ones most likely to build proprietary solutions rather than adopt decentralized infrastructure they don't control.
So where does that leave me ?
Somewhere in the middle. Which is probably the honest place to be.
OpenLedger is not solving the AI data problem completely. I don't think anyone is close to doing that. But they are building infrastructure that makes the problem legible in a way it wasn't before. And making a problem legible is usually the first step toward making it solvable.
Whether that first step becomes something durable — that is the question I am still sitting with.
And I don't think I will have a confident answer anytime soon.