

I want to start with something that doesn't get said often enough about AI data pipelines.
The data is almost never ready.
Every serious AI practitioner knows this. The romanticized version of machine learning involves training elegant models on clean, well-structured datasets. The actual version involves spending most of your time wrestling raw data into a format that won't break your training pipeline. Inconsistent formatting, missing fields, encoding errors, duplicate entries, labeling mistakes. The gap between data in the wild and data a language model can actually learn from is enormous, and the work of closing that gap is unglamorous, time-consuming, and consequential in ways that compound quietly across the entire training process.
OpenLedger is building infrastructure for decentralized AI data markets, which means it has to have an answer for this problem. A marketplace where contributors can submit raw, unstructured data and buyers can receive LLM-ready JSON is only as valuable as the transformation layer between those two states. That transformation is what I wanted to understand in detail.

The process starts with ingestion. Raw data arrives in whatever format the contributor has it. Text documents, scraped web content, structured databases, audio transcriptions, code repositories. The format diversity is the first challenge. A pipeline that handles clean CSV files gracefully may choke on inconsistently formatted text or mixed encoding documents. OpenLedger's ingestion layer needs to accept this diversity without losing data integrity in the process.
Parsing comes next. The system needs to identify what kind of data it's dealing with and apply the appropriate extraction logic. Unstructured text gets chunked into segments that make sense as training examples. Structured data gets normalized. Metadata gets extracted and preserved because provenance information is part of what makes OpenLedger's data valuable compared to anonymized bulk datasets with no attribution trail. This step is where a lot of data quality problems either get caught or get passed downstream to become someone else's problem.
The conversion to JSON for LLM training isn't a single standard. Different model architectures expect different input formats. Instruction-tuning datasets look different from pretraining corpora. A system claiming to produce LLM-ready JSON needs to be specific about which LLM workflows it's ready for, because ready for one is not the same as ready for all. I'd want to see OpenLedger's documentation address this with more specificity than the general framing of LLM-ready implies.
Quality filtering runs alongside or after conversion. This is where the Sybil attack problem I've written about elsewhere intersects with the data pipeline. A contributor submitting duplicate content formatted correctly as JSON passes the structural validation while still being worthless or actively harmful as training data. The pipeline needs heuristics or model-based filtering that can distinguish between structurally valid data and genuinely useful data. Those are different problems with different solutions and conflating them produces a marketplace that looks functional while delivering poor quality outputs.
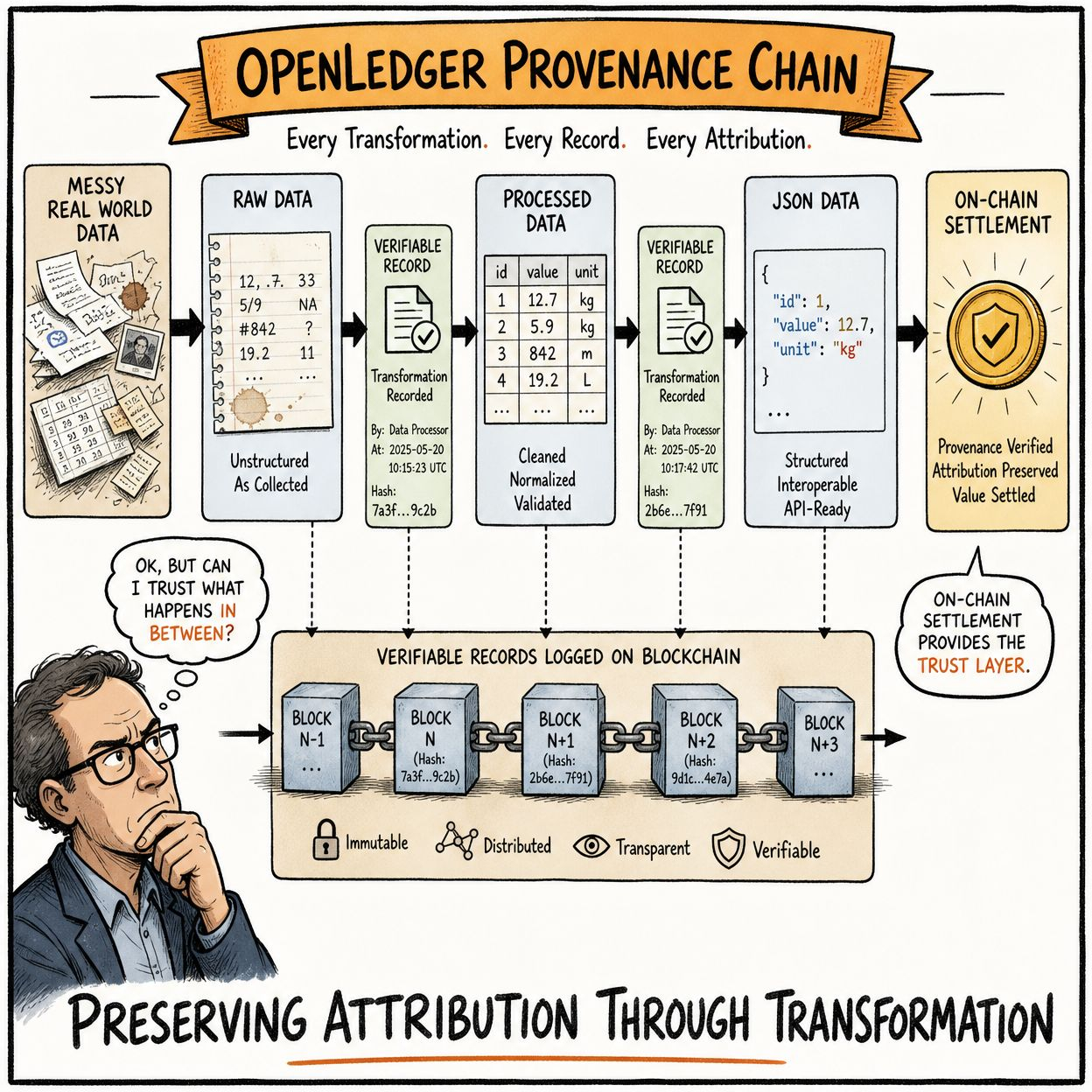
The on-chain component adds a layer that purely off-chain data pipelines don't have to worry about. Every transformation step needs to be logged in a way that preserves the attribution chain. The raw input, the processing steps applied, the resulting output, and the contributor identity all need to be connected in a verifiable record. Doing this without creating prohibitive gas costs or introducing bottlenecks that slow the pipeline down is an engineering challenge that the architecture handles through a combination of off-chain computation and on-chain settlement.
What I can say after working through the documented pipeline is that the design is more thoughtful than a surface reading suggests. The transformation from raw data to LLM-ready JSON isn't treated as a simple format conversion. It's treated as a quality and provenance problem with multiple stages.
What I can't say yet is how it performs on genuinely messy real world data at scale. Pipelines that work cleanly in documentation have a way of revealing their actual character when the inputs stop being well-behaved examples.
That test is still coming. I'm watching for it.