
For the last few years I’ve had the same uncomfortable thought whenever people talked about AI scaling
Everyone celebrates smarter models, faster inference, and larger datasets, yet almost nobody asks a simple question:
Who actually created the intelligence these systems depend on?
The modern AI economy feels strangely detached from the people who feed it. Data is collected, refined, absorbed into models, and eventually monetized at enormous scale. But once that information enters the training pipeline, individual contribution basically disappears.
That’s why OpenLedger caught my attention.
Not because it promises another AI narrative attached to blockchain, but because it focuses on something most projects avoid touching directly: attribution.
And honestly, attribution may become one of the most important infrastructure problems in AI over the next decade.
As a physics student I genuinely had a funny 🤣 moment reading the whitepaper.
To much derivation 👀.....
The second I saw those influence attribution derivations and mathematical formulations, it honestly felt like I was preparing for another exam paper again. Seeing expressions connecting loss functions, model parameters, and data influence unexpectedly reminded me of solving long derivations under exam pressure where every variable suddenly starts looking personal.
But beyond the humor, I think those derivations reveal something important. OpenLedger is not just throwing around AI buzzwords. The project is actually attempting to mathematically define how much a specific data point contributes to a model’s final output.
That level of attribution is far more ambitious than most AI projects are willing to attempt.
The Hidden Problem Inside AI
Most AI systems operate like black boxes when it comes to training influence.
A model produces an answer, but there is usually no transparent mechanism explaining:
which dataset influenced the output,
how much influence it had,
or whether contributors deserve compensation.
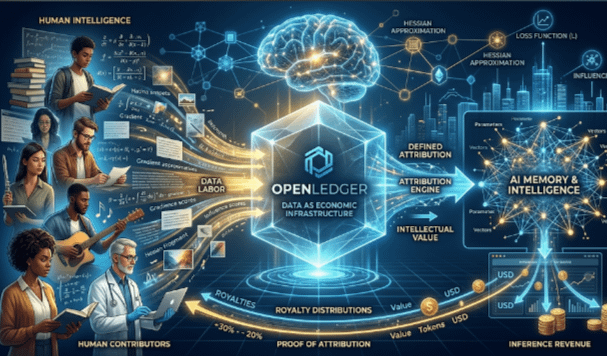
The entire pipeline is economically asymmetric.
The companies operating the models capture most of the value while contributors remain invisible.
What OpenLedger is attempting feels different because it treats data less like disposable fuel and more like economic infrastructure.
That distinction matters.
The project’s Proof of Attribution framework tries to connect AI outputs back to the datasets that materially shaped them. In other words, OpenLedger is building a system where influence becomes measurable instead of assumed.
That sounds abstract at first, but the implications are surprisingly practical.
If AI outputs can be traced to influential data sources, then compensation can also become traceable.
And once compensation becomes traceable, data itself starts behaving like a productive digital asset rather than a passive resource.
Why Attribution Changes the Incentive Structure
One thing I find interesting is that OpenLedger is not rewarding contribution volume alone.
It rewards contribution usefulness.
That changes the psychology of participation completely.
In many decentralized systems, incentives unintentionally encourage spam because quantity becomes easier to measure than quality. Large amounts of low-value content flood the network simply because submissions are rewarded equally.
OpenLedger tries to solve this through influence-based attribution.
Instead of asking: “How much data did you upload?”
the system asks: “How much did your data actually affect the model’s output?”
That is a far more difficult problem technically, but also a much more meaningful one economically.
The influence function in the paper essentially measures how strongly a specific data point affects inference behavior. The model evaluates the relationship between training data, parameter adjustments, and output quality to estimate contribution impact.
From a systems perspective, this is extremely important because it creates a filtering mechanism against low-quality datasets.
Bad or irrelevant data becomes economically inefficient.
Useful data becomes financially valuable.
That sounds obvious, but most AI economies today still fail to distinguish between the two in a transparent way.
The More Interesting Part Is What Happens During Inference
A lot of projects focus heavily on training infrastructure, but OpenLedger’s design becomes more compelling during inference itself.
When a model generates an output, the protocol computes influence scores tied to the contributing data points. Contributors whose data materially shaped the result receive a portion of the inference revenue.
This creates a living economic loop around AI usage.
The model earns. Stakers earn. The platform earns. But contributors also continue earning as their data keeps generating value.
That changes the lifecycle of data entirely.
Normally, datasets are monetized once through acquisition or licensing. After that, contributors are disconnected from downstream value creation.
OpenLedger introduces something closer to ongoing intellectual royalties for AI influence.
I think that idea resonates because people increasingly understand that data is labor, even if the industry rarely frames it that way.
There’s Also a Scalability Challenge Here
To be fair, attribution at scale is not an easy computational problem.
The naive approach requires expensive second-order calculations involving Hessian matrices, which quickly become impractical for real-time systems.
OpenLedger addresses this by using an approximation framework designed for efficient influence computation.
That may sound like a minors implementation detail, but it is actually critical....
A lot of decentralized AI ideas collapse under computational reality. Elegant theory means very little if attribution costs more resources than the inference itself.
So the real test for OpenLedger is not whether attribution sounds philosophically attractive.
It is whether attribution remains economically efficient under large-scale inference demand.
That tension is important to acknowledge because many AI protocols underestimate operational complexity.
The Bigger Shift May Be Psychological
The more I think about this model, the more I feel OpenLedger is indirectly challenging the cultural assumptions behind AI ownership.
Right now the dominant AI narrative revolves around centralized accumulation: larger models, larger datasets, larger compute monopolies.
OpenLedger moves in the opposite direction by asking whether AI systems can become economically participatory instead.
Not just decentralized in governance language, but decentralized in value distribution.
That is a much harder goal.
And honestly, it may not work perfectly.
Attribution systems can become noisy. Influence measurement may never be perfectly precise. Reward models can be gamed. Data markets can still become extractive if incentives are poorly balanced.
But despite those uncertainties, I think the direction itself matters.
Because eventually the AI industry will have to answer an uncomfortable question:
If human-generated data is continuously creating economic value for intelligent systems, should contributors remain permanently disconnected from that value?
OpenLedger appears to be one of the few projects trying to build infrastructure around that question rather than avoiding it.
And whether the protocol succeeds or fails long term, I suspect attribution-based AI economies will become increasingly difficult to ignore.
