
Tôi không còn lạ gì với những narrative AI hứa sẽ giúp chúng ta tiến gần hơn tới “super intelligence” chỉ bằng cách build model mạnh hơn.
Nghe có vẻ đúng, nếu model càng lớn, compute càng mạnh và data càng nhiều thì AI sẽ càng thông minh. Một ý tưởng đơn giản và vì quá đơn giản nó lặp lại hết chu kỳ này đến chu kỳ khác.
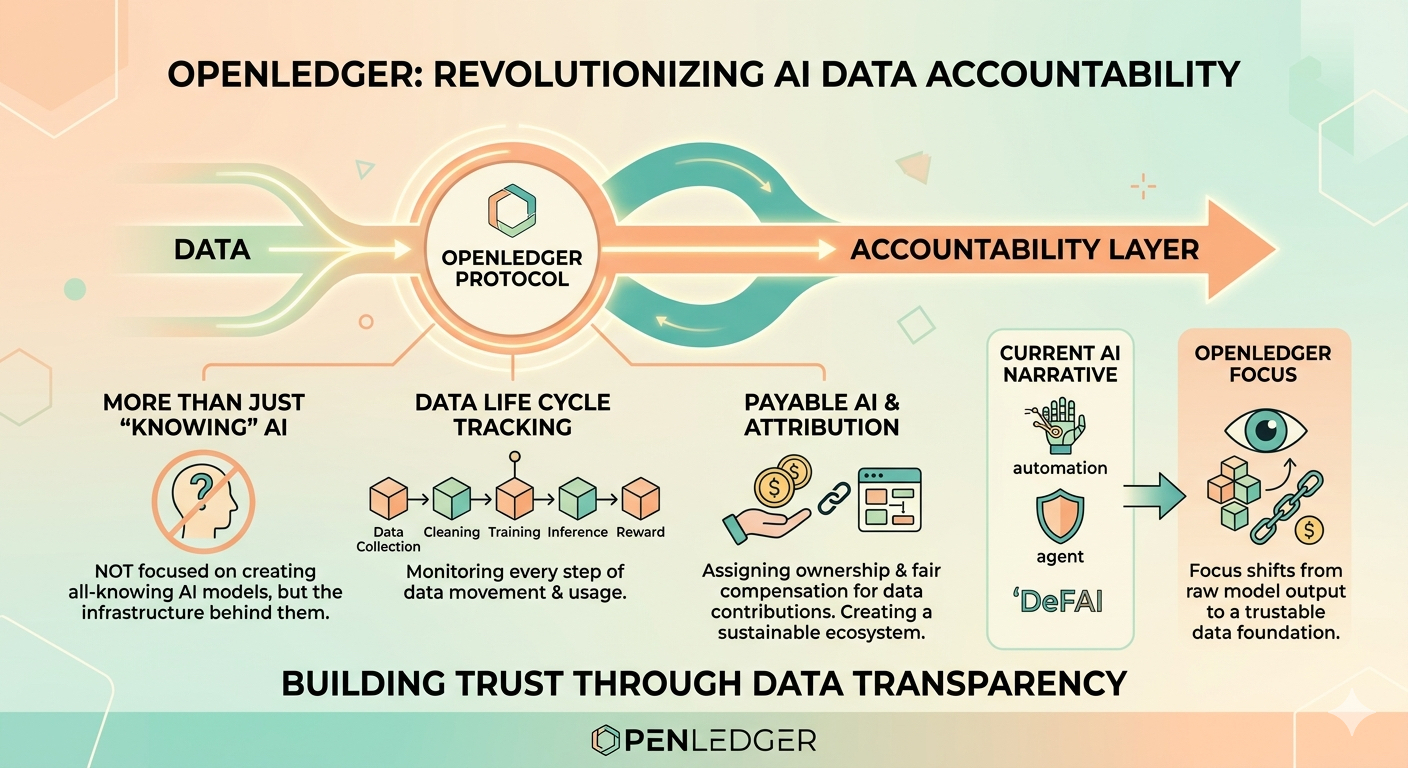
Nhưng AI, ít nhất từ cách tôi nhìn, chưa bao giờ chỉ là bài toán thiếu model mạnh. Nó là bài toán ownership, attribution và economic flow của dữ liệu.
Phần lớn AI projects hiện tại đều đi theo cùng một hướng: build model tốt hơn, inference nhanh hơn, agent tự động hơn hoặc compute mạnh hơn. Điều đó không sai. Nhưng đa số vẫn đang xem dữ liệu như “nguyên liệu đầu vào miễn phí”.
Các mô hình AI hiện tại scrape internet, train trên dữ liệu công khai và biến hàng tỷ hành vi của con người thành intelligence cho model.
Nghe thì đúng, nhưng vấn đề nằm ở chỗ: ai thực sự tạo ra giá trị đó và ai được hưởng lợi từ nó.
Hầu hết thời điểm, dữ liệu của con người chỉ trở thành “raw material” cho AI. Một bài viết đã được đăng, một hình ảnh đã được upload, một cuộc hội thoại đã diễn ra và model hấp thụ tất cả. Có vẻ hiệu quả, nhưng gần như không tồn tại attribution thực sự. Contributor không biết dữ liệu của mình ảnh hưởng thế nào tới output, càng không biết mình có được trả thưởng hay không.
Và rồi có một lớp vấn đề khác. Phần lớn hệ thống hiện tại dường như giả định rằng “dữ liệu là tài nguyên miễn phí”. Nhưng thực tế thì không. Dữ liệu có nguồn gốc, có ownership, có licensing và có economic value.
Hệ thống hiện tại không cho bạn thấy bối cảnh đó. Nó chỉ cho bạn một AI output hoàn chỉnh, không có provenance rõ ràng phía sau.
Rất nhiều người nhìn vào AI race và tin rằng lợi thế sẽ luôn thuộc về model mạnh hơn. Nhưng nếu có, lợi thế đó có thể biến mất rất nhanh. Khi model dần commoditized, thứ tạo khác biệt có thể không còn là architecture nữa, mà là ai sở hữu dữ liệu chất lượng hơn, dữ liệu có verify được không và contributor có được incentive minh bạch không.
Điều tôi luôn quay lại không phải là model mạnh đến đâu, mà là AI economy đang vận hành như thế nào.
OpenLedger, ít nhất từ cách tôi quan sát, không đi theo hướng build “AI biết nhiều hơn” như phần lớn narrative hiện tại. Nó có vẻ đang cố build một thứ khác: accountability layer cho dữ liệu AI.
Không phải chỉ nhìn vào output của model, mà nhìn vào toàn bộ vòng đời của dữ liệu phía sau nó.
Trong khi nhiều AI crypto projects đang tập trung vào agent, automation hoặc DeFAI, OpenLedger lại đẩy mạnh khái niệm “Payable AI” - nơi dữ liệu không chỉ để train model, mà còn phải có attribution và reward flow rõ ràng.
Các hệ thống như OpenLedger không thêm dữ liệu mới theo nghĩa truyền thống. Dữ liệu vẫn là text, image, conversation, behavior. Nhưng cách nó được dùng thì khác.
Nó cố gắng gắn dữ liệu vào một lớp attribution on-chain thông qua thứ họ gọi là “Proof of Attribution” - nơi hệ thống cố xác định dữ liệu nào thực sự ảnh hưởng tới model hoặc output để contributor có thể được ghi nhận và trả thưởng bằng OPEN.
Đây là điểm tôi thấy khác biệt khá lớn.
Phần lớn AI systems hiện tại chỉ quan tâm “output có tốt không”.
OpenLedger lại cố quan tâm thêm:
“Ai đã giúp tạo ra output đó?”
Nghe thì không flashy bằng AI agents hay autonomous systems. Nhưng paradox nằm ở chỗ là AI càng mạnh, vấn đề provenance và ownership có thể càng trở nên quan trọng hơn.
Một model có thể generate ra value hàng tỷ đô, nhưng nếu toàn bộ dữ liệu phía sau không verify được nguồn gốc, không có licensing rõ ràng và contributor không nhận được gì, AI economy đó có thể bắt đầu gặp vấn đề rất lớn về incentive structure.
Narrative AI hiện tại cho bạn cảm giác “AI càng lớn sẽ càng tốt”.
OpenLedger lại đang đặt câu hỏi liệu AI có nên accountable với dữ liệu mà nó dùng hay không.
Nó không trực tiếp làm AI thông minh hơn như cách market thường hype, nhưng cố biến dữ liệu thành một economic asset có provenance, attribution và reward flow rõ ràng hơn.
Dĩ nhiên điều đó không có nghĩa OpenLedger đã giải được bài toán này.
Thực tế, thứ họ đang cố làm còn khó hơn nhiều narrative AI thông thường.
Attribution trong LLM gần như luôn là black-box. Việc xác định chính xác dataset nào ảnh hưởng tới output nào ở quy mô lớn là bài toán cực khó, cả về technical lẫn computational cost.
Đó là lý do đa số projects chọn bỏ qua lớp này và chỉ tập trung vào model performance.
OpenLedger lại chọn đi ngược hướng đó.
Trong khi nhiều AI projects cố cạnh tranh bằng benchmark, TPS hay tốc độ inference, OpenLedger có vẻ đang cố build một infrastructure layer cho provenance và incentive economy của AI.
Có thể nó không hấp dẫn bằng narrative “AI agent thay thế con người”.
Nhưng nếu AI thực sự trở thành nền kinh tế lớn trong tương lai, accountability có thể là thứ không thể thiếu.
Và còn một điều nữa. Khi bạn đưa ownership và incentive vào AI data layer, bạn cũng đang thay đổi vai trò của contributor. Họ không còn chỉ là “người tạo dữ liệu miễn phí”. Họ trở thành một phần của economic system phía sau AI.
Nếu attribution sai, reward distribution cũng sẽ sai - nhưng lần này là sai ở cấp độ incentive economy.
Vì vậy nếu đặt cạnh narrative AI hiện tại, tôi không nhìn OpenLedger như một AI project thông thường.
Một bên tập trung vào model race.
Một bên tập trung vào data accountability.
Một bên cố làm AI thông minh hơn.
Còn một bên cố làm AI economy minh bạch hơn.
Cái nào quan trọng hơn? Tôi nghĩ câu hỏi đó chưa có đáp án rõ ràng. Quan trọng hơn là AI economy trong tương lai thực sự thiếu điều gì.
Nếu thị trường vẫn chỉ quan tâm model và narrative, những thứ như attribution có thể bị bỏ qua. Nhưng nếu AI bước vào giai đoạn cần verify dữ liệu, licensing và reward minh bạch hơn, có lẽ những hệ thống như OpenLedger sẽ đáng để nhìn vào.
Nhưng đáng để nhìn không có nghĩa là đáng để tin.
OpenLedger có thể đang cố giải quyết bài toán accountability cho AI data, trong khi phần lớn thị trường vẫn tập trung vào model race. Sự khác biệt này đáng chú ý, nhưng cũng không phải lời giải cuối cùng.
Vì thực tế, mọi thứ chỉ được kiểm chứng khi dùng. Whitepaper, narrative hay demo không quan trọng bằng việc liệu AI economy có thực sự chuyển sang mô hình attribution và revenue sharing hay không.
Cuối cùng, mọi thứ vẫn quay về usage.
Không phải model benchmark cao đến đâu, không phải narrative AI nghe lớn tới mức nào, mà là liệu contributor có thực sự được ghi nhận và reward khi AI tạo ra value hay không.
Tôi vẫn đang dõi theo diễn biến… đặc biệt là khi AI bắt đầu đối mặt nhiều hơn với vấn đề licensing, provenance và transparency, vì đó là lúc mọi narrative bắt đầu lộ ra giới hạn của nó.
Liệu tương lai AI sẽ thuộc về model mạnh nhất… hay thuộc về hệ thống đầu tiên giải được bài toán ownership và attribution cho dữ liệu?